一、 块设备驱动程序的引入(第十八课/第一节)
总结一下字符设备驱动程序:
1、引入字符设备驱动程序

当应用程序调用 open 时,驱动程序的 drv_open 函数就会被调用。
2、 最简单驱动程序的写法
1. 确定主设备号:可以自己确定,也可让内核分配。
2. 构造驱动中的"open,read,write"等函数,然后放入"file_operation"结构体里。
3. register_chrdev 注册字符设备,把构造的"file_operation"结构放到内核的字符设备中的以主设备号为下标的数组中去。"register_chrdev(主设备号,主设备名,file_operation结构)."
4. 入口函数:调用这个"register_chrdev"函数,内核装载某个模块时,会自动的调用这个入口函数。
5. 出口函数:调用"unregister_chrdev"
3、 我们按键驱动为例写了很多个驱动程序
1. 查询方式:驱动程序提供一个读函数,直接返回某个引脚状态,应用程序会不断的读取,比较前后两次的引脚状态是否有变化。CPU的占用率会很高。
2. 中断方式(休眠唤醒):应用程序使用读函数时进入驱动程序的读函数。在驱动程序里,若没有数据就休眠,若有中断发生就会被唤醒,然后copy_to_user把数据拷贝到用户空间。
3. poll机制:就像定闹钟一样,若时间到了或者有中断发生都会返回
4. 异步通知:以上3种都是应用程序来读,异步通知是驱动程序向应用程序发送信号。
以上4种情况的缺点是这种驱动只有自己知道怎么使用。要写成通用的驱动程序就要看懂内核代码,把自己的代码融合进去。对于按键来说是输入子系统,对于LCD来说就是Framebuffer。
块设备驱动程序
1、硬盘:

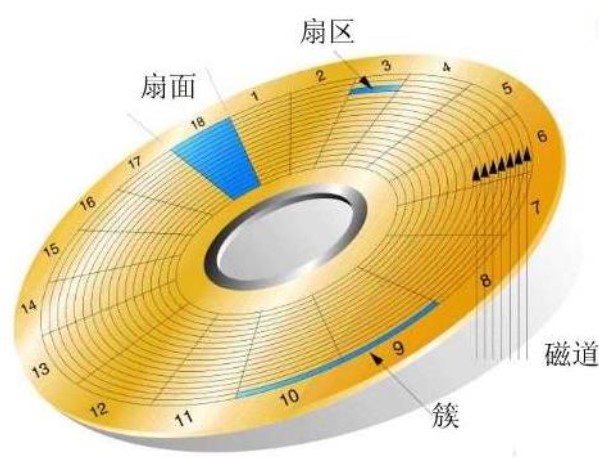
柱面:一环一环的像跑道一样,比如:0号跑道
扇区:一个跑道上一小部分连续的区域,一个跑道可以分为好几个扇区。
磁盘的读写其实非常快,慢在机械结构读写装置的定位上面。
假设现在要读写不同磁头上的扇区
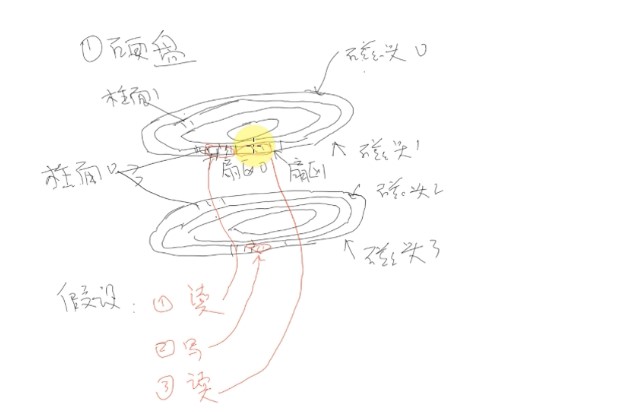
上面的执行过程是:"R0"->"W"->"R1",这个操作跳转了两次。
优化一下:"R0"->"R1"->"W",这样这个操作就只需要跳转一次。
解决思路:先不执行而是放入队列,优化(调整顺序)后在执行。就可以防止读写时在硬盘上跳来跳去降低整体效率。
2、Flash
假设要写扇区0和扇区1
Flash要先擦除然后再写。
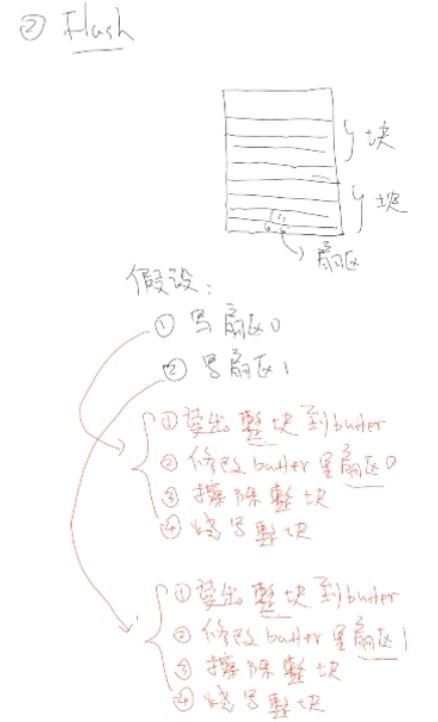
- 读出整块到buffer。
- 修改buffer里的扇区0。
- 擦除Flash的整块。
- 把修改后的buffer烧写到整块。
解决办法:先不执行放入队列,优化(合并)后执行。
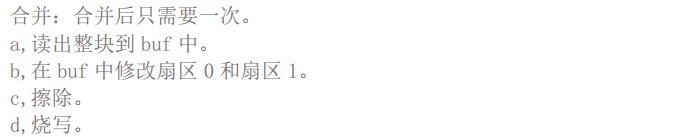
所以,块设备不能像字符设备那样提供读写函数。而是先把读写放入队列,不执行;优化后在执行。
二、 块设备驱动程序的框架(第十八课/第二节)

对普通文件"1.txt"的读写会转换成对块设备的读写,要读写哪个扇区。从文件的读写转换成对扇区的读写,中间会涉及到"文件系统"。
应用程序读写一个普通的文件,最终会转换成操作硬件,由"块设备驱动程序"来操作硬件。
如何知道是"ll_rw_block"(lowlevel底层)可以看《LINUX内核源代码情景分析》。
现在开始从"ll_rw_block"函数开始分析

这个函数的文件在内核源目录下的"fs"目录下,这个"fs"目录下有各式各样的文件系统(文件的组织格式-纯软件的概念。),"fs"目录下还有很多通用的文件,"ll_rw_blokc"这个函数在(buffer.c)是这个"fs"目录下的通用文件。
参数1:表示读或是写;参数2:有nr个参数3"buffer_head"结构的数组项;参数3:数据传输三要素(源、目的、长度)放到"buffer_head"结构的数组中。


进入(submit_bh)函数

构造bio,提交bio
-----------------------------------------------------
进入(submit_bio)函数


-----------------------------------------------------

-----------------------------------------------------
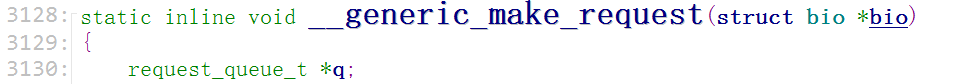
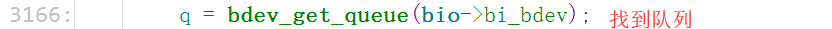

那么这个函数又是在哪儿被设置的呢?搜索一下
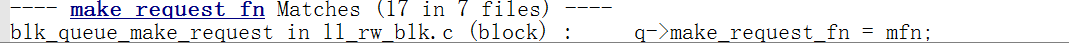
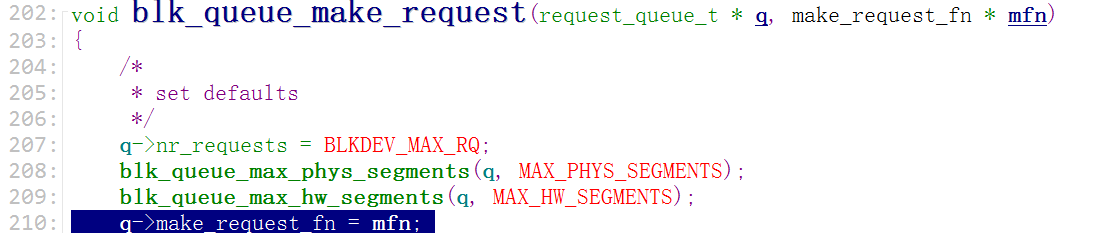
这个(blk_queue_make_request)函数又是在哪儿被调用的呢?搜索一下
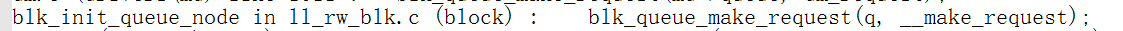

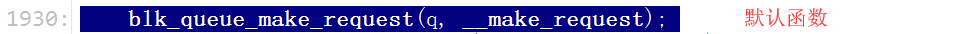
看看这默认的函数(__make_request)做了哪些事情?

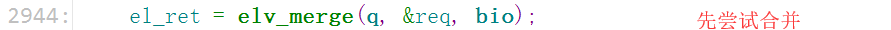



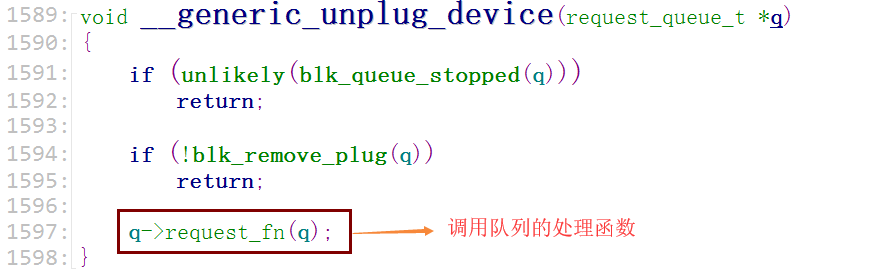
分析框架:

三、 块设备驱动程序的编写驱动之用内存模拟磁盘(第十八课/第三节)
如何写块设备驱动程序?
1. 以面向对象的思想分配一个"gendisk"结构体:使用alloc_disk函数
2. 设置"gendisk"结构体。
2.1 分配/设置一个队列:使用blk_init_queue(提供读写能力)
2.2 设置"gendisk"其它信息。提供属性:比如容量
3. 注册"gendisk"结构体:使用add_disk函数
先看看别人怎么做的,参考(drivers/block/xd.c)和(drivers/block/z2ram.c)。
从"xd.c"的入口函数开始
1. 注册一个块设备
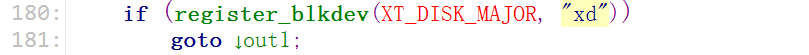

2. 初始化队列

3. 使用队列

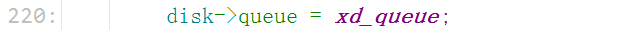
4. add_disk
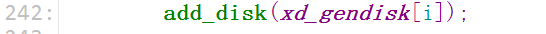
1th、
自己写一个块设备驱动
分配disk结构

分配/设置队列

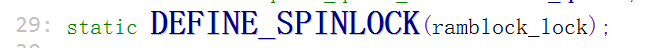
设置disk其它属性


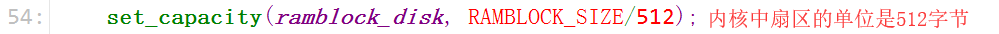
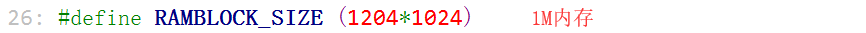
注册

处理请求
在分配/设置队列"blk_init_queue"函数中,形参1是用来处理队列中的请求的函数

出口函数

测试1th:
1. 装载驱动:

装载驱动后马上就调用了"do_ramblock_request"队列请求处理函数,但是到这里就再也没有返回了,因为对reques没有进行任何处理。
2th、 处理无法返回问题
查看一下(xd.c),看看怎么做的
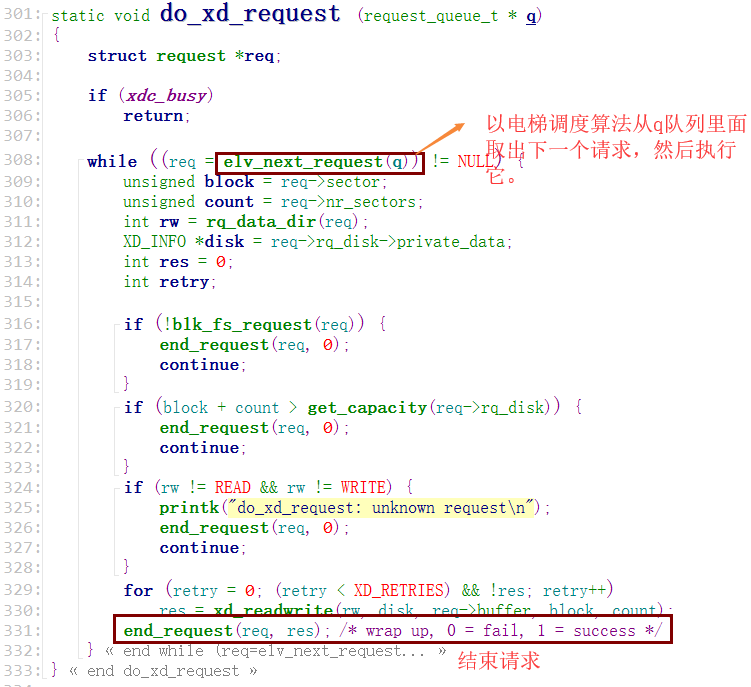
仿造一下
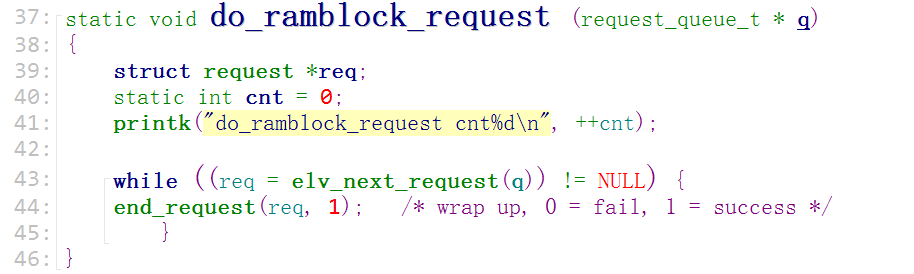
测试2th:
装载驱动
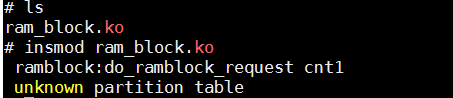
因为什么也没做,所以会不识别分区表
查看一下设备


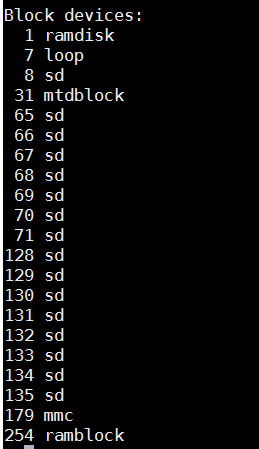
3th、 完善内存模拟磁盘
1. 分配一块内存用来模拟磁盘
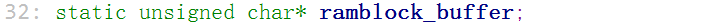
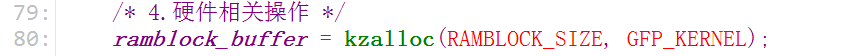
2. 数据传输三要素,块设备数据传输三要素在结构体"request"中定义

块设备操作是以扇区为单位,即使是写一个字节,也是先读出一个扇区,在修改这个扇区里的那个字节后,然后将整个扇区烧进去。

3. 读写的方向
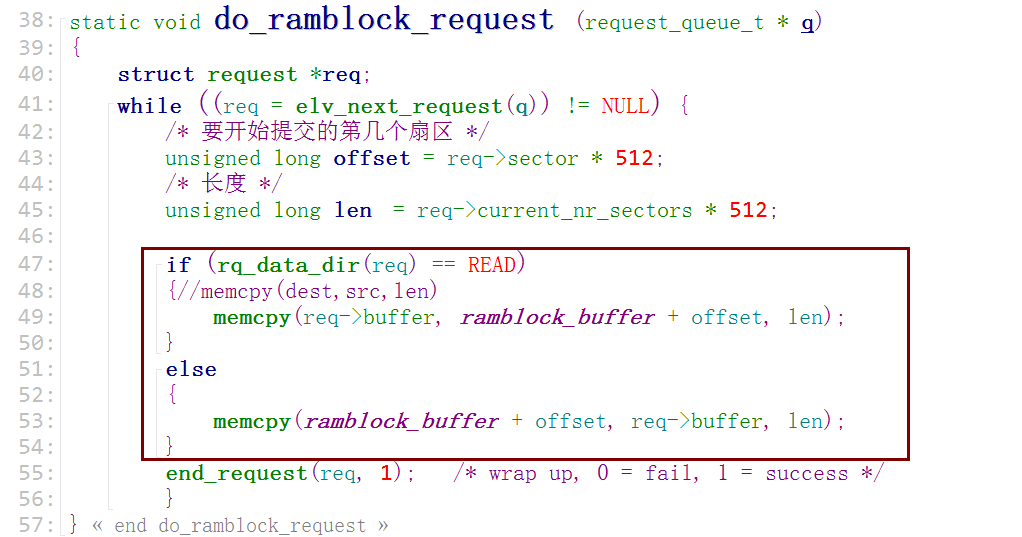
测试3th:
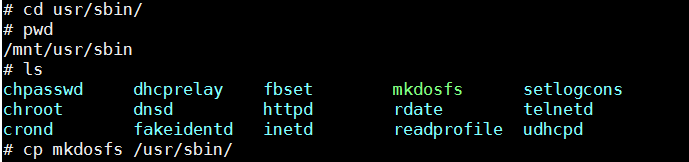
测试时没有mkdosfs工具解决办法:
a. 下载源码包,解压缩,编译

2. 把编译后的mkdosfs拷贝到文件系统的usr/sbin目录


3. 在单板上使用nfs挂接后从挂接目录下拷贝到单板的/usr/sbin下。
开始测试:
1. 加载驱动

还是提示了未识别的分区表,这是因为分配的内存全都被清0了。
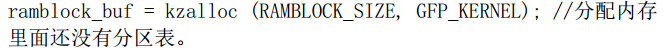
2. 格式化:mkdosfs /dev/ramblock

3. 挂接:mount /dev/ramblock /tmp/ =====>把磁盘挂接到tmp目录下,操作/tmp/目录就等同于操作我们用内存虚拟的磁盘

4. 读写文件:cd /tmp,在里面编辑文件或者拷贝一个文件


5. 跳转到根目录,然后取消挂载

6. 把整个用内存虚拟的磁盘映像覆盖到/mnt/ramblock.bin

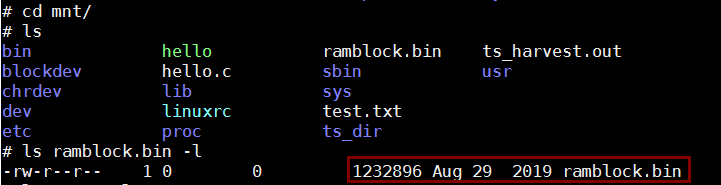
7. 在PC上的first_fs目录下查看ramblock.bin
"-o loop"表示回环设备,可将一个普通文件当成一个块设备文件来挂接。

4th、把队列请求处理函数中读写打印出来
用内存来模拟磁盘,忽略了硬件的复杂操作,这里使用"memcpy"就实现了硬件的操作。
添加打印语句,来查看执行的是读还是写操作
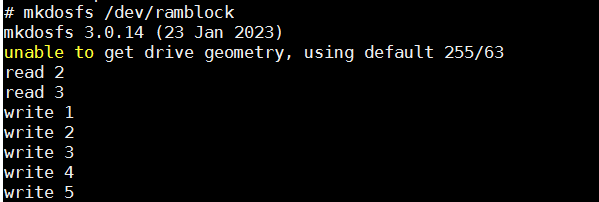
测试4th:
1. 加载驱动

加载驱动时读取了一次
2. 格式化
3. 挂接
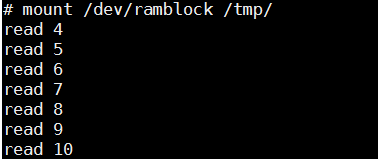
......

4. 拷贝一个文件(cp /etc/inittab /tmp)

可以看到写进去并没有立刻写,而是读。块设备的读写操作会先放到队列里面,并不会立即执行。

等了好一会儿才写进去
有时候在Windows上可以发现拷贝文件到U盘的"进度条"已经完成,这是去点击右下角卸载U盘时,会提示说设备忙,U盘的灯也在狂闪。这是表示后台其实还在写。
再拷贝一个文件(cp /etc/init.d/rcS /tmp)

发现还是没有写
执行sync(同步)就可以立刻写进去,sync是一个系统调用。

再次拷贝文件的时候也不会立刻写,当执行"umount"的时候(取消挂载),就立即开始去写了。
5th、 分区

会提示说不知道"柱面"数。现在很多磁盘已经没有(磁头,柱面)这种结构了,但是为了兼容这些"fdisk"老工具,需要假装说自己有多少个"磁头",多少个"柱面"。这些信息由"block_device_operation"结构中的".getgeo"函数获得几何属性。
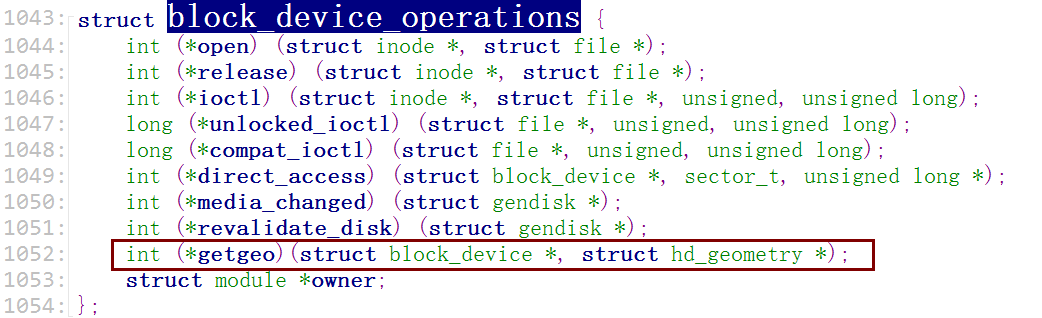
搜索一下".getgeo"看看别人是怎用的

仿照一下别人的写法

容量 = 磁头*柱面*扇区*512
磁头:表示有多少面。这里假设有2面。
柱面:表示有多少环。这里假设有32环。
扇区:表示一环里有多少个扇区。
一个扇区有512字节。
测试5th:
1. 重新加载驱动

2. 查看设备

次设备号为"0",表示整个磁盘,1M的内存
3. 分区

给这个1M的空间分区
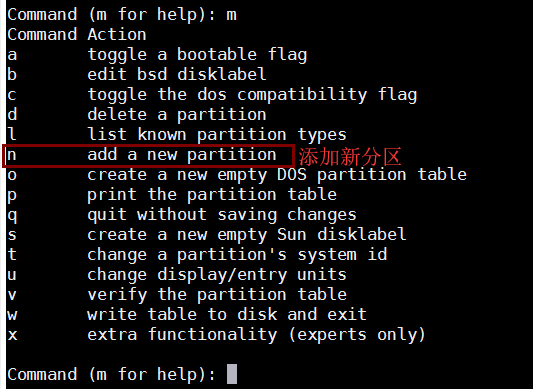
"n"添加一个新分区

设置第几个分区,设置分区大小

查看分区表
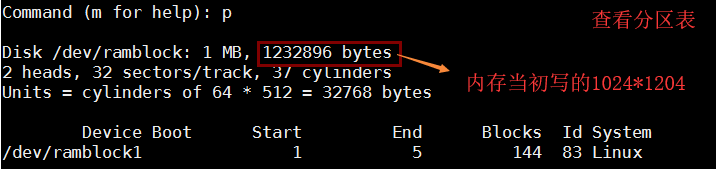
这时看到一个新分区创建出来了,下面再增加一个分区
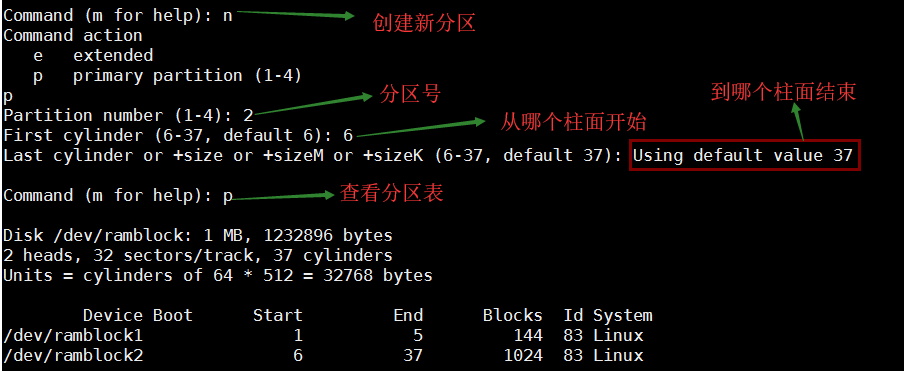
输入"w"才会真正的写入分区表,所谓分区表就是这个磁盘里的第一个扇区
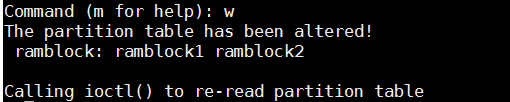
查看设备

可以分别格式化,也可以分别挂接


5th分区程序
/*
* 参考:driverslockxd.c
* driverslockz2ram.c
*/
#include <linux/module.h>
#include <linux/errno.h>
#include <linux/interrupt.h>
#include <linux/mm.h>
#include <linux/fs.h>
#include <linux/kernel.h>
#include <linux/timer.h>
#include <linux/genhd.h>
#include <linux/hdreg.h>
#include <linux/ioport.h>
#include <linux/init.h>
#include <linux/wait.h>
#include <linux/blkdev.h>
#include <linux/blkpg.h>
#include <linux/delay.h>
#include <linux/io.h>
#include <asm/system.h>
#include <asm/uaccess.h>
#include <asm/dma.h>
#define RAMBLOCK_SIZE (1204*1024) //应该是1024*1024,只是内存大小不同
static int major;
static struct gendisk* ramblock_disk;
static request_queue_t* ramblock_queue;
static DEFINE_SPINLOCK(ramblock_lock);
static unsigned char* ramblock_buffer;
static int ramblock_getgeo(struct block_device *bdev, struct hd_geometry *geo)
{
/* 容量 = 磁头 * 柱面 * 扇区 * 512 */
geo->heads = 2;
geo->sectors = 32;
geo->cylinders = RAMBLOCK_SIZE/2/32/512;
return 0;
}
static struct block_device_operations ramblock_fops = {
.owner = THIS_MODULE,
.getgeo = ramblock_getgeo,
};
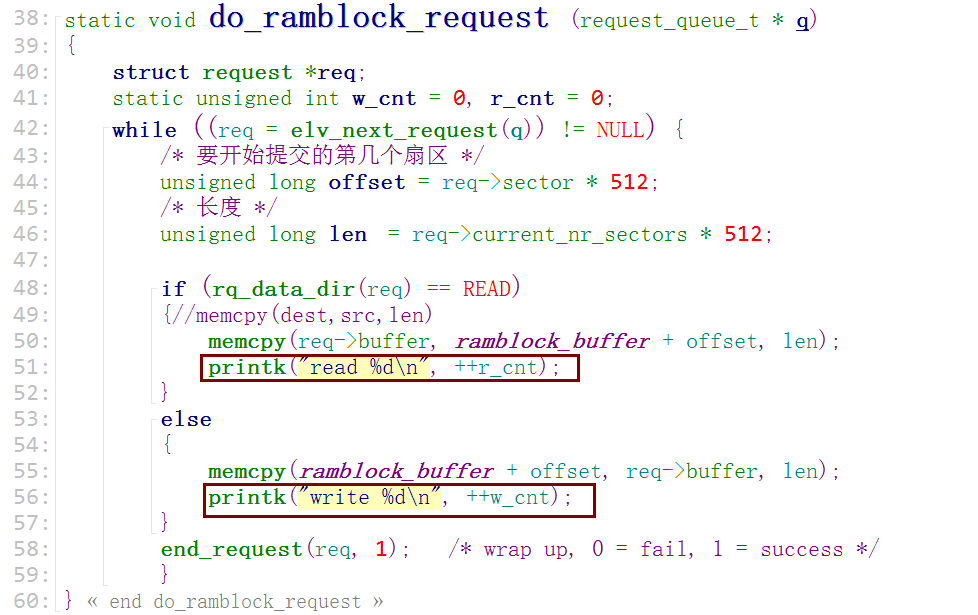
static void do_ramblock_request (request_queue_t * q)
{
struct request *req;
//static unsigned int w_cnt = 0, r_cnt = 0;
while ((req = elv_next_request(q)) != NULL) {
/* 要开始提交的第几个扇区 */
unsigned long offset = req->sector * 512;
/* 长度 */
unsigned long len = req->current_nr_sectors * 512;
if (rq_data_dir(req) == READ)
{//memcpy(dest,src,len)
memcpy(req->buffer, ramblock_buffer + offset, len);
//printk("read %d
", ++r_cnt);
}
else
{
memcpy(ramblock_buffer + offset, req->buffer, len);
//printk("write %d
", ++w_cnt);
}
end_request(req, 1); /* wrap up, 0 = fail, 1 = success */
}
}
static int ram_block_init(void)
{
/* 1. 分配一个disk结构 */
/* 分配的次设备号个数,16表示组多能创建15个分区,其中次设备号为0表示整个磁盘。 */
/* 如果不想分区,写为1就可以了 */
ramblock_disk = alloc_disk(16);
/* 2. 设置 */
/* 2.1 分配/设置队列 */
ramblock_queue = blk_init_queue(do_ramblock_request, &ramblock_lock);
ramblock_disk->queue = ramblock_queue;
/* 2.2 设置其它属性:比如容量 */
major = register_blkdev(0, "ramblock");
ramblock_disk->major = major;
ramblock_disk->first_minor = 0;
sprintf(ramblock_disk->disk_name, "ramblock");
ramblock_disk->fops = &ramblock_fops;
set_capacity(ramblock_disk, RAMBLOCK_SIZE/512);
/* 4.硬件相关操作 */
ramblock_buffer = kzalloc(RAMBLOCK_SIZE, GFP_KERNEL);
/* 3.注册 */
add_disk(ramblock_disk);
return 0;
}
static void ram_block_exit(void)
{
put_disk(ramblock_disk);
blk_cleanup_queue(ramblock_queue);
unregister_blkdev(major, "ramblock");
del_gendisk(ramblock_disk);
kfree(ramblock_buffer);
}
module_init(ram_block_init);
module_exit(ram_block_exit);
MODULE_LICENSE("GPL");
个人总结:
格式化、读写文件等都是由"文件系统"这一层将文件的读写转换成对扇区的读写。调用"ll_rw_block"会把读写放到你的队列中去。会调用你的"队列请求函数"来处理。只要写好"队列请求函数"即可。
一旦使用读写文件等操作就会被文件系统拆分成对不同扇区的一个一个读写请求然后加入队列,在队列会调用电梯调度算法,最终就会调用"do_request"函数,在函数里面从队列里取出一个请求以实现对硬件的读写操作。
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">