计算机体系结构
一个计算机系统由运算器、控制器、存储器(即内存)、输入设备、输出设备组成。其中运算器运算数据,而数据在内存中,运算器要通过控制器到内存中获取数据,运算器最后将运算后的结果通过控制器保存在内存中,通常程序由指令和数据组成,当程序运行时指令和数据保存在内存中,指令中有数据在内存中的地址信息,从而运算器知道数据在内存的位置,然后通过控制器获取所需的数据;一般来说IO设备是通过北桥或南桥芯片连入的,北桥成为高速总线控制器:内存和CPU通过北桥连接在一起。南桥称为低速总线控制器:外围设备和南桥连在一起,然后南桥和北桥相连;
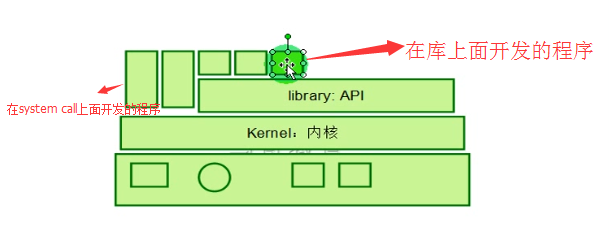
对一个简单的PC机而言,在某一时刻只能运行一个程序,但PC计算能力很强一个程序运行的程序内容和占用的CPU时间不是特别长,因此为了能够尽可能利用计算机的资源,需要让PC具有同时运行多个程序的能力,因此每个程序在运行时需要一个协调器称为内核(内核是运行在硬件之上负责管理硬件资源并且将硬件资源虚拟成其他样子提供给上层所需的应用程序(这样做的原因是如果某一应用程序直接运行在硬件之上则此程序就可以控制硬件的各种属性,其它程序运行时可能彼此会产生干扰,一个恶意的程序可能导致其它程序统统退出所以就需要统一的资源管理者,而且每个程序要想使用硬件必须通过内核来完成,而内核也不会让程序直接访问硬件而是通过将硬件提供的计算能力通过一个个的称为系统调用(system call)来实现,为了让system call尽可能的少,system call都做的非常底层,因此程序员通过系统调用来编程将非常繁琐而且许多程序之间的功能是相同的。如Word和excel都需要打印,如果不把这些接口做为公用的话这就意味着word和excel都需要各自开发一个打印模块,这就意味着在我们计算机上大多数功能是重复的而这些重复势必会占用额外的空间造成资源浪费。因此OS除了提供内核之外通常还需要将自己内核所提供的内核调用输出出来,这种输出是通过较为高层的调用接口来实现的,这种接口称为库(也称为API:应用编程接口),库本身也是应用程序,只是这个应用程序没有程序的执行路口,不能独立运行,只有通过其它程序调用的时候才能执行,所以程序员要想调用硬件可以通过库调用(library call简称lib)也可以不使用库调用直接在内核上用系统调用(system call)来实现),将硬件资源提供的计算能力分配给多个应用程序即进程。
CPU作用
从内存中取出指令,并解码指令(即将指令转化成cpu能够运行的指令),完成解码后再执行指令;因此cpu有取值单元、解码单元、执行单元三个组件;当一个程序有多条指令时,cpu将从内存中取出指令并保存在寄存器中,使用指令计数器指向将要执行的指令;将cpu进行上下文切换时,cpu需要将寄存器的每一个状态保存至内存中,cpu修改的数据也保存在内存中。
早期通过提高cpu频率来提高cpu的效率;后面cpu频率无法提高,于是就有了多核心,但是一个进程只能在一个核心上运行,当服务器有多核心,而只有一个繁忙的进程,此时就无法发挥多核心的优势,于是就有了线程,将一个进程分割为多个线程,使得各个线程在多个核心上运行,提高了效率。
存储体系
机械硬盘-固态硬盘-内存-三级缓存-二级缓存-一级缓存-寄存器(由慢-快)
寄存器:能够以接近CPU的时钟周期进行工作,CPU操作的是寄存器中的数据,寄存器中没有要操作的数据则会在一级缓存中查找并将查找到的数据加载至寄存器,如果一级缓存中没有要操作的数据则会在二级缓存这查找并将查找到的结果加载至一级缓存而后再加载至寄存器,以此类推。
一/二级缓存:通常是cpu的物理核心专有的,每一颗物理核心都有自己专的一/二级缓存;
三级缓存:cpu物理核心共享;
内存:cpu物理核心共享。

IO设备的组成
IO设备一般由设备控制器和设备本身组成:
控制器:集成在主板上的一块芯片或一组芯片,负责控制对应的设备。控制器主要负责从操作系统接收命令并完成命令的执行:如os要读取对应设备的数据,此时控制器驱动程序就需要将读取数据的这种操作转换成对应设备的物理操作;
设备:设备本身通常都由自身的一个简单的接口,这个接口需要通过控制器来连接;
驱动程序:通常由设备生产厂商开发,有些控制器直接集成在主板上而且非常通用,为了完成操作系统启动时的基本操作,这种控制器的驱动程序一般集成在内核中了;
寄存器:每个控制器都有少量的用于通信的寄存器,比如一个硬盘控制器可能会有用于指定磁盘地址、扇区数、方向(向磁盘写数据还是读数据)等,所以要激活一个控制器,设备驱动程序从操作系统接收操作指令后将指令转化成对应设备的基本操作并把操作请求放至寄存器中才能完成操作;每个寄存器表现为一个IO端口,所有的寄存器组合称为设备的IO端口空间。
cpu如何识别每个控制器上的IO端口:
对每一个控制器上的IO端口进行编址,即每一个IO端口都有一个独立的地址,当主机启动时,每一个IO端口都需要向总线的IO端口空间注册使用的端口,主机依次为每个IO端口分配端口,所以CPU通过端口就能访问对应的IO设备;cpu要想读取对应设备的数据,将指令发送给驱动,驱动将指令转化为设备能够理解的信号存储在寄存器中,所以寄存器或IO端口是cpu通过总线和IO设备进行打交道的地址;有可能存在一个IO设备接收数据,需要CPU将数据加载到某个进程上对数据进行处理,如网卡接收到用户访问web服务的请求,请求先到达网卡设备,网卡设备不能直接处理请求,此时应该要有一个机制让CPU尽早知道来了这么一个信号,而且让cpu激活内核读取对应IO设备上的数据,并由内核控制cpu启动对应的进程读取用户请求。
实现输入输出的方式:
1.盲等待:用户程序发起一个系统调用,由内核将其翻译成一个对应设备驱动的过程调用,然后设备驱动程序启动IO并在一个连续不断的循环中检查该设备并看该设备是否完成了工作;
2.中断,即IO设备能够主动发送通知,这样就无需盲等待,这种通知就称为中断,即能够中断cpu正在执行的程序从而让cpu通知内核获取中断请求,因此在主机设备上通常有一个可编程中断控制器,该控制器能够直接和cpu进行通信,通知cpu有信号到达。(主机启动时,每一个IO设备要向中断控制器注册使用一个中断号,这个中断号是唯一的,因此当io设备有数据到达时,不会立即将数据放在数据总线中,该io设备会向中断控制器发出中断请求,中断控制器通过中断号判断该中断请求是来自哪个设备,而后中断控制器通过总线通知CPU,让cpu知道由哪个IO设备发来了中断请求,进而cpu激活内核并切换当前正在执行的进程(不是上下文切换而是中断切换),这时原先运行在内核上的进程先退出,内核运行在cpu上,并由内核自己来到这个IO设备上获取数据)
如:网卡设备的工作流程:
一个web服务的用户请求到达,网卡有自己的缓冲区,当一个数据包到达后网卡会触发中断,并将数据包缓存至网卡的缓冲区,内核处理中断,判断是可以接收数据的,于是就将缓存区的数据复制到内核缓冲区,内核缓冲区是内存中的一段存储空间即读缓冲区,读进来后发现是一个网路请求报文,查看目标地址是不是自己,如果目标地址是自己就开始拆报文,通过端口号内核就知道是有哪个进程接收处理。
内核处理中断分为2部分:
中断上部分:cpu激活内核并切换当前正在执行的进程(不是上下文切换而是中断切换),这时内核运行在cpu上,由内核自己来到这个IO设备上获取数据,将数据放在内核缓冲区中),原先运行在cpu上的进程退出;(网卡接收数据报文会频繁触发中断影响性能,于是就有了第3种方式)
中断下部分:如果原先的进程cpu执行时间还未完成,可能内核从cpu退出,cpu继续运行原先的进程,此时只接收数据并不处理数据;处理数据就要通过调度器来调度其它进程来处理。
3.DMA机制,直接内存访问,当需要处理中断上部分时,cpu会通知dma设备,告诉dma设备io总线(控制总线、地址总线、数据总线)归你使用,并且再内存中划分了一段空间供该dma设备使用,可以接收数据至内存,于是dma设备就能够自己实现将数据从缓冲区放至内存中,当数据读取完成后,dma设备向cpu发送中断请求,告诉cpu数据接收完毕,cpu此时只需通知内核数据已经读取完成。一个时间段只能由一个dma设备在使用。(现在大多数需要频繁数据传输的io设备都有dma机制,如网卡、硬盘等)
存储器(即内存)
虚拟地址空间(线性地址空间),即在32位os上,每一个进程认为自己拥有4G内存可用:在linux系统上内核固定使用底端1G内存,进程使用3G内存;
在用户空间的3G内存分割成多个固定大小的页框(4k大小),每一个页框作为一个独立的单元向外进行分配;对于物理内存,实际上能够存配置的叫页框,对于进程来讲叫做页面;所以每一个进程能够拿到的物理内存空间并不是连续的,但是可以虚拟成连续的。

通过上图实现将每个线性地址空间映射到物理空间,即当一个进程申请使用内存时,要向内核发起系统调用,由内核在物理内存申请空闲的页框;线性地址空间和物理内存间由一个映射关系,当某一个进程在cpu上执行时,进程要取哪些数据,进程会告诉cpu取地址空间xxx中的数据,这里的xxx是线性地址,需要将xxx映射成物理内存地址才能读取到数据(这个映射关系保存在Task struct中),所以在一个进程发出地址请求之后,cpu必须要找相应进程的Task struct并装载映射表完成线程地址到物理地址的转换(这个动作是通过cpu中的MMU组件实现);这种转换关系会缓存在TLB中,提高下次查找的效率。
MMU:内存管理单元,是cpu上的一个组件,当某一进程要访问线性地址空间中某段数据时,这个进程会将这个线性地址空间的地址传给cpu,cpu本身知道通过这个地址是不可能访问到数据的,这时cpu通过MMU将这个地址转换成对物理地址的访问,从而cpu就能访问到数据,并将此时的映射关系保存在TLB中;
Task struct:每一个进程都有一个作业地址结构,这个作业地址结构其实就是内核为每个进程维护的一个数据结构(即一段内存空间:内核为了追踪一个进程,在内核的内存地址空间中通过链表的形式:保存进程id号、父进程id号、所使用的内存地址空间、所在的cpu、所打开的文件、内部的线程等);
TLB(Translation Lookaside Buffer)转换检测缓冲区是一个内存管理单元,用于改进虚拟地址到物理地址转换速度的缓存。TLB是一个小的,虚拟寻址的缓存,其中每一行都保存着一个由单个PTE(Page Table Entry,页表项)组成的块。如果没有TLB,则每次取数据都需要两次访问内存,即查页表获得物理地址和取数据。
shell
操作系统启动的时候,应用程序未必马上运行起来。只能说启动操作系统这些程序具备了运行环境,并没有运行。通常启动程序的方式有多种:比如操作系统启动后程序自动运行如一些服务等,也可手动启动。手动启动程序怎么去指挥计算机启动某个应用程序呢?怎么让操作系统去接受用户的命令去启动特定的某个应用程序,这时必需给操作系统提供一个特殊的应用程序——shell:它是整个操作系统的外壳,是能够实现接收用户指令理解用户命令并且将它传给内核,由内核指挥着应用程序启动并操作应用程序的界面。shell分为两种:GUI(图形界面);CLI(命令行)。shell作用:1.提供能够让用户进行交互的界面;2.将用户的指挥行为翻译为计算机能够理解的命令。