前段时间和一个人聊天,聊到怎么用一个方法一次对两个数组取差集,我说使用array_diff倒是可以做到这个,但是不能只用一次,得两次。然后他就开始跟我讲他理解的array_diff的底层原理:“首先php会对两个数组取交集,然后会把两个数组中不属于交集的元素全部返回,所以只需要一次就够了,根本不用两次”。
说实话,我也希望是这样,但是事实不是这样,以下是php(php-7.0.7)的源码
PHP_FUNCTION(array_diff) { zval *args; int argc, i; uint32_t num; HashTable exclude; zval *value; zend_string *str, *key; zend_long idx; zval dummy; /* 判断参数个数是否合法 */ if (ZEND_NUM_ARGS() < 2) { php_error_docref(NULL, E_WARNING, "at least 2 parameters are required, %d given", ZEND_NUM_ARGS()); return; } /* */ if (zend_parse_parameters(ZEND_NUM_ARGS(), "+", &args, &argc) == FAILURE) { return; } if (Z_TYPE(args[0]) != IS_ARRAY) { php_error_docref(NULL, E_WARNING, "Argument #1 is not an array"); RETURN_NULL(); } /* count number of elements */ num = 0; for (i = 1; i < argc; i++) { if (Z_TYPE(args[i]) != IS_ARRAY) { php_error_docref(NULL, E_WARNING, "Argument #%d is not an array", i + 1); RETURN_NULL(); } num += zend_hash_num_elements(Z_ARRVAL(args[i])); } if (num == 0) { ZVAL_COPY(return_value, &args[0]); return; } ZVAL_NULL(&dummy); /* create exclude map */ /* 初始化exclude */ zend_hash_init(&exclude, num, NULL, NULL, 0); /* 从第二个参数开始遍历参数列表,将各个数组中的元素(element)依次添加到exclude中 */ for (i = 1; i < argc; i++) { ZEND_HASH_FOREACH_VAL_IND(Z_ARRVAL(args[i]), value) { str = zval_get_string(value); zend_hash_add(&exclude, str, &dummy); zend_string_release(str); } ZEND_HASH_FOREACH_END(); } /* copy all elements of first array that are not in exclude set */ /* 将包含在第一个数组中但不在exclude中的元素(elements)复制到return_value中 */ array_init_size(return_value, zend_hash_num_elements(Z_ARRVAL(args[0]))); ZEND_HASH_FOREACH_KEY_VAL_IND(Z_ARRVAL(args[0]), idx, key, value) { str = zval_get_string(value); if (!zend_hash_exists(&exclude, str)) { if (key) { value = zend_hash_add_new(Z_ARRVAL_P(return_value), key, value); } else { value = zend_hash_index_add_new(Z_ARRVAL_P(return_value), idx, value); } zval_add_ref(value); } zend_string_release(str); } ZEND_HASH_FOREACH_END(); zend_hash_destroy(&exclude); }
过程描述:
1.计算除了第一个数组之外的数组的元素个数;
2.初始化HashTable exclude,大小就是第一步计算的元素个数的大小;
3.把除了第一个数组之外的数组元素全部放到exclude中;
4.然后用zend_hash_exists方法将第一个数组args[0]的元素和exclude中的元素一一比较,如果发现有元素不在exclude中就把这个元素放到return_value中,直到把args[0]中的元素遍历一遍。
到这个时候return_value中存的数据就array_diff返回给用户的数据。
以上就是array_diff的运行原理,不存在数组取交集的过程,每次调用array_diff得到的结果都是第一个数组中存在但是后面数组中均不存在的元素的集合。
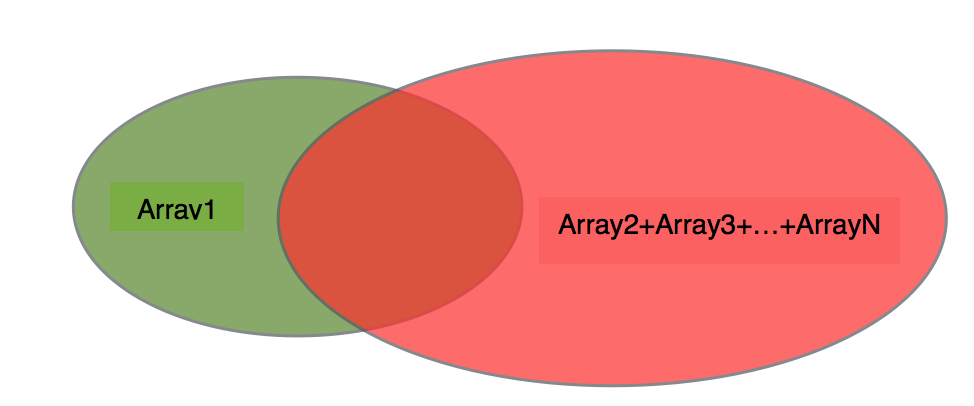
绿色部分才是array_diff(array1,array2, array3,...,arrayN);的结果。