郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Preprint. Under review.
Abstract
了解如何通过大脑神经网络中的突触可塑性实现one-shot学习是一个主要的开放性问题。我们提出,在诸如e-prop之类的脉冲神经元循环网络(RSNN)中对BPTT的近似无法实现这一点,因为它们的局部突触可塑性是由学习信号控制的(从生物学的角度来看,这是相当临时的):网络输出瞬间产生的损失的随机预测,类似于前馈网络的广播对齐。相比之下,突触可塑性在大脑中是通过学习多巴胺等信号来控制的,这些信号是由专门的大脑区域发出的,例如VTA。这些大脑区域可以说是通过进化优化了突触可塑性,从而能够快速学习与生存相关的任务。我们发现一个相应的模型架构,其中学习信号由单独的RSNN发出,该架构经过优化以促进快速学习,通过RSNN中的局部突触可塑性实现one-shot学习,用于一大类学习任务。相同的学习方法还支持潜在输入源的后验概率的基于脉冲的快速学习,从而为RSNN中的概率推理提供新的基础。我们的新学习方法还解决了神经形态工程中的一个开放问题,即基于脉冲的神经形态设备非常需要片上one-shot学习能力,但目前还无法实现。我们的方法可以很容易地映射到神经形态硬件,从而解决这个问题。
Introduction
训练循环神经网络的最强大方法依赖于基于梯度的损失函数 E 优化以获得性能良好的网络参数集 W。计算梯度dE/dW的典型方法是应用时间反向传播(BPTT) (Werbos, 1990)。然而,人们普遍认为大脑不会使用BPTT进行学习(Lillicrap and Santoro, 2019)。最近提出的BPTT替代方案,例如用于RSNN的e-prop (Bellec et al., 2019)和用于没有慢速过程的人工神经元的RFLO (Murray, 2019)侧重于两种类型的变量,这些变量似乎是在大脑中实现学习的基础:
- 神经元和突触保持着近期活动的迹,众所周知,如果紧跟自上而下的学习信号,它们会诱导突触可塑性(Yagishita et al., 2014; Gerstner et al., 2018)。这样的迹通常被称为资格迹。我们将
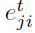 表示为在时间 t 从神经元 i 到神经元 j 的突触的资格迹的值。
表示为在时间 t 从神经元 i 到神经元 j 的突触的资格迹的值。 - 大脑中存在大量自上而下的学习信号,既有神经调节剂的形式,也有发放活动的形式(Sajad et al., 2019),其中一些已知针对不同的目标神经元群体,并传输大量与学习相关的方面(Roeper, 2013; Engelhard et al., 2019)。我们用
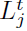 表示在时间 t 到神经元 j 的学习信号。
表示在时间 t 到神经元 j 的学习信号。
根据Bellec et al. (2019)的说法,可以表示RSNN中网络梯度下降的理想权重变化为:
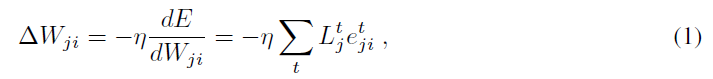
产生时间步骤 t 的在线突触可塑性规则![]() 。资格迹
。资格迹![]() (更多细节在后面给出)与损失函数 E 无关,只取决于突触前和突触后神经元的激活历史。用于实现梯度下降的学习信号
(更多细节在后面给出)与损失函数 E 无关,只取决于突触前和突触后神经元的激活历史。用于实现梯度下降的学习信号![]() 的理想值是总导数
的理想值是总导数![]() ,其中
,其中![]() 是一个二值变量,如果神经元 j 在时间 t 出现脉冲,则假定值为1,否则值为0。但是这个学习信号通常在时间 t 不可用,因为它通常还取决于时间 t 的脉冲对通过未来神经元输出的损失函数 E 值的影响。在随机e-prop中,它被网络输出中当前出现的损失的随机预测所取代,例如前馈网络的广播对齐(Lillicrap et al., 2016; Nøkland, 2016)。这种对BPTT的近似通常效果很好,但与BPTT一样,它通常需要大量的训练示例。我们为e-prop提出了一种更像大脑的学习信号,其中一个单独的优化后的RSNN发出学习信号。我们发现这种更自然的设置,我们称之为自然e-prop,实际上可以实现one-shot学习。我们还发现它可以实现基于脉冲的后验概率学习,从而为RSNN中类脑概率计算建模提供了新的基础。
是一个二值变量,如果神经元 j 在时间 t 出现脉冲,则假定值为1,否则值为0。但是这个学习信号通常在时间 t 不可用,因为它通常还取决于时间 t 的脉冲对通过未来神经元输出的损失函数 E 值的影响。在随机e-prop中,它被网络输出中当前出现的损失的随机预测所取代,例如前馈网络的广播对齐(Lillicrap et al., 2016; Nøkland, 2016)。这种对BPTT的近似通常效果很好,但与BPTT一样,它通常需要大量的训练示例。我们为e-prop提出了一种更像大脑的学习信号,其中一个单独的优化后的RSNN发出学习信号。我们发现这种更自然的设置,我们称之为自然e-prop,实际上可以实现one-shot学习。我们还发现它可以实现基于脉冲的后验概率学习,从而为RSNN中类脑概率计算建模提供了新的基础。
Architectures 我们的目标是提供原则上可以在大脑神经网络的详细模型上实现的学习范式。我们在此关注脉冲神经元的简单标准模型,更准确地说是LIF神经元以及我们称为ALIF神经元的脉冲频率适应(SFA)变体。LIF神经元的隐藏变量是它的膜电位,它是来自突触前神经元的脉冲序列的低通滤波版本的加权和——其权重是突触权重。ALIF神经元(相当于Teeter et al. (2018); Allen Institute: Cell Types Database (2018)的GLIF2模型)将自适应发放阈值作为第二个隐藏变量。它随着神经元的每个脉冲而增加,并以一个时间常数衰减回基准,根据生物学数据,该时间常数通常在几秒钟的范围内(Pozzorini et al., 2013, 2015)。我们在图2和图3的RSNN中包含ALIF神经元,因为这些神经元的存在增强了RSNN的时间计算能力(Bellec et al., 2018; Salaj et al., 2020),并且因为根据Allen Institute的数据库(Allen Institute: Cell Types Database (2018)),新皮质中锥体细胞的20-40%百分比表现出SFA。为简单起见,我们使用了全连接的RSNN,但使用更稀疏连接的网络也可以获得类似的结果。我们使用这些RSNN对我们的学习架构的学习网络(LN)和学习信号生成器(LSG)进行建模,见图1A。使用加权和将RSNN的外部输入整合到神经元的膜电位中。LN的输出("读数")由来自LN中神经元的低通滤波脉冲序列的加权总和组成,以定性方式模拟LN中脉冲对下游神经元膜电位的影响。它们的时间常数被称为读出时间常数,它们在任意选择的时间点 t 对读出值的影响由图1D, 2C, 3C中的黄色阴影表示。重要的是,这些时间常数被选择得相对较短,以迫使网络执行基于脉冲而不是基于发放率的计算。以1 ms的步长进行模拟。补充资料中提供了完整的细节。
Algorithms 自然e-prop的学习分两个阶段进行。在第一阶段,对应于先前的进化和发展优化以及在某种程度上也是先前的学习,我们应用了标准的学习到学习(L2L)或元学习范式(图1B)。人们认为有一个非常大的——通常是无限大的——F 族可能相关的学习任务C。LN从 F 学习特定任务 C 是通过等式(1)在L2L的内部循环中进行的,使用学习信号![]() 由LSG提供。它在第一阶段嵌入到外部循环中,其中与LSG相关的突触权重(参见图1A中的黑色弧线)以及LN的初始权重Winit通过BPTT进行了优化。
由LSG提供。它在第一阶段嵌入到外部循环中,其中与LSG相关的突触权重(参见图1A中的黑色弧线)以及LN的初始权重Winit通过BPTT进行了优化。
具体来说,每次LN首次遇到来自 F 族的新任务 C 时,它都会从突触权重Winit开始,并根据(1)更新这些权重。LN在任务 C 上的学习性能通过一些损失函数EC(y1, ... , yT)进行评估,其中yt表示LN在时间 t 的输出,T 是网络在任务 C 上花费的总持续时间。然后,我们最小化从 F 族随机抽取的许多任务实例 C 上的损失EC。外循环中的这种优化是通过BPTT实现的,如(Bellec et al., 2018)。除了特定应用中描述的损失函数之外,我们还使用了正则化项,目的是将RSNN引入稀疏发放机制。以前用于在内循环中学习的L2L应用要么反向传播(Andrychowicz et al., 2016; Finn et al., 2017),要么根本没有突触可塑性(Hochreiter et al., 2001; Wang et al., 2018; Bellec et al., 2018)。
在第一阶段的学习之后,由外循环调节的所有参数都保持固定,并针对从 F 中随机抽取的新任务 C 评估LN的学习性能。该性能在图1E, 2D, 3D中进行评估,作为阶段1期间外循环的先前迭代次数的函数。
除了自然e-prop之外,我们还测试了简化版本的性能,称为受限自然e-prop。与随机e-prop一样,它不使用LSG,学习信号是LN输出处瞬时产生的损失的加权和。但与随机e-prop相比,这些误差广播的权重——以及LN的初始权重——不是随机选择的,而是在L2L的外循环中优化的,该外循环对应于自然e-prop的外循环。
(1)中的资格迹![]() 反映了权重Wji对 t 时刻神经元 j 发放的影响,但只需要考虑不涉及除 i 和 j 之外的其他神经元的依赖关系。对于标准LIF神经元的情况,它只是来自突触前神经元 i 的脉冲序列的低通滤波版本直到时间t - 1和一个依赖于突触后神经元 j 膜去极化的项的乘积在时间 t (伪导数)。对于ALIF神经元,资格迹变得有点复杂,因为它也涉及神经元依赖于使用的发放阈值的时间演变。更准确地说,如果
反映了权重Wji对 t 时刻神经元 j 发放的影响,但只需要考虑不涉及除 i 和 j 之外的其他神经元的依赖关系。对于标准LIF神经元的情况,它只是来自突触前神经元 i 的脉冲序列的低通滤波版本直到时间t - 1和一个依赖于突触后神经元 j 膜去极化的项的乘积在时间 t (伪导数)。对于ALIF神经元,资格迹变得有点复杂,因为它也涉及神经元依赖于使用的发放阈值的时间演变。更准确地说,如果![]() 表示神经元 j 的内部状态向量,即LIF神经元中的膜电压以及ALIF神经元中发放阈值的动态状态,则资格迹定义为
表示神经元 j 的内部状态向量,即LIF神经元中的膜电压以及ALIF神经元中发放阈值的动态状态,则资格迹定义为![]() 。数量
。数量![]() 是一个所谓的资格向量,递归地定义为:
是一个所谓的资格向量,递归地定义为:![]() ,因此,根据突触后神经元的动态,及时传播"资格"。请注意,
,因此,根据突触后神经元的动态,及时传播"资格"。请注意,![]() 通常不是为脉冲神经元定义的,因此被替换为"伪导数",类似于(Bellec et al., 2018)。根据(Bellec et al., 2019),这些规范资格迹与实验观察到的那些(Yagishita et al., 2014)和在先前的突触可塑性模型中使用的那些(Gerstner et al., 2018)相似。它们可以通过之前的pre-before-post发放事件的渐隐记忆来近似。Suppl.中给出了学习算法、正则化以及所使用的超参数值的完整细节。
通常不是为脉冲神经元定义的,因此被替换为"伪导数",类似于(Bellec et al., 2018)。根据(Bellec et al., 2019),这些规范资格迹与实验观察到的那些(Yagishita et al., 2014)和在先前的突触可塑性模型中使用的那些(Gerstner et al., 2018)相似。它们可以通过之前的pre-before-post发放事件的渐隐记忆来近似。Suppl.中给出了学习算法、正则化以及所使用的超参数值的完整细节。

图1:使用自然e-prop进行新型手臂运动的one-shot学习 A) 自然e-prop的通用架构。在这种情况下,LN输入 xt 由类似时钟的信号组成,输出 yt 是手臂两个关节的速度![]() 。除了 xt 的副本之外,LSG还接收LN的活动 zt 和目标运动 X*, t 作为在线网络输入。B) Hochreiter et al. (2001)的L2L方案,但这里使用的内环具有突触可塑性。C) 运动样本 Xt, t = 1, ... , 500 ms,手臂末端执行器。D) 新手臂运动 X*, t 的one-shot学习演示,t = 1, ... , 500 ms:左侧显示单个学习试验。在这次单一试验之后,LN的突触权重根据自然e-prop进行了更新。在此权重更新后LN产生的手臂运动 Xt 显示在右列中。脉冲光栅图显示神经元的子集。E) D 中右侧显示的测试试验中目标运动 X*, t 和 Xt 之间的MSE作为外循环中训练时间的函数(使用不同初始权重的4次运行获得的均值和标准差(STD))。F) 优化后的LSG生成的学习信号与BPTT在运动学模型知识下使用的"理想学习信号"有很大不同。
。除了 xt 的副本之外,LSG还接收LN的活动 zt 和目标运动 X*, t 作为在线网络输入。B) Hochreiter et al. (2001)的L2L方案,但这里使用的内环具有突触可塑性。C) 运动样本 Xt, t = 1, ... , 500 ms,手臂末端执行器。D) 新手臂运动 X*, t 的one-shot学习演示,t = 1, ... , 500 ms:左侧显示单个学习试验。在这次单一试验之后,LN的突触权重根据自然e-prop进行了更新。在此权重更新后LN产生的手臂运动 Xt 显示在右列中。脉冲光栅图显示神经元的子集。E) D 中右侧显示的测试试验中目标运动 X*, t 和 Xt 之间的MSE作为外循环中训练时间的函数(使用不同初始权重的4次运行获得的均值和标准差(STD))。F) 优化后的LSG生成的学习信号与BPTT在运动学模型知识下使用的"理想学习信号"有很大不同。
Application 1: One-shot learning of new arm movements
Brea and Gerstner (2016)认为one-shot学习是大脑的两种真正重要的学习能力之一,但目前的计算神经科学模型还没有令人满意地解释这些能力。我们证明自然e-prop支持在两种截然不同的环境中进行one-shot学习。我们首先考虑一个通用的运动控制任务,其中2关节臂的末端执行器必须跟踪以欧氏坐标(x, y)给出的目标轨迹,见图1C。我们在图1D和E中显示,RSNN可以使用自然e-prop方法one-shot学习此任务。
为了在L2L的外循环中执行LSG的优化,我们考虑了整个系列 F 的任务 C。在每个任务中,RSNN需要学习重现特定的随机生成的目标运动 X*, t 手臂末端执行器的实际运动 Xt。学习任务分为两个试验,一个训练和一个测试试验,都从相同的初始状态开始。在训练试验期间,LSG显示了欧氏坐标中的目标运动X*, t,并且LSG根据X*, t 和LN的脉冲活动计算了LN的学习信号![]() 。在这次试验之后,根据(1)的累积权重更新应用于LN的突触。在随后的测试试验中,有人测试了LN是否能够在突触可塑性关闭的情况下重现先前演示的手臂末端执行器的目标运动——无需再次接收目标轨迹X*, t。
。在这次试验之后,根据(1)的累积权重更新应用于LN的突触。在随后的测试试验中,有人测试了LN是否能够在突触可塑性关闭的情况下重现先前演示的手臂末端执行器的目标运动——无需再次接收目标轨迹X*, t。
Implementation 持续时间为500毫秒的可行目标运动 X*, t 是通过将随机采样的目标角速度![]() (随机正弦的总和)应用于运动臂模型而产生的。手臂的每个连杆的长度为0.5。LN由400个LIF神经元组成。它的输入 xt 在所有试验中都是相同的,并且由类似时钟的输入信号给出:每100毫秒,另一组2个输入神经元开始以100 Hz的频率发放。LN的输出(读取时间常数为20毫秒)以关节角速度的形式
(随机正弦的总和)应用于运动臂模型而产生的。手臂的每个连杆的长度为0.5。LN由400个LIF神经元组成。它的输入 xt 在所有试验中都是相同的,并且由类似时钟的输入信号给出:每100毫秒,另一组2个输入神经元开始以100 Hz的频率发放。LN的输出(读取时间常数为20毫秒)以关节角速度的形式![]() 产生运动命令。LSG由300个LIF神经元组成。LSG的在线输入包括 xt 的副本、LN的活动 zt 和欧氏坐标中的目标运动 X*, t。LSG无法访问由生成的电机命令导致的误差。对于外环优化,我们将BPTT应用于
产生运动命令。LSG由300个LIF神经元组成。LSG的在线输入包括 xt 的副本、LN的活动 zt 和欧氏坐标中的目标运动 X*, t。LSG无法访问由生成的电机命令导致的误差。对于外环优化,我们将BPTT应用于![]() 。请注意,Xt 在我们的运动学模型中是可微的。为了与图1F中的BPTT进行比较,我们将"理想学习信号"计算为
。请注意,Xt 在我们的运动学模型中是可微的。为了与图1F中的BPTT进行比较,我们将"理想学习信号"计算为![]() ,并使用BPTT在训练试验的误差上进行计算。对于受限制的自然e-prop(见图1E),我们将"网络输出瞬时产生的误差"定义为欧氏坐标中的差值X*, t - Xt。见Suppl.了解完整的实现细节。
,并使用BPTT在训练试验的误差上进行计算。对于受限制的自然e-prop(见图1E),我们将"网络输出瞬时产生的误差"定义为欧氏坐标中的差值X*, t - Xt。见Suppl.了解完整的实现细节。
Results 我们测试了自然e-prop对随机目标运动的性能(图1D中的虚线),并分别在左侧和右侧栏中将LN在训练和测试试验期间产生的轨迹 Xt 显示为实线。在训练试验期间LSG向LN发送学习信号并在LN中产生权重更新后,LN可以使用生物学合理的稀疏发放活动(< 20 Hz)准确地再现目标运动。
图1E总结了测试试验中目标 X*, t 和实际运动 Xt 之间的均方误差。该误差在外循环优化的不同迭代中报告,并且随着RSNN的初始权重Winit和LSG的权重变得更适合任务族 F 而减少。图1E显示出在外循环中对LSG和LN的初始权重进行足够好的优化后,自然e-prop几乎完美无缺地完成了这个one-shot任务。它还表明受限制的自然e-prop效果很好,尽管精度较低。图1F显示优化后的LSG发出的学习信号与BPTT的"理想学习信号"![]() 有很大不同。因此,LSG似乎利用有限范围的学习任务的通用结构,而不是近似BPTT。这种策略赋予自然e-prop以取代BPTT的潜力,用于具体的 F 族学习任务。
有很大不同。因此,LSG似乎利用有限范围的学习任务的通用结构,而不是近似BPTT。这种策略赋予自然e-prop以取代BPTT的潜力,用于具体的 F 族学习任务。
从电机控制任务的最终解决方案中还可以得出一个更一般的教训:虽然人们通常在生物电机控制模型中假设电机的正向和/或逆向模型是必不可少的,但在我们的模型中不需要这些。相反,LSG在其类似进化的优化过程中找到了一种无需这些专门模块即可学习精确运动控制的方法。因此,我们的模型为涉及运动控制和运动相关学习的大脑子系统之间可能的分工提供了新的视角。
Application 2: Learning a new class of characters from a single sample
Implementation
Results
Application 3: Fast learning of posterior probabilities
Task
Implementation
Results
Discussion