一、导入数据
1.1来自内存的数据
将数据上传至内存,读取。
1 with open("name.txt", 'r') as open_file: 2 print('name.txt content: ' + open_file.read())
流化读取
1 with open("name.txt", 'r') as open_file: 2 for observation in open_file: 3 print('Reading Data: ' + observation)
采样数据
将部分的数据读取以备使用。
规律性采样:
1 n = 3 2 with open("Colors.txt", 'r') as open_file: 3 for j, observation in enumerate(open_file): 4 if j % n==0: 5 print('Reading Line: ' + str(j) + 6 ' Content: ' + observation)
随机采样:
1 from random import random 2 sample_size = 0.25 3 with open("Colors.txt", 'r') as open_file: 4 for j, observation in enumerate(open_file): 5 if random()<=sample_size: 6 print('Reading Line: ' + str(j) + 7 ' Content: ' + observation)
1.2使用pandas读取结构化数据
文本数据:
1 import pandas as pd 2 color_table = pd.read_table("Colors.txt") 3 print(color_table)
CSV数据:
1 import pandas as pd 2 titanic = pd.read_csv("Titanic.csv") 3 X = titanic[['age']] 4 Y = titanic[['age']].values 5 print(X) 6 print(Y)
Excel数据:
1 import pandas as pd 2 trig_values = pd.read_excel("Values.xls", 'Sheet1', index_col=None, na_values=None) 3 print (trig_values)
1.3读取非结构化数据(如图像,skimage)
1 from skimage.io import imread 2 from skimage.transform import resize 3 from matplotlib import pyplot as plt 4 import matplotlib.cm as cm 5 6 example_file = ("http://upload.wikimedia.org/" + 7 "wikipedia/commons/7/7d/Dog_face.png") 8 image = imread(example_file, as_grey=True) 9 plt.imshow(image, cmap=cm.gray)
输出图像尺寸:
1 print("data type: %s, shape: %s" % 2 (type(image), image.shape))
裁剪图像:
1 image2 = image[5:70,0:70] 2 plt.imshow(image2, cmap=cm.gray)
压缩图像:
1 image3 = resize(image2, (30, 30), mode='constant') 2 plt.imshow(image3, cmap=cm.gray) 3 print("data type: %s, shape: %s" % 4 (type(image3), image3.shape))
因为图像数据是二维矩阵,扁平化以存储在数据中:
1 image_row = image3.flatten() 2 print("data type: %s, shape: %s" % 3 (type(image_row), image_row.shape))
输出结果为:
data type: <class 'numpy.ndarray'>, shape: (900,)
也就是将原先30*30转化成900个元素的数组。
1.4管理来自数据库中的数据
略
1.5网页数据
网页代码如下:
<MyDataset> <Record> <Number>1</Number> <String>First</String> <Boolean>True</Boolean> </Record> <Record> <Number>2</Number> <String>Second</String> <Boolean>False</Boolean> </Record> <Record> <Number>3</Number> <String>Third</String> <Boolean>True</Boolean> </Record> <Record> <Number>4</Number> <String>Fourth</String> <Boolean>False</Boolean> </Record> </MyDataset>
解析代码:
1 from lxml import objectify 2 import pandas as pd 3 4 xml = objectify.parse(open('XMLData.xml')) 5 root = xml.getroot() 6 df = pd.DataFrame(columns=('Number', 'String', 'Boolean')) 7 8 for i in range(0,4): 9 obj = root.getchildren()[i].getchildren() 10 row = dict(zip(['Number', 'String', 'Boolean'], 11 [obj[0].text, obj[1].text, 12 obj[2].text])) 13 row_s = pd.Series(row) 14 row_s.name = i 15 df = df.append(row_s) 16 17 print (df)
运行结果:
Number String Boolean 0 1 First True 1 2 Second False 2 3 Third True 3 4 Fourth False
二、整理数据
用numpy(速度快)和pandas工作
2.1了解数据
去重,使用 pd.DataFrame.duplicated,重复的返回True
1 from lxml import objectify 2 import pandas as pd 3 4 xml = objectify.parse(open('XMLData2.xml')) 5 root = xml.getroot() 6 df = pd.DataFrame(columns=('Number', 'String', 'Boolean')) 7 8 for i in range(0,4): 9 obj = root.getchildren()[i].getchildren() 10 row = dict(zip(['Number', 'String', 'Boolean'], 11 [obj[0].text, obj[1].text, 12 obj[2].text])) 13 row_s = pd.Series(row) 14 row_s.name = i 15 df = df.append(row_s) 16 17 search = pd.DataFrame.duplicated(df) 18 print (search[search==False])
使用 print (df.drop_duplicates()) 直接打印出去重之后的结果。
查看数据中潜在的问题,例如:
- 重复变量
- 数据错误
- 丢失数据
- 变量转换
1 import pandas as pd 2 3 df = pd.DataFrame({'A': [0,0,0,0,0,1,1], 4 'B': [1,2,3,5,4,2,5], 5 'C': [5,3,4,1,1,2,3]}) 6 7 a_group_desc = df.groupby('A').describe() 8 print (a_group_desc)
describe用于获取统计信息,可以直接看出数据集中是否有问题,返回结果如下:
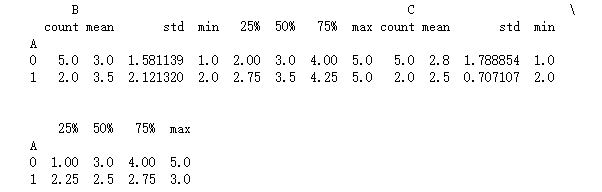
unstack()可以用于格式化结果,使其更美观
用loc()指定标签获取元素:
1 print (unstacked.loc[:,['count','mean']])
2.2 创建分类变量
1 import pandas as pd 2 3 car_colors = pd.Series(['Blue', 'Red', 'Green'], dtype='category') 4 car_data = pd.Series( 5 pd.Categorical(['Yellow', 'Green', 'Red', 'Blue', 'Purple'], 6 categories=car_colors, ordered=False)) 7 find_entries = pd.isnull(car_data) 8 9 print (car_colors) 10 print (car_data) 11 print (find_entries[find_entries == True])
重命名层级:
1 import pandas as pd 2 3 car_colors = pd.Series(['Blue', 'Red', 'Green'], 4 dtype='category') 5 car_data = pd.Series( 6 pd.Categorical( 7 ['Blue', 'Green', 'Red', 'Blue', 'Red'], 8 categories=car_colors, ordered=False)) 9 10 11 car_colors.cat.categories = ["Purple", "Yellow", "Mauve"] 12 car_data.cat.categories = car_colors 13 print (car_data)
结果如下,就是直接根据位置进行替换。

2.3 处理丢失值
isnull():判断是否为空
fillna():用一个值填充空值
dropna():丢弃空值
为丢失数据估值:
1 import pandas as pd 2 import numpy as np 3 from sklearn.preprocessing import Imputer 4 5 s = pd.Series([1, 2, 3, np.NaN, 5, 6, None]) 6 7 imp = Imputer(missing_values='NaN', 8 strategy='mean', axis=0) 9 10 imp.fit(np.array([1, 2, 3, 4, 5, 6, 7]).reshape(1,-1)) 11 12 x = pd.Series(imp.transform(s.values.reshape(1,-1)).tolist()[0]) 13 14 print (x)
2.4 剪切和变换数据
1.切分,过滤,筛选数据
2.排序和打乱
1 import pandas as pd 2 import numpy as np 3 4 df = pd.DataFrame({'A': [2,1,2,3,3,5,4], 5 'B': [1,2,3,5,4,2,5], 6 'C': [5,3,4,1,1,2,3]}) 7 8 df = df.sort_index(by=['A', 'B'], ascending=[True, True]) 9 df = df.reset_index(drop=True) 10 print (df) 11 12 index = df.index.tolist() 13 np.random.shuffle(index) 14 df = df.ix[index] 15 df = df.reset_index(drop=True) 16 17 print (df)
sort_index(by=['A', 'B'], ascending=[True, True])排序,以A,B作为索引,升序排列;
调用reset_index(drop=True)显示结果,drop表示是否插入原索引,true表示不插入;
random.shuffle()创建新的索引顺序,然后按照这个新顺序应用于df
结果为:

3.聚合数据
1 import pandas as pd 2 3 df = pd.DataFrame({'Map': [0,0,0,1,1,2,2], 4 'Values': [1,2,3,5,4,2,5]}) 5 6 df['S'] = df.groupby('Map')['Values'].transform(np.sum) 7 df['M'] = df.groupby('Map')['Values'].transform(np.mean) 8 df['V'] = df.groupby('Map')['Values'].transform(np.var) 9 10 print (df)
结果为:
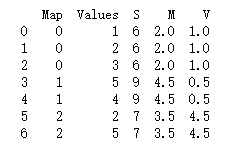
三、数据整形
3.1 使用网页中的数据
将xml中的数据进行整理,不仅仅是提取内容,还需要规范值的属性。
1 from lxml import objectify
2 import pandas as pd 3 from distutils import util 4 5 xml = objectify.parse(open('XMLData.xml')) 6 root = xml.getroot() 7 df = pd.DataFrame(columns=('Number', 'Boolean')) 8 9 for i in range(0,4): 10 obj = root.getchildren()[i].getchildren() 11 row = dict(zip(['Number', 'Boolean'], 12 [obj[0].pyval, 13 bool(util.strtobool(obj[2].text))])) 14 row_s = pd.Series(row) 15 row_s.name = obj[1].text 16 df = df.append(row_s) 17 18 print (type(df.ix['First']['Number'])) 19 print (type(df.ix['First']['Boolean'])) 20 print (df)
输出结果为:

使用XPATH可以更加方便地抽取数据:
from lxml import objectify import pandas as pd from distutils import util xml = objectify.parse(open('XMLData.xml')) root = xml.getroot() #zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。 #map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。 data = zip(map(int, root.xpath('Record/Number')), map(bool, map(util.strtobool, map(str, root.xpath('Record/Boolean'))))) df = pd.DataFrame(list(data), columns=('Number', 'Boolean'), index=list(map(str, root.xpath('Record/String')))) print (df) print (type(df.ix['First']['Number'])) print (type(df.ix['First']['Boolean']))
注意:DataFrame中的元素不能是迭代的,因此需要转化成list
3.2 使用文本数据
涉及自然语言处理。