tile
贪心
题意:给出一个矩形,用不同字母代表的正方形填充,要求相邻的方块字母不能相同,求字典序(将所有行拼接起来)最小的方案。
初步解法:一开始没怎么想,以为策略是每次填充一个尽量大的正方形。但是很快就能找到反例。比如当一个 4*2 的矩形左半部分填充了一个 2*2 的 A 后,不应该在右半部分填充 2*2 的 B,而是应该先填一个 1*1 的 B,然后继续用 A 填充,如图。
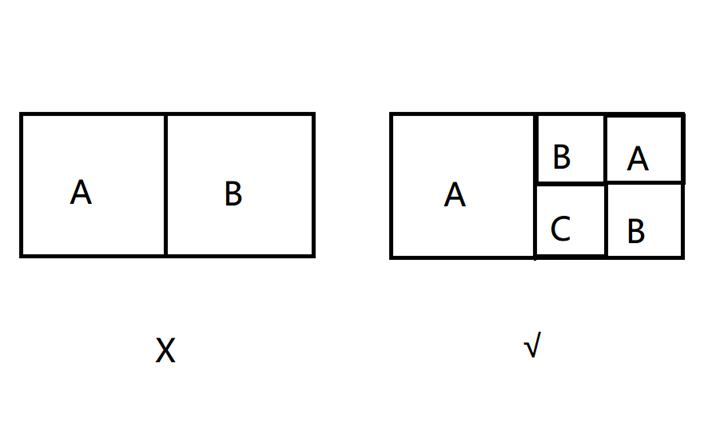
上面这个例子中,第二种方案虽然用到了 C,但是如果按照题意将每一行拼接起来之后第二种方案的字典序显然更小。
正解:从上面的反例中我们可以看出,不用考虑整体,按每行每列的顺序考虑每个格子即可。比如左上角第 1 个格子 (1, 1),1*1 的 A 无疑是最优解,然后看能否扩展,发现可以扩展到2*2 的 A,所以就进行填充。然后到了 A 右边第一个格子 (1, 3),显然应该填 1*1 的 B,然后看能否扩展,格子 (1, 4) 是可以用 A 填充的,所以 (1, 3) 的 B 就不扩展。只要按行的顺序来考虑每个格子就能保证字典序最小。
path
最短路
题意:求一个无向图中任意两点间所有可能的最短路的边数之和。
初步解法:很明显先用 Floyd 求出两点间最短路。然后我的做法是做一个 O(N^3) 的递推。用 f(i, j) 表示从 i 到 j 的最短路一共有多少边数。f(i, j) = sum{ f(i, k), (k, j) ∈E且dist(i, k)+g(k, j)=dist(i, j) },边界条件是 f(i, i) = 1。但是这种方法能找到反例,如下图:
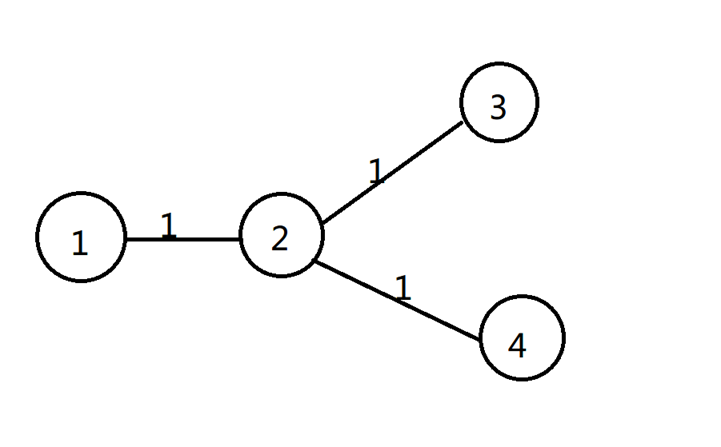
假设图中 (1 -> 3) 和 (1 -> 4) 都是 1 到某个点的最短路的一部分,那么 f(2, 2) = 1 就会在最终结果中被累计两次,而实际上是同一条边,所以会导致答案偏大。
正解:先了解「最短路图」的概念。对于任意的点对 (i, j),将在从 i 到 j 的最短路中出现过的点与边加入到从 i 到 j 的最短路图中。很明显,最短路图中的点满足 dist(i, k)+dist(k, j)=dist(i, j) 的条件。则 i 到 j 的所有最短路的总边数等于最短路图中每个顶点的入度。具体的程序实现中不必构造这样的最短路图,只要判断顶点是否满足上述条件,然后统计其入度即可。
tower
并查集
大意:以矩阵的形式给出一个圆柱体的侧面,现在要在其中加入障碍点,对于一个障碍点判断其是否能加入的条件是:加入该障碍点后从下往上依然存在一条四连通的路径。注意是圆柱体的侧面,所以虽然以矩阵形式给出但不存在实际上的左右边界,即从矩阵的最右边可以往右走到矩阵的最左边。
初步解法:每次假设将障碍点加入,然后对于底部的点做 DFS 判断是否存在从底部到顶部的四连通路径。据说如果优化得足够好也是能够 AC 的。
正解:对于判断连通的问题自然而然地会想到并查集。但是这一题中空格子的数目在不断减少,而并查集的元素删除并不容易,所以需要进行巧妙的转化。为了处理方便,我们可以先把整个矩形完整地复制一遍,将两个矩形并列。每次加点都将其加到两个矩阵中。如果一个点与它在另一个矩阵中的「复制」点之间通过其他的障碍点共同形成了一个八连通块,就必然能够将整个圆柱体侧面堵住。自己画一下就知道是对的。由于矩阵中的障碍点是不断增加的,所以用并查集处理就会比较简单。不过关于判断连通还是需要一定技巧。我一开始的想法先将这个点加入,那么就将其与周边的八个点在并查集中合并。但是如果判断出的结果是这个点不能加入,那么就很难将并查集恢复到原状。然后的想法是枚举两个矩阵中目前处理的点四周的八个点(为什么只需要判断这八个点?因为如果将目前的点加入,那么它必然会和旁边这八个点形成同一个八连通块),判断其两两是否在同一集合中,这样需要 64 次判断。而更优的方法是用哈希表,在左边的矩阵中将目前处理的点旁边的八个点 hash(具体方法是 hash[find_set(i)] = xxx),然后在右边也进行 hash,如果在右边处理时发生了冲突就说明如果加入这个点必然会形成一条横跨整个圆柱体侧面的八连通块。一个提示:如果每次处理一个点都将 hash 数组初始化为 0,时间耗费是很大的。所以可以用这样一个优化:将 hash 值赋为当前处理的点的编号(即循环变量 i)。这样每次的 hash 都不会被上一次遗留的 hash 值影响,省去了重置 hash 的时间。