案例:通过使用R语言的聚类算法将用户进行合理的划分,找出对超市贡献度,光临度最高的优质客户,对后期的推广有更深远的影响
1.导入包
library(dplyr)
library(reshape2)
library(cluster)
library(fpc)
library(mclust)
2.加载数据集
options(digits = 18) #小数可以显示到第18位 lss_all_cust_ls_info <- read.table('E:\Udacity\Data Analysis High\R\R_Study\高级课程代码\数据集\第一天\1顾客细分\lss_all_cust_ls_info.txt',header=T,sep=' ') head(lss_all_cust_ls_info) lss_cust_payment <- read.table('E:\Udacity\Data Analysis High\R\R_Study\高级课程代码\数据集\第一天\1顾客细分\lss_cust_payment.txt',header=T,sep=' ') head(lss_cust_payment) lss_cust_spend_info <- read.table('E:\Udacity\Data Analysis High\R\R_Study\高级课程代码\数据集\第一天\1顾客细分\lss_cust_spend_info.txt',header=T,sep=' ') head(lss_cust_spend_info)
3.查看数据集
#客户信息 head(lss_all_cust_ls_info) str(lss_all_cust_ls_info) summary(lss_all_cust_ls_info) #支付信息 head(lss_cust_payment) str(lss_cust_payment) summary(lss_cust_payment) #商品信息 head(lss_cust_spend_info) str(lss_cust_spend_info) summary(lss_cust_spend_info)
4.数据集预处理(将三个数据集合并成一个数据集,通过cust_id进行关联)
data_cat_wide = dcast(lss_cust_spend_info,cust_id~ls_category,value.var = "ls_spd_share") head(data_cat_wide) names(data_cat_wide) data_cat_wide = data_cat_wide[,-2] #dim(data_cat_wide) #summary(data_cat_wide) data_payment_wide = dcast(lss_cust_payment,cust_id~payment_category_desc,value.var = "payment_amount_share") head(data_payment_wide) #dim(data_payment_wide) ### 3. join data ##把三张表进行合并,通过cust_id来进行列合并 cust_all = merge(lss_all_cust_ls_info,data_payment_wide, by="cust_id") cust_all_fnl = merge(cust_all,data_cat_wide, by="cust_id") ## 查看合并后的结果 head(cust_all_fnl,10) dim(cust_all_fnl) summary(cust_all_fnl)

结论:将所有的纵向表转换成横向表,同时把所有数据集的所有字段汇总到一张表
5.数据清洗
## 提取出客户ID和性别 cust_id = cust_all_fnl[,1] cust_sex = cust_all_fnl[,2] ## 去除客户ID和性别,同时将除了这两个列之外的缺失值填充0 cust_all_fnl2 = cust_all_fnl[,-c(1,2)] cust_all_fnl2[is.na(cust_all_fnl2)] =0 ## 把性别缺失值变成1.5 cust_sex [is.na(cust_sex )] =1.5 ##把处理后的数据合并 cust_all_fnl = data.frame(cust_id,cust_sex,cust_all_fnl2) head(cust_all_fnl) #summary(cust_all_fnl) ## 对于异常值进行处理,如果百分比小于0,则变成0,如果百分比大于1 则等于1 dim(cust_all_fnl) for(i in 7:dim(cust_all_fnl)[2]) { cust_all_fnl[,i][cust_all_fnl[,i]<0] = 0 cust_all_fnl[,i][cust_all_fnl[,i]>1] = 1 } dim(cust_all_fnl) ## 去除礼品字段,因为0值较多,会给后期的聚类操作带来影响 mydata = cust_all_fnl[,-28] dim(mydata) summary(mydata)

结论:生成一张所有属性的统计值,查看是否还有NA的值
6.选择K值
# 如果数据集中的变量过多,要先使用主成分分析找到影响因子在95%以上的列即可
# 选择K使得差异最小,下降幅度最小 comp = scale(mydata[,-1]) wss <- (nrow(comp)-1)*sum(apply(comp,2,var)) for (i in 2:15) wss[i] <- sum(kmeans(comp,centers=i)$withinss) plot(1:15, wss, type="b", xlab="Number of Clusters",ylab="Within groups sum of squares")
7.使用K-media找到中心点的坐标
# 如果数据量较大,首先应对数据进行抽样,然后在找中心点 s = sample(1:dim(mydata)[1],2000,replace = F) clus = 4 medk = pam(scale(mydata[s,-1]),clus,trace=T) plotcluster(scale(mydata[s,-1]),medk$clustering) table(medk$clustering) Kcenter = medk$medoids

8.使用K-mean进行聚类
# 每次抽取1000个点进行聚类 k = kmeans(scale(mydata[,-1]),centers = Kcenter,nstart = 25,iter.max = 1000) plotcluster(scale(mydata),k$cluster)
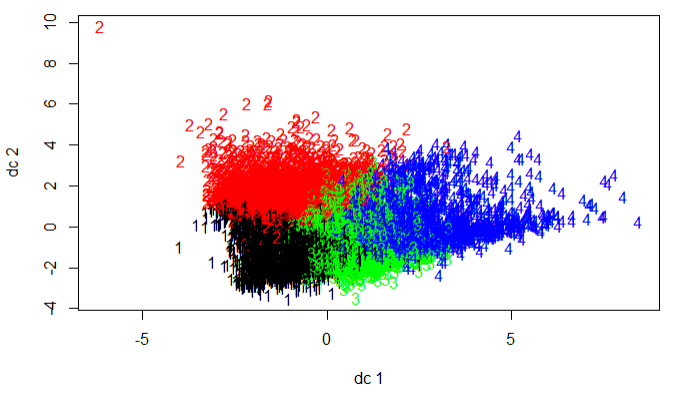
结论:k-means的好处是速度快,但是中心点不稳定,k-media的好处是中心点稳定但是速度慢,此案例结合两者,先通过抽样的方式找出中心点,再将中心点带入到k-means中,即可得到聚类的样本
9.生成结果
# 对每个变量求均值 mydata_mean_sd = aggregate(scale(mydata),by=list(k$cluster),FUN=mean) head(mydata_mean_sd)
10.输出到本地
# 写入到csv文件 write.csv(mydata_mean_sd,'E:\Udacity\Data Analysis High\R\R_Study\高级课程代码\数据集\第一天\1顾客细分\mydata_mean_sd.csv') # 写入数据库 data_sql <- data.frame(mydata, cluster=k$cluster) data_sql_out = data_sql[,c(1,dim(data_sql)[2])]
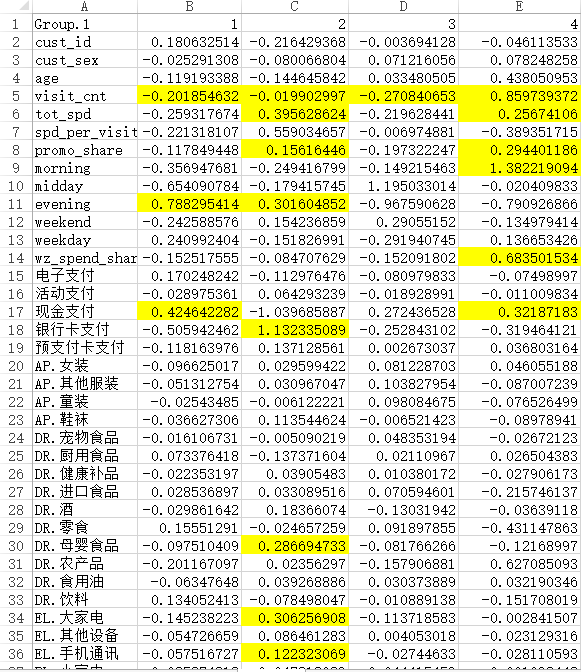

结论:通过生成的csv文件,我们可以得出如下结论:
通过tot_spend可以得出2,4组的顾客对超市的贡献度较大,其中2类客户是最应该保留的优质客户
通过promo_share可以得出4类客户对折扣较为敏感
通过wz_spend_share可以得出4类用户最喜欢参与打5折的活动
通过对比购物时间段来看1,2类用户喜欢晚上购物,3类用户喜欢下午的时候购物,4类用户喜欢早上购物
通过对比支付方式1,3,4组大部分是现金支付,2组客户喜欢用银行卡支付
通过对比消费商品可得出结论:
2类客户喜欢购买大家电,手机通讯设备,母婴食品的高价格产品
4类客户喜欢购买生鲜,蔬菜等农产品
1类客户喜欢购买一些零食,饮料之类的商品
3类客户是散客,会不定期的购买一些商品
针对1类客户,在下午的时间段可以对零食,饮料进行一些促销和活动
针对2类客户,在晚上的时间段,一些大商品的家电,手机等高价格的产品做一些捆绑销售,同时定期去推送一些新的手机,电器,母婴食品的信息,会有不错的销售业绩
针对4类客户,在早上对农产品,生鲜,肉类等商品可以进行一些打折,买一赠一的,兑换券等活动,提升生鲜商品的业绩
针对3类用户,不是超市的重点客户,暂时不知道如何提升到店率
数据集:https://github.com/Mounment/R-Project