编码基础
编码概述
基本概念很简单。首先,我们从一段信息即消息说起,消息以人类可以理解、易懂的表示存在。我打算将这种表示称为“明文”(plain text)。对于说英语的人,纸张上打印的或屏幕上显示的英文单词都算作明文。其次,我们需要能将明文表示的消息转成另外某种表示,我们还需要能将编码文本转回成明文。从明文到编码文本的转换称为“编码”,从编码文本又转回成明文则为“解码”。
python解释器在加载 .py 文件中的代码时,会对内容进行编码。python2 默认编码方式是ascii码,python3 默认编码方式utf-8。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
编码方式
ascii:只能支持英文、特殊字符、数字,用一个字节表示一个字符。最多只能表示 255 个符号;(ascii码第一位为0,7为够,设计者为了后续扩展预留了1位)
万国码(unicode):所有的字符和符号由4个字节来表示。占资源较多;(因为ascsi不能表示全球的所有字符,为了解决全球化问题,创建了万国码。早期所有字符使用2个字节表示,现在已经废弃)
UTF-8:是对Unicode的升级。UTF-8最少使用一个字节表示一个字符。一个字节表示一个英文字符、2个字节表示一个欧洲字符、3个字节表示一个亚洲字符;
gbk:是国人在 ascii 码的基础上进行升级的,只支持中文和英文,2个字节表示一个中文字符,1个字节表示一个英文字符。
注意:各个编码之间的二进制是不能互相识别的,会产生乱码;文件的存储和传输不能是Unicode编码方式,因为Unicode占资源较多,只能使用utf8-8、utf8-16、gbk、gb2312、ascii等编码方式才能存储和传输;各个编码之间的转换可以通过unicode这个中间过程进行转换。(utf8-8、utf8-16、gbk、gb2312、ascii等编码方式统称为bytes)
编码解码
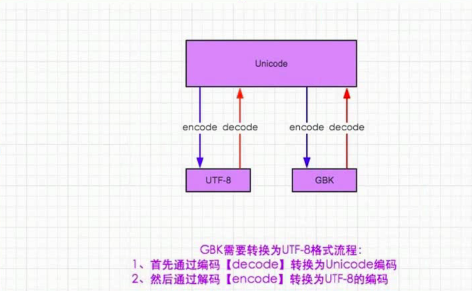
编码 encode:将str数据类型转化成bytes数据类型
解码 decode:将bytes数据类型转化成str数据类型
字节串:bytes;字符串:unicode
python2编码
python2编码
Python2有两种数据类型:str和unicode。str数据类型在内存中是用bytes编码方式存储(bytes是utf8-8、utf8-16、gbk、gb2312、ascii等编码方式的统称)。

#!-*- coding:utf-8 -*-
#__author: lriwu
# str 字节串
s1 = "测试hello"
print len(s1) # 字节串长度为11字节
print repr(s1) # 'xe6xb5x8bxe8xafx95hello'
print type(s1) # <type 'str'>
# unicode 字符串
s2 = u"测试hello" # 定义字符串
print len(s2) # 字符串的长度为7个字符
print repr(s2) # u'u6d4bu8bd5hello'
print type(s2) # <type 'unicode'>
python2编码的最大特点:Python2 将会自动的将bytes数据解码成 unicode 字符串
print "测试" # 测试,即可以显示中文。正常情况下其实不应该显示中文,而应该是字节串,之所以显示中文,原因是在py 2中自动的将bytes数据类型解码成 unicode 字符串
print "hello"+u"yuan" # helloyuan ,即byte和unicode可以进行拼接,Python 2 将会自动的将bytes数据解码成 unicode 字符串
两个问题:
1、print "测试" :本来存的是'xe8x8bx91xe6x98x8a',为什么显示了明文?
正常情况下其实不应该显示中文,而应该是字节串(bytes),之所以显示中文,原因是在py 2中自动的将bytes数据解码成 unicode 字符串。
2、字节串和字符串可以拼接?
这就是那些可恶的 UnicodeError 。代码中包含了 unicode 和 byte 字符串,只要数据全部是 ASCII 的话,所有的转换都是正确的,一旦一个非 ASCII 字符偷偷进入你的程序,那么默认的解码将会失效,从而造成 UnicodeDecodeError 的错误。Python 2 悄悄掩盖掉了 byte 到 unicode 的转换,让程序在处理 ASCII 的时候更加简单。你复出的代价就是在处理非 ASCII 的时候将会失败。
print "测试"+u"文本" #字节串和字符串进行拼接
E:soft_installpythonpython2.7python2.exe F:/code/test.py
Traceback (most recent call last):
File "F:/code/test.py", line 5, in <module>
print "测试"+u"文本"
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128)
编码解码
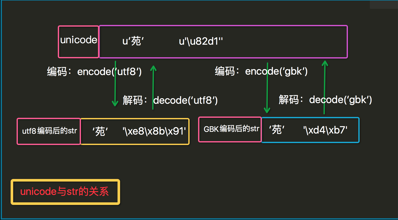
#coding:utf8
u = u'苑'
print repr(u) # u'u82d1'
# print str(u) #UnicodeEncodeError
s = u.encode('utf8')
print repr(s) #'xe8x8bx91'
print str(s) # 苑
u2 = s.decode('utf8')
print repr(u2) # u'u82d1'
str和unicode都是basestring的子类。严格意义上说,str其实是字节串,它是unicode经过编码后的字节组成的序列。对UTF-8编码的str'苑'使用len()函数时,结果是3,因为utf8编码的'苑' == 'xe8x8bx91';
而unicode是一个字符串,str是unicode这个字符串经过编码(通过utf8或gbk编码)后的字节组成的序列;
unicode才是真正意义上的字符串,对字节串str使用正确的字符编码进行解码后获得,并且len(u'苑') == 1。
python3编码
python3编码
跟 Python2 类似,Python3 也有两种数据类型:unicode和bytes。但是他们有不同的命名。在py3中,将unicode重命名为str,将str重命名为bytes。即python3中两种数据类型是:str数据类型和bytes数据类型。str数据类型内存中是用unicode编码方式存储的,不能进行文件的存储和传输;bytes数据类型在内存中是用utf8-8、utf8-16、gbk、gb2312、ascii等编码方式存储的,进行文件的存储和传输需要转化成bytes数据类型。


对于英文:
str表现形式:s = 'alex'
str在内存中的编码方式:0101010101 unicode编码方式
bytes表现形式:s = b'alex'
bytes在内存中的编码方式:0101010101 utf-8 gbk等编码方式
例子
s = 'alex'
s1 = b'alex'
print(s,type(s)) //alex <class 'str'>
print(s1,type(s1)) //b'alex' <class 'bytes'>
对于中文:
str表现形式:s = '中国'
str在内存中的编码方式:0101010101 unicode编码方式
bytes表现形式:s = b'xe4xb8xadxe5x9bxbd'
bytes在内存中的编码方式:0101010101 utf-8 gbk等编码方式
例子
s = '中国'
print(s,type(s)) //alex <class 'str'>
s1 = b'中国' //这里会报错
print(s1,type(s1)) //b'alex' <class 'bytes'>
编码解码
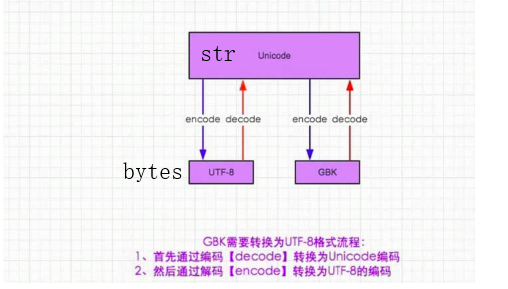
编码 encode:将str数据类型转化成bytes数据类型;
解码 decode:将bytes数据类型转化成str数据类型。
编码例子:
s1 = 'alex'
s11 = s1.encode('utf-8') #将str转换成utf-8
print(s11) # b'alex'
s2 = '中国'
s22 = s2.encode('utf-8')
s33 = s2.encode('gbk')
print(s22,type(s22)) # b'xe4xb8xadxe5x9bxbd' <class 'bytes'>
print(s33,type(s33)) # b'xd6xd0xb9xfa' <class 'bytes'>
#总结:utf-8一个中文字符用3个字节,gbk一个中文字符用2个字节表示
编码实现
编码实现
说到编码,我们需要在全局掌握这个工作过程,比如我们在pycharm上编写一个.py文件,从保存到运行数据到底是怎么转换的呢?在解决这个问题之前,我们需要解决一个问题:默认编码,默认编码其实就是你的解释器解释代码时默认的编码方式,在py2里默认的编码方式是ASCII,在py3里则是utf8。(可以使用sys.getdefaultencoding()查看默认的编码方式):
#-*- coding: UTF-8 -*-
我们在最开始只知道在py2里如果不加上述这一句话,程序中有中文就会报错,其实就是因为py2默认的ASCII码,对于中文这些特殊字符无法编码。声明这句话就是告诉python2.7解释器解释hello.py文件时使用utf8编码,而不是使用默认的ASCII编码方式,将文件编码成字节串最后转成0101的形式让机器去执行;
hello.py文件保存时有自己特定的编码方式,比如utf8,比如gbk。声明使用的编码方式必须与文件实际保存时使用的编码方式一致,否则很大几率会出现代码解析异常(即在.py文件中声明解释器编码时使用utf8编码方式,此时.py文件保存时也要使用utf8编码方式保存至磁盘)。现在的IDE一般会自动处理这种情况,改变声明后同时换成声明的编码方式保存,但当使用操作系统上的文本编辑器编辑文本时需要小心,文件保存的编码方式取决于你使用的编辑器默认的样式(可调);
出现乱码的情况
案例1:
#!-*- coding:utf-8 -*-
#__author: lriwu
s = "特斯拉"
print (s)
F:code>python test.py
特斯拉
#在cmd下使用python3编译,可以正常显示。
正常显示条件:
1. py文件是以utf8编码方式存储,解释器也是以utf8编码方式对.py文件进行编译;
2.打印的内容要在终端显示,在python3中该字符串是str类型,在内存中是以unicode编码方式存储。所以cmd(windows默认使用gbk编码)能够识别该unicode编码,所以能够正常显示。(unicode所有的编码方式都能识别)
#!-*- coding:utf-8 -*-
#__author: lriwu
s = "特斯拉"
print (s)
F:code>python2 test.py
鐗规柉鎷
#在cmd下使用python2编译,不能正常显示。
不能显示原因:
1. py文件是以utf8编码方式,解释器也是以utf8编码方式对.py文件进行编译。这个满足;
2.打印的内容要在终端显示,在python2中该字符串是str类型,在内存是以bytes编码方式存储(这里是以utf8编码方式存储)。所以cmd(windows默认使用gbk编码)不能够识别该utf8编码,所以不能正常显示。
实现在py2上正常显示:
#!-*- coding:utf-8 -*-
#__author: lriwu
print (u'"特斯拉"')
F:code>python2 test.py
"特斯拉"
案例2:
在py2中正常显示
f = open('ces','r')
print (f.read())
E:soft_installpythonpython2.7python2.exe F:/code/test.py
测试
# open('ces','r')这个是调用操作系统命令执行,所以使用的是windows默认的gbk编码。在py2中会自动的将gbk编码后的bytes数据解码成 unicode 字符串。
在py3上显示乱码
f = open('ces','r')
print (f.read())
E:soft_installpythonpython2.7python2.exe F:/code/test.py
娴嬭瘯
#open('ces','r')这个是调用操作系统命令执行,所以使用的是windows默认的gbk编码。gbk编码后的bytes数据类型在pycharm中无法通过utf8的方式进行解码,所以显示乱码。
在py3上正常显示
f = open('ces','r',encoding='utf8')
print (f.read())
E:soft_installpythonpython3.5python.exe F:/code/test.py
测试
#在这里声明windows打开文件时使用utf8方式编码,而不是使用windows默认的gbk进行编码。