- 分组函数作用于一组数据,并对一组数据返回一个值。
组函数类型
- AVG
- COUNT
- MAX
- MIN
- STDDEV
- SUM
组函数语法
SELECT [column,] group_function(column), ... FROM table [WHERE condition] [GROUP BY column] [ORDER BY column];
AVG(平均值)和 SUM (合计)函数
- 可以对数值型数据使用AVG 和 SUM 函数。
SELECT AVG(salary), MAX(salary), MIN(salary), SUM(salary) FROM employees WHERE job_id LIKE '%REP%';

COUNT(计数)函数
- COUNT(*) 返回表中记录总数,适用于任意数据类型。
SELECT COUNT(*) FROM employees WHERE department_id = 50;

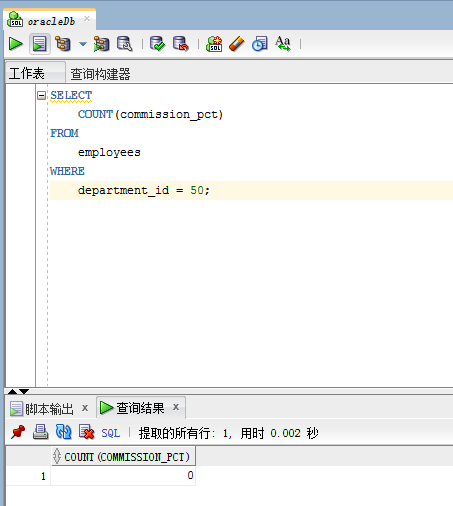
- COUNT(expr) 返回expr不为空的记录总数。
SELECT COUNT(commission_pct) FROM employees WHERE department_id = 50;
组函数与空值
- 组函数忽略空值。
示例:
SELECT AVG(commission_pct) FROM employees;

示例
SELECT AVG(commission_pct), SUM(commission_pct) / 107, SUM(commission_pct) / COUNT(commission_pct) FROM employees

在组函数中使用NVL函数
NVL函数使分组函数无法忽略空值。
SELECT AVG(nvl(commission_pct,0) ) FROM employees;

DISTINCT 关键字
- COUNT(DISTINCT expr)返回expr非空且不重复的记录总数
SELECT COUNT(DISTINCT department_id) FROM employees;

分组数据
- 可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column) FROM table [WHERE condition] [GROUP BY group_by_expression] [ORDER BY column];
- 明确:WHERE一定放在FROM后面
GROUP BY 子句
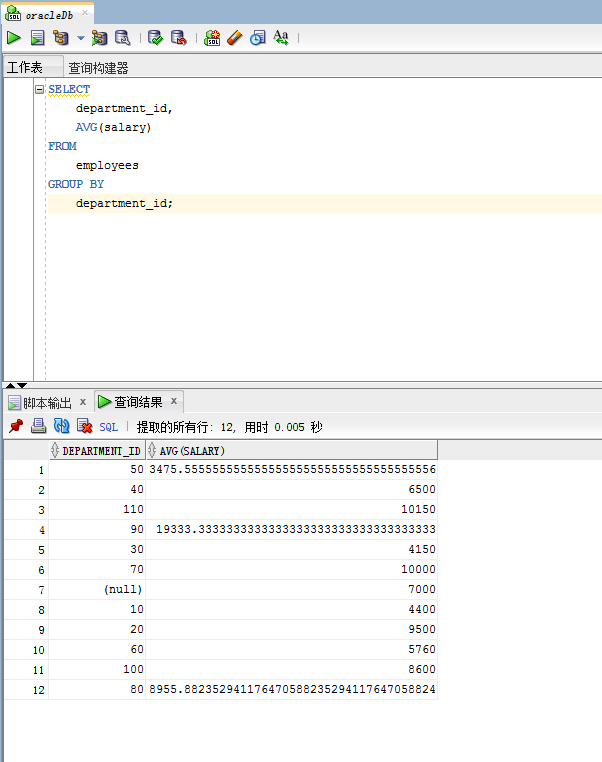
- 在SELECT 列表中所有未包含在组函数中的列都应该包含在 GROUP BY 子句中。
SELECT department_id, AVG(salary) FROM employees GROUP BY department_id;
- 包含在 GROUP BY 子句中的列不必包含在SELECT 列表中
SELECT AVG(salary) FROM employees GROUP BY department_id;

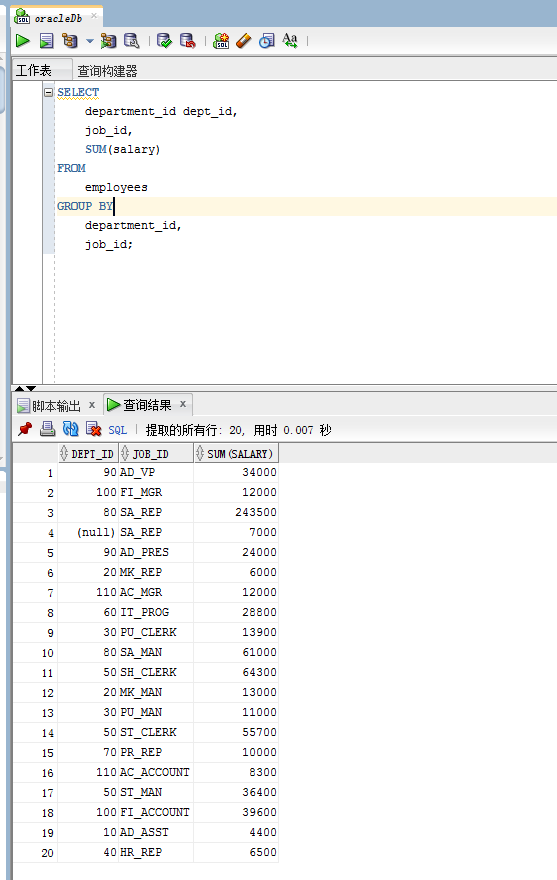
在GROUP BY子句中包含多个列
示例
SELECT department_id dept_id, job_id, SUM(salary) FROM employees GROUP BY department_id, job_id;
非法使用组函数
- 所有包含于SELECT 列表中,而未包含于组函数中的列都必须包含于 GROUP BY 子句中。
SELECT department_id, COUNT(last_name) FROM employees; SELECT department_id, COUNT(last_name) GROUP BY 子句中缺少列
- 不能在 WHERE 子句中使用组函数。
- 可以在 HAVING 子句中使用组函数。
SELECT department_id, AVG(salary) FROM employees WHERE AVG(salary) > 8000 GROUP BY department_id; WHERE 子句中不能使用组函数
过滤分组: HAVING 子句
使用 HAVING 过滤分组:
- 行已经被分组。
- 使用了组函数。
- 满足HAVING 子句中条件的分组将被显示。
SELECT column, group_function FROM table [WHERE condition] [GROUP BY group_by_expression] [HAVING group_condition] [ORDER BY column];
示例
SELECT department_id, MAX(salary) FROM employees GROUP BY department_id HAVING MAX(salary) > 10000;

嵌套组函数
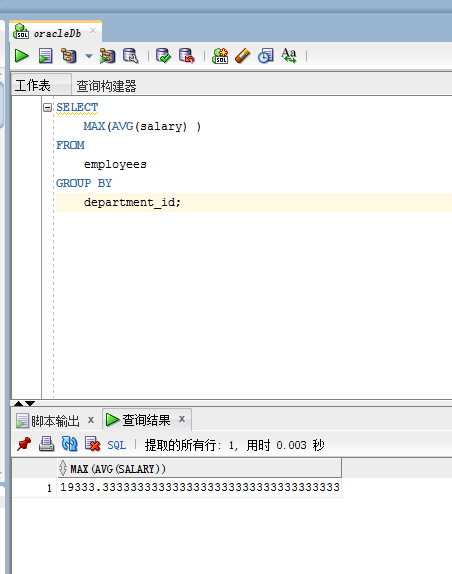
例如:显示各部门平均工资的最大值
SELECT MAX(AVG(salary) ) FROM employees GROUP BY department_id;