数据清洗是数据分析过程中一个非常重要的环节,数据清洗的结果直接关系到模型效果和最终结论。在实际中,数据清洗通常会占数据分析整个过程的50%-80%的时间。下面介绍以下数据清洗主要的步骤和任务。
1.数据预处理阶段
该阶段的主要任务是将数据导入数据库中,然后查看数据:对数据有个基本的了解,并且初步发现一些问题,为之后的处理做准备。
2.缺失值清洗
缺失值是最常见的数据问题,处理缺失值的方法:
(1).确定缺失值的范围:对每个字段计算其缺失值的比例,然后按照缺失比例和字段的重要性,采用以下策略:
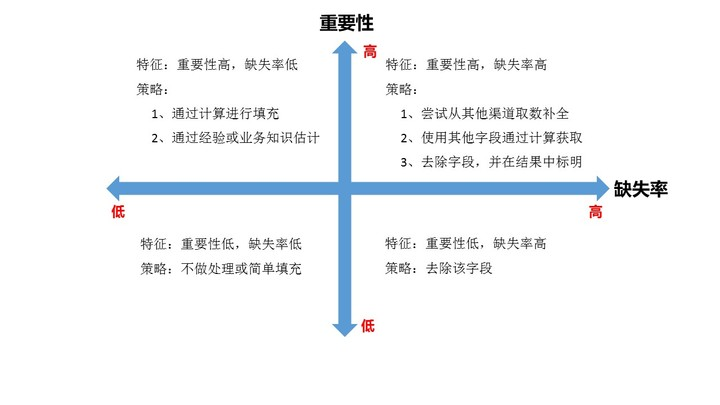
(2).去除不需要的字段:直接删掉(建议每做一次清洗前都备份以下)
(3).填充缺失内容:对于缺失值的填充有以下三种方法
- 以业务知识、常识或经验推测其缺失值并填充
- 用同一指标的计算机结果(均值、中位数、众数等)填充缺失值
- 以不同指标的计算机结果填充缺失值(比如数据本身和它的其他数据相关,比如身份证号的生日那一部分)
(4).重新取数:对于比较重要且缺失率比较高的,考虑重新从其他渠道再取一次数据。
3.格式内容清洗
(1) 时间、日期、数值、全半角等显示格式不一致
将其处理成一致的某种格式即可
(2)内容中有不该存在的字符
比如空格或者身份证号出现汉字,这种典型的不合理字符。需要半自动校验半人工方式来找出可能存在的问题,并去除不合理字符。
(3) 出现不符合该字段的内容
比如姓名写成了性别这种问题。该问题特殊性在于:不能简单的用删除来处理,因为成因有可能是人工填写错误,也有可能是前端设计没有校验,还有可能是导入数据时部分或全部存在列没有对齐的问题,因此要详细识别问题类型。
4.逻辑错误清洗
(1)去重
有的时候去重不是简单的删除就可以的。
(2)去除不合理值
比如有的人填表随便填,年龄写190,就明显不合理,这种数据有两种方式:一种直接删除;一种直接按缺失值处理。
(3)修正矛盾内容
比如身份证号中有的数据可以和其他字段验证的,比如年龄,有时候身份证号的年龄和年龄字段中的年龄矛盾,这种就需要根据字段的数据来源,看哪个字段更可靠,去除或者重置不可靠的字段。
5.非需求数据清洗(也就是不需要的字段)
建议:如果一点都无关可以删了,其他的除非数据量大到不删除字段就没办法处理的程度,那么能不删就不删。尽量勤备份。
总之勤备份,多观察,选择合适的方法对数据进行处理。
原作者:https://blog.csdn.net/wyqwilliam/article/details/84801095