参考这个:http://kb.cnblogs.com/page/73759/
参考这个:http://www.cnblogs.com/charlesblc/p/6286875.html
写的挺好
RabbitMQ是一个由erlang开发的基于AMQP(Advanced Message Queue )协议的开源实现。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面都非常的优秀。是当前最主流的消息中间件之一。
RabbitMQ的官网:http://www.rabbitmq.com
学习RabbitMQ 首先对AMQP有一定的认识和了解
AMQP协议是一种二进制协议,提供客户端应用与消息中间件之间异步、安全、高效地交互。从整体来看,AMQP协议可划分为三层:

这种分层架构类似于OSI网络协议,可替换各层实现而不影响与其它层的交互。AMQP定义了合适的服务器端域模型,用于规范服务器的行为(AMQP服务器端可称为broker)。在这里Model层决定这些基本域模型所产生的行为,这种行为在AMQP中用”command”表示,在后文中会着重来分析这些域模型。Session层定义客户端与broker之间的通信(通信双方都是一个peer,可互称做partner),为command的可靠传输提供保障。Transport层专注于数据传送,并与Session保持交互,接受上层的数据,组装成二进制流,传送到receiver后再解析数据,交付给Session层。Session层需要Transport层完成网络异常情况的汇报,顺序传送command等工作。
上面是对AMQP协议的大致说明。下面会以我们对消息服务的需求来理解AMQP所提供的域模型。消息中间件的主要功能是消息的路由(Routing)和缓存(Buffering)。在AMQP中提供类似功能的两种域模型:Exchange 和 Message queue。
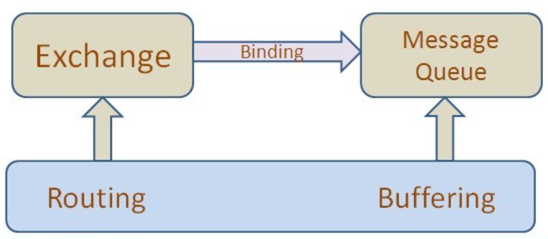
Exchange接收消息生产者(Message Producer)发送的消息根据不同的路由算法将消息发送往Message queue。Message queue会在消息不能被正常消费时缓存这些消息,具体的缓存策略由实现者决定,当message queue与消息消费者(Message consumer)之间的连接通畅时,Message queue有将消息转发到consumer的责任。
(注:代码示例可以看 http://www.cnblogs.com/charlesblc/p/5516585.html 最后面的pyamqp的例子)
也可以看http://www.cnblogs.com/charlesblc/p/6286900.html,这个准备对AMQP各种模型做深入学习。
Message是当前模型中所操纵的基本单位,它由Producer产生,经过Broker被Consumer所消费。它的基本结构有两部分: Header和Body。Header是由Producer添加上的各种属性的集合,这些属性有控制Message是否可被缓存,接收的queue是哪个,优先级是多少等。Body是真正需要传送的数据,它是对Broker不可见的二进制数据流,在传输过程中不应该受到影响。
一个broker中会存在多个Message queue,Exchange怎样知道它要把消息发送到哪个Message queue中去呢? 这就是上图中所展示Binding的作用。Message queue的创建是由client application控制的,在创建Message queue后需要确定它来接收并保存哪个Exchange路由的结果。Binding是用来关联Exchange与Message queue的域模型。Client application控制Exchange与某个特定Message queue关联,并将这个queue接受哪种消息的条件绑定到Exchange,这个条件也叫Binding key或是 Criteria。
在与多个Message queue关联后,Exchange中就会存在一个路由表,这个表中存储着每个Message queue所需要消息的限制条件。Exchange就会检查它接受到的每个Message的Header及Body信息,来决定将Message路由到哪个queue中去。Message的Header中应该有个属性叫Routing Key,它由Message发送者产生,提供给Exchange路由这条Message的标准。Exchange根据不同路由算法有不同有Exchange Type。比如有Direct类似,需要Binding key等于Routing key;也有Binding key与Routing key符合一个模式关系;也有根据Message包含的某些属性来判断。一些基础的路由算法由AMQP所提供,client application也可以自定义各种自己的扩展路由算法。那么一个Message的处理流程类似于这样:

在这里有个新名词需要介绍: Virtual Host。一个Virtual Host可持有一些Exchange和Message queue。它是一个虚拟概念,一个Virtual Host可以是一台服务器,也可以是由多台服务器组成的集群。同步扩展下,Exchange与Message queue的部署也可以是一台或是多台服务器上。
Message的产生者和消费者可能是同一个应用。整个AMQP定义的就是Client application与Broker之间的交互。在粗略介绍完AMQP的域模型后,可以关注下Client是怎样与Broker建立起连接的。
在AMQP中,Client application想要与Broker沟通,就需要建立起与Broker的connection,这种connection其实是与Virtual Host相关联的,也就是说,connection是建立在client与Virtual Host之间。可以在一个connection上并发运行多个channel,每个channel执行与Broker的通信,我们前面提供的session就是依附于channel上的。 (注:看之前的pyamqp代码也能看出来,建立connection之后是需要建立channel的)
这里的Session可以有多种定义,既可以表示AMQP内部提供的command分发机制,也可以说是在宏观上区别与域模型的接口。正常理解就是我们平时所说的交互context,主要作用就是在网络上可靠地传递每一个command。在AMQP的设计中,应当是借鉴了TCP的各种设计,用于保证这种可靠性。
在Session层,为上层所需要交互的每个command分配一个惟一标识符(可以是一个UUID),是为了在传输过程中可以对command做校验和重传。Command发送端也需要记录每个发送出去的command到Replay Buffer,以期得到接收方的回馈,保证这个command被接收方明确地接收或是已执行这个command。
对于超时没有收到反馈的command,发送方再次重传。如果接收方已明确地回馈信息想要告知command发送方但这条信息在中途丢失或是其它问题发送方没有收到,那么发送方不断重传会对接收方产生影响,为了降低这种影响,command接收方设置一个过滤器Idempotency Barrier,来拦截那些已接收过的command。 关于这种重传及确认机制,可以参考下TCP的相关设计。
上面大致介绍了AMQP的域模型及连接机制中的确认及重传模型,不涉及AMQP的详细二进制规范。
温馨提示::::
以上内容为了资源的整合,学习RabbitMQ系列更多的了解认识,来自园友的笨鸟居士的博客 博客http://www.cnblogs.com/charlesblc/p/6286875.html
如果大家请看原文,请访问该该地址,如有冒犯的地方,还请指出,多多包涵小弟!!!!!!