题目背景
公元 2044 年,人类进入了宇宙纪元。
题目描述
L 国有 n 个星球,还有 n-1 条双向航道,每条航道建立在两个星球之间,这 n-1 条航道连通了 L 国的所有星球。
小 P 掌管一家物流公司,该公司有很多个运输计划,每个运输计划形如:有一艘物
流飞船需要从 ui 号星球沿最快的宇航路径飞行到 vi 号星球去。显然,飞船驶过一条航道 是需要时间的,对于航道 j,任意飞船驶过它所花费的时间为 tj,并且任意两艘飞船之 间不会产生任何干扰。
为了鼓励科技创新,L 国国王同意小 P 的物流公司参与 L 国的航道建设,即允许小 P 把某一条航道改造成虫洞,飞船驶过虫洞不消耗时间。
在虫洞的建设完成前小 P 的物流公司就预接了 m 个运输计划。在虫洞建设完成后, 这 m 个运输计划会同时开始,所有飞船一起出发。当这 m 个运输计划都完成时,小 P 的 物流公司的阶段性工作就完成了。
如果小 P 可以自由选择将哪一条航道改造成虫洞,试求出小 P 的物流公司完成阶段 性工作所需要的最短时间是多少?
输入输出格式
输入格式:输入文件名为 transport.in。
第一行包括两个正整数 n、m,表示 L 国中星球的数量及小 P 公司预接的运输计划的数量,星球从 1 到 n 编号。
接下来 n-1 行描述航道的建设情况,其中第 i 行包含三个整数 ai, bi 和 ti,表示第
i 条双向航道修建在 ai 与 bi 两个星球之间,任意飞船驶过它所花费的时间为 ti。
接下来 m 行描述运输计划的情况,其中第 j 行包含两个正整数 uj 和 vj,表示第 j个 运输计划是从 uj 号星球飞往 vj 号星球。
输出格式:输出 共1行,包含1个整数,表示小P的物流公司完成阶段性工作所需要的最短时间。
输入输出样例
说明
所有测试数据的范围和特点如下表所示
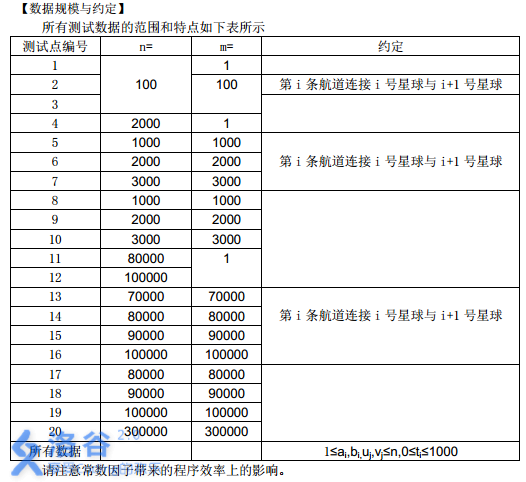
请注意常数因子带来的程序效率上的影响。
思路:这题好麻烦的说。。。我们先考虑m=1的情况,先对运输路线权值求和,再对运输路线权值求最大值,两者作差,得解。
当m!=1时,情况比较复杂,我们一步步分析。首先,因为要求最大值最小,所以我们考虑二分,令mid为当前二分的最大值,那么所有大于mid的路线都是不合法的,我们需要对路线进行删边。
如果多条路线不合法且互不相交,那么我们无论删哪条边都不会使答案合法(想想看,为什么?)。如果存在一条边,它会被所有不合法的路线覆盖,那么它被删掉时才有可能使答案合法,答案合法
当且仅当删去这条边后使得原来最长的路线长度小于等于mid。因为,如果不把这条边删除,那么我们选择的另一条边一定没有被所有不合法的路线覆盖,那么删去后,至少会剩余一整条不合法的路线,
仍不能使答案合法。
求路径交,可以用树剖+线段树(奇慢) ,还可以用树上差分,如果把树上的点映射到DFS序中,那么会更快。由于这题数据范围巨恶心,所以只能用树上差分+DFS序。
至于lca,用树剖求或tarjan离线求。
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> #include<cmath> #include<queue> using namespace std; const int N=3e5+5; const int M=3e5+5; int read() { int ret=0,f=1; char c=getchar(); while(c<'0'||c>'9') {if(c=='-') f=-1;c=getchar();} while(c>='0'&&c<='9') {ret=ret*10+c-'0';c=getchar();} return ret*f; } int n,m; struct edge{ int from,to,dis; }e[M<<1]; int head[N],nxt[M<<1],tot=0; void adde(int f,int t,int d) { e[++tot]=(edge){f,t,d}; nxt[tot]=head[f]; head[f]=tot; } int fa[N],deep[N],siz[N],hson[N],top[N],dfn[N],rank[N],w[N],tim=0; int tmp[N]; void dfs1(int t,int f) { fa[t]=f; deep[t]=deep[f]+1; dfn[++tim]=t; for(int i=head[t];i;i=nxt[i]) { int v=e[i].to; if(v!=f) { w[v]=e[i].dis; rank[v]=rank[t]+w[v]; dfs1(v,t); siz[t]+=siz[v]; if(!hson[t]||siz[v]>siz[hson[t]]) hson[t]=v; } } } void dfs2(int t,int tp) { top[t]=tp; if(!hson[t]) return; dfs2(hson[t],tp); for(int i=head[t];i;i=nxt[i]) { int v=e[i].to; if(v!=fa[t]&&v!=hson[t]) dfs2(v,v); } } int lca(int x,int y) { int fx=top[x],fy=top[y]; while(fx!=fy) { if(deep[fx]<deep[fy]) swap(x,y),swap(fx,fy); x=fa[fx],fx=top[x]; } return deep[x]<deep[y]?x:y; } struct node{ int from,to,lcaa,dis; }p[M]; bool check(int mid) { memset(tmp,0,sizeof(tmp)); int cnt=0; int D=0; for(int i=1;i<=m;i++) { if(p[i].dis>mid) { cnt++; D=max(D,p[i].dis); tmp[p[i].from]++,tmp[p[i].to]++; tmp[p[i].lcaa]-=2; } } if(!cnt) return true; for(int i=n;i>=1;i--) tmp[fa[dfn[i]]]+=tmp[dfn[i]]; for(int i=1;i<=n;i++) { if(tmp[i]==cnt&&D-w[i]<=mid) return true; } return false; } int main() { n=read(),m=read(); int a,b,c; for(int i=1;i<=n-1;i++) { a=read(),b=read(),c=read(); adde(a,b,c); adde(b,a,c); } dfs1(1,0); dfs2(1,1); for(int i=1;i<=m;i++) { a=read(),b=read(); p[i].from=a,p[i].to=b; p[i].lcaa=lca(a,b); p[i].dis=rank[a]+rank[b]-2*rank[p[i].lcaa]; } int l=0,r=1e9+7,mid; while(r-l>1) { mid=l+r>>1; if(check(mid)) r=mid; else l=mid; } printf("%d ",r); return 0; }