1、【yolov1】
第一步:将图像划分为S*S的栅格(grid cell),这里分成了7*7的grid cell。栅格的任务是:检测中心落在该栅格中的物体(注意,栅格中心未必与物体的中心重合,这个一定要明确,对后面的理解才不会产生影响)。
第二步:一个grid cell 可以预测B个bounding boxes(包围盒,以下简称bbox),包括预测bbox的confidence scores。bbox有五个预测值,分别是x,y(代表预测的bbox的中心与grid cell 边界的边界的相对值),w,h(代表预测的bbox的width/height相对于整个图像width,height的比例),confidence(代表预测的bbox和ground truth box的IOU值)。confidence = Pr(object) * IOU 一个bbox对应一个confidence score,如果grid cell里面没有object,confidence就是0,如果有,则confidence score等于预测的box和ground truth的IOU值,见上面公式。在此解释一下IOU的意思,ground truth box是物体实际的位置,而IOU=bbox与ground truth box的交集/二者的并集,即交并比(重叠度)。
第三步:每个grid cell 还要预测C个conditional class probability (条件类别概率),即Pr (Class|Object)。即预测出,在grid cell包含object的条件下,该object属于某个类的概率。注意,一个grid cell只需要预测一组(C个)类的概率,而不需要考虑bbox的数量。因为一个grid cell预测的B个bbox框住的都是同一个物体。也就是说,类别概率是针对grid cell的。在本文中取S=7,B=2,C=20(因为PASCAL 数据集有20个类别),所以最后有7*7*30(30=B*5+C,每个bbox有5个预测值)个tensor。
测试阶段:将每个grid cell的conditional class probability与每个bbox的confidence相乘:
Pr(Class | Object) * Pr(Object) * IOU = Pr(Class) * IOU
每个bbox的confidence和每个类别的score相乘,得到每个bbox属于哪一类的confidence score。也就是说最后会得到20*(7*7*2)=20*98的score矩阵,括号里面是bbox的数量,20代表类别。接下来的操作都是20个类别轮流进行:在某个类别中(即矩阵的某一行),将得分少于阈值(0.2)的设置为0,然后再按得分从高到低排序。最后再用NMS算法去掉重复率较大的bbox(NMS:针对某一类别,选择得分最大的bbox,然后计算它和其它bbox的IOU值,如果IOU大于0.5,说明重复率较大,该得分设为0,如果不大于0.5,则不改;这样一轮后,在选择剩下的score里面最大的那个bbox,然后计算该bbox和其它bbox的IOU,重复以上过程直到最后)。最后每个bbox的20个score取最大的score,如果这个score大于0,那么这个bbox就是这个socre对应的类别(矩阵的行),如果小于0,说明这个bbox里面没有物体,跳过即可。
2、【yolov2 (https://blog.csdn.net/u014696921/article/details/65626751 参考) 使用的一些技巧:】
(1)Better
batch Normalization:在卷基层后面增加了batch Normalization,去掉了dropout层,mAP提升2%。
High ResolutionClassifier:x训练网络的时候将网络从224*224变为448*448,当然后续为了保证特征图中只有奇数个定位位置,从而保证只有一个中心细胞,网络最终设置为416*416。最终实现了4%的mAP提升。
Convoutional with AnchorBoxes:作者吸收了faster RCNN中RPN的思想,去掉了yolov1中的全连接层,加入了anchor boxes,这样做的目的就是得到更高的召回率,当然召回率高了,mAP就会相应的下降,这也是人之常情。最终,yolov1只有98个边界框,yolov2达到了1000多个。mAP由69.5下降到69.2,下降了0.3,召回率由81%提升到88%,提升7%。
Dimension Clusters(维度聚类):这里作者提出了kmeans聚类,这里的K作者取值为5,这样会在模型复杂度和召回率之间达到一个好的折中。并且使用聚类的中心代替Anchor,最后使用欧式距离进行边界框优先权的衡量,欧式距离公式如下所示,距离越小说明优先权越高。在k为5 的条件下,Avg IOU从60.9提升到了61.0。在k为9的的条件下Avg IOU提升为67.2
Direction locationprediction:引入了anchor boxes就会产生模型不稳定的问题,该问题产生于边界框位置的预测。简单的解释,如果训练的图片中的物体一张是在左面,下一张又在右面,就会产生这样的波动,显然的这个过程是不受控制的,毕竟图片中的物体位置他在哪里就在哪里。这里作者,变换了个思路,把最终预测的相对于anchor的边界框的相关系数变为预测相对于grid cell(yolo v1的机制)的相关系数,使得输出的系数在0-1直接波动,如此就解决了波动的问题。最终,使用维度聚类和直接预测边界框中心比使用anchor boxes提升了5%的mAP。
Multi-Scale Training:这里作者提出的训练方法也很独特,在训练过程中就每隔10batches,随机的选择另外一种尺度进行训练,这里,作者给出的训练尺度为{320,352,……,608},这个训练的方法,使得最终得到的模型可以对不同分辨率的图像都能达到好的检测效果。(多尺度训练对显卡的内存有要求,由参数random控制, 目前训练都是关闭这个选项不能会报 cuda out of memory)
Fine-Grained Features(细粒度特征)
上述网络上的修改使YOLO最终在13 * 13的特征图上进行预测,虽然这足以胜任大尺度物体的检测,但是用上细粒度特征的话,这可能对小尺度的物体检测有帮助。Faser R-CNN和SSD都在不同层次的特征图上产生区域建议(SSD直接就可看得出来这一点),获得了多尺度的适应性。这里使用了一种不同的方法,简单添加了一个转移层( passthrough layer),这一层要把浅层特征图(分辨率为26 * 26,是底层分辨率4倍)连接到深层特征图。这个转移层也就是把高低两种分辨率的特征图做了一次连结,连接方式是叠加特征到不同的通道而不是空间位置,类似于Resnet中的identity mappings。这个方法把26 * 26 * 512的特征图连接到了13 * 13 * 2048的特征图,这个特征图与原来的特征相连接。YOLO的检测器使用的就是经过扩张的特征图,它可以拥有更好的细粒度特征,使得模型的性能获得了1%的提升。(这段理解的也不是很好,要看到网络结构图才能清楚)
(2)Faster
这里,vgg16虽然精度足够好,但是模型比较大,网络传输起来比较费时间,因此,作者提出了一个自己的模型,Darknet-19。而darknetv2也正式已Darknet-19作为pretrained model训练起来的。
(3)Stronger
这里作者的想法也很新颖,解决了2个不同数据集相互排斥(mutualy exclusive)的问题。作者提出了WordTree,使用该树形结构成功的解决了不同数据集中的排斥问题。使用该树形结构进行分层的预测分类,在某个阈值处结束或者最终达到叶子节点处结束。下面这副图将有助于WordTree这个概念的理解。
3、【yolov3使用的一些技巧:】
(1)Darknet-53
(2)YOLOv3不使用Softmax对每个框进行分类,用逻辑回归替代softmax作为分类器:主要考虑因素有两个:Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。Softmax可被独立的多个logistic分类器替代,且准确率不会下降。(在阈值较低的情况下可能会引入相同区域内可能出现多个标签)且分类损失采用binary cross-entropy loss
(3)多尺度预测 , 三个尺度的输出: 13 x 13 x [3 * (4 + 1 + 6)] = 13 x 13 x 33 同理 26 x 26 x 33 52 x 52 x 33 每个尺度预测3个框 再由每个框去预测对应的条件类别概率(位置 置信度 类别)
4、【从零开始PyTorch项目:YOLO v3目标检测实现 (http://www.sohu.com/a/229164696_129720)】
(1)YOLOv3 仅使用卷积层,这就使其成为全卷积神经网络(FCN)。它拥有 75 个卷积层,还有跳过连接和上采样层。它不使用任何形式的池化,使用步幅为 2 的卷积层对特征图进行下采样。这有助于防止通常由池化导致的低级特征丢失。
(2)典型地(对于所有目标检测器都是这种情况),卷积层所学习的特征会被传递到分类器/回归器,从而进行预测(边界框的坐标、类别标签等)。
(3)中心坐标,注意:我们使用 sigmoid 函数进行中心坐标预测。这使得输出值在 0 和 1 之间。原因如下:正常情况下,YOLO 不会预测边界框中心的确切坐标。它预测:与预测目标的网格单元左上角相关的偏移;使用特征图单元的维度(1)进行归一化的偏移。以我们的图像为例。如果中心的预测是 (0.4, 0.7),则中心在 13 x 13 特征图上的坐标是 (6.4, 6.7)(红色单元的左上角坐标是 (6,6))。但是,如果预测到的 x,y 坐标大于 1,比如 (1.2, 0.7)。那么中心坐标是 (7.2, 6.7)。注意该中心在红色单元右侧的单元中,或第 7 行的第 8 个单元。这打破了 YOLO 背后的理论,因为如果我们假设红色框负责预测目标狗,那么狗的中心必须在红色单元中,不应该在它旁边的网格单元中。
(4)类别置信度表示检测到的对象属于某个类别的概率(如狗、猫、香蕉、汽车等)。在 v3 之前,YOLO 需要对类别分数执行 softmax 函数操作。但是,YOLO v3 舍弃了这种设计,作者选择使用 sigmoid 函数。因为对类别分数执行 softmax 操作的前提是类别是互斥的。简言之,如果对象属于一个类别,那么必须确保其不属于另一个类别。这在我们设置检测器的 COCO 数据集上是正确的。但是,当出现类别「女性」(Women)和「人」(Person)时,该假设不可行。这就是作者选择不使用 Softmax 激活函数的原因。
(5)在不同尺度上的预测
YOLO v3 在 3 个不同尺度上进行预测。检测层用于在三个不同大小的特征图上执行预测,特征图步幅分别是 32、16、8。这意味着,当输入图像大小是 416 x 416 时,我们在尺度 13 x 13、26 x 26 和 52 x 52 上执行检测。该网络在第一个检测层之前对输入图像执行下采样,检测层使用步幅为 32 的层的特征图执行检测。随后在执行因子为 2 的上采样后,并与前一个层的特征图(特征图大小相同)拼接。另一个检测在步幅为 16 的层中执行。重复同样的上采样步骤,最后一个检测在步幅为 8 的层中执行。在每个尺度上,每个单元使用 3 个锚点预测 3 个边界框,锚点的总数为 9(不同尺度的锚点不同)。作者称这帮助 YOLO v3 在检测较小目标时取得更好的性能,而这正是 YOLO 之前版本经常被抱怨的地方。上采样可以帮助该网络学习细粒度特征,帮助检测较小目标。
(6)输出处理
对于大小为 416 x 416 的图像,YOLO 预测 ((52 x 52) + (26 x 26) + 13 x 13)) x 3 = 10647 个边界框。但是,我们的示例中只有一个对象——一只狗。那么我们怎么才能将检测次数从 10647 减少到 1 呢?目标置信度阈值:首先,我们根据它们的 objectness 分数过滤边界框。通常,分数低于阈值的边界框会被忽略。非极大值抑制:非极大值抑制(NMS)可解决对同一个图像的多次检测的问题。例如,红色网格单元的 3 个边界框可以检测一个框,或者临近网格可检测相同对象。
(7)跳过连接层
[shortcut]
from= -3
activation=linear
跳过连接与残差网络中使用的结构相似,参数 from 为-3 表示捷径层的输出会通过将之前层的和之前第三个层的输出的特征图与模块的输入相加而得出。
(8)路由层(Route)
[route]
layers = -4
[route]
layers = -1, 61
路由层需要一些解释,它的参数 layers 有一个或两个值。当只有一个值时,它输出这一层通过该值索引的特征图。在我们的实验中设置为了-4,所以层级将输出路由层之前第四个层的特征图。当层级有两个值时,它将返回由这两个值索引的拼接特征图。在我们的实验中为-1 和 61,因此该层级将输出从前一层级(-1)到第 61 层的特征图,并将它们按深度拼接。
(9)YOLO 层级对应于上文所描述的检测层级。参数 anchors 定义了 9 组锚点,但是它们只是由 mask 标签使用的属性所索引的锚点。这里,mask 的值为 0、1、2 表示了第一个、第二个和第三个使用的锚点。而掩码表示检测层中的每一个单元预测三个框。总而言之,我们检测层的规模为 3,并装配总共 9 个锚点。
(10)理解权重文件
官方的权重文件是一个二进制文件,它以序列方式储存神经网络权重。我们必须小心地读取权重,因为权重只是以浮点形式储存,没有其它信息能告诉我们到底它们属于哪一层。所以如果读取错误,那么很可能权重加载就全错了,模型也完全不能用。因此,只阅读浮点数,无法区别权重属于哪一层。因此,我们必须了解权重是如何存储的。首先,权重只属于两种类型的层,即批归一化层(batch norm layer)和卷积层。这些层的权重储存顺序和配置文件中定义层级的顺序完全相同。所以,如果一个 convolutional 后面跟随着 shortcut 块,而 shortcut 连接了另一个 convolutional 块,则你会期望文件包含了先前 convolutional 块的权重,其后则是后者的权重。
5、
(1)yolo标签值意义:
计算标签值函数中:返回值为ROI中心点相对于图片大小的比例坐标,和ROI的w、h相对于图片大小的比例
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
(2)根据网络层预测值计算输出值:(网络层预测坐标:tx ,ty , tw , th 都是相对于预测单元的比例)(cx , cy为预测单元左上角相对于图片左上角偏移值 , pw , ph为先验框的宽度和高度)
b.x = σ(tx) + cx
b.y = σ(ty) + cy
b.w = pw*exp(tw)
b.h = ph*exp(th)
6、YOLOV3中的mask作用
Every
layer has to know about all of the anchor boxes but is only predicting
some subset of them. This could probably be named something better but
the mask tells the layer which of the bounding boxes it is responsible
for predicting. The first yolo layer predicts 6,7,8 because those are the largest boxes and it's at the coarsest scale. The 2nd yolo layer predicts some smallers ones, etc.The layer assumes if it isn't passed a mask that it is responsible for all the bounding boxes, hence the ifstatement thing.
7、Anchor box作用是
Here's
a quick explanation based on what I understand (which might be wrong
but hopefully gets the gist of it). After doing some clustering studies
on ground truth labels, it turns out that most bounding boxes have
certain height-width ratios. So instead of directly predicting a
bounding box, YOLOv2 (and v3) predict off-sets from a predetermined set
of boxes with particular height-width ratios - those predetermined set
of boxes are the anchor boxes.
Anchors are initial sizes (width, height) some of which (the closest to the object size) will be resized to the object size - using some outputs from the neural network (final feature map):
Lines 88 to 89 in 6f6e475
-
x[...]- outputs of the neural network -
biases[...]- anchors -
b.wandb.hresult width and height of bounded box that will be showed on the result image
Thus, the network should not predict the final size of the object, but should only adjust the size of the nearest anchor to the size of the object.
In Yolo v3 anchors (width, height) - are sizes of objects on the image that resized to the network size (width= and height= in the cfg-file).
In
Yolo v2 anchors (width, height) - are sizes of objects relative to the
final feature map (32 times smaller than in Yolo v3 for default
cfg-files).
8、yolov3核心思想:
首先通过特征提取网络对输入的图像提取特征,得到一定大小的feature map 比如 13X13,然后将输入的图像分为13X13个grid cell,然后如果groundtruth中的某个物体的中心坐标落到那个grid cell中就由该grid cell预测该物体,每个grid cell 都会预测固定数量的bounding box (v1 :2个,V2 :5个 ,V3 : 3个)这几个bounding box的初始size是不一样的),那么这几个bounding box中最终是由哪一个来预测该object?答案是:这几个bounding box中只有和ground truth的IOU最大的bounding box才是用来预测该物体。简单讲就是下面这个截图的公式,tx、ty、tw、th就是模型的预测输出。cx和cy表示grid cell的坐标,比如某层的feature map大小是13X13,那么grid cell就有13*13个,第0行第1列的grid cell的坐标cx就是0,cy就是1。pw和ph表示预测前bounding box的size。bx、by。bw和bh就是预测得到的bounding box的中心的坐标和size。坐标的损失采用的是平方误差损失。
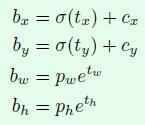
因此网络结构上就将原来用于单标签多分类的softmax层换成用于多标签多分类的逻辑回归层。首先说明一下为什么要做这样的修改,原来分类网络中的softmax层都是假设一张图像或一个object只属于一个类别,但是在一些复杂场景下,一个object可能属于多个类,比如你的类别中有woman和person这两个类,那么如果一张图像中有一个woman,那么你检测的结果中类别标签就要同时有woman和person两个类,这就是多标签分类,需要用逻辑回归层来对每个类别做二分类。逻辑回归层主要用到sigmoid函数,该函数可以将输入约束在0到1的范围内,因此当一张图像经过特征提取后的某一类输出经过sigmoid函数约束后如果大于0.5,就表示属于该类。
原来的YOLO
v2有一个层叫:passthrough layer,假设最后提取的feature
map的size是13X13,那么这个层的作用就是将前面一层的26X26的feature map和本层的13X13的feature
map进行连接,有点像ResNet。
当时这么操作也是为了加强YOLO算法对小目标检测的精确度。这个思想在YOLO
v3中得到了进一步加强,在YOLO
v3中采用类似FPN的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26X26和52X52),在多个scale的feature
map上做检测,对于小目标的检测效果提升还是比较明显的。前面提到过在YOLO v3中每个grid cell预测3个bounding
box,看起来比YOLO v2中每个grid cell预测5个bounding box要少,其实不是!因为YOLO
v3采用了多个scale的特征融合,所以boundign
box的数量要比之前多很多,以输入图像为416X416为例:(13X13+26X26+52X52)X3和13X13X5相比哪个更多应该很清晰了。
YOLO v3 在 3 个不同尺度上进行预测。检测层用于在三个不同大小的特征图上执行预测,特征图步幅分别是 32、16、8。这意味着,当输入图像大小是 416 x 416 时,我们在尺度 13 x 13、26 x 26 和 52 x 52 上执行检测。
该网络在第一个检测层之前对输入图像执行下采样,检测层使用步幅为
32 的层的特征图执行检测。随后在执行因子为 2 的上采样后,并与前一个层的特征图(特征图大小相同)拼接。另一个检测在步幅为 16
的层中执行。重复同样的上采样步骤,最后一个检测在步幅为 8 的层中执行。
在每个尺度上,每个单元使用3个锚点预测3个边界框,锚点的总数为9(不同尺度的锚点不同)。
对于大小为
416 x 416 的图像,YOLO 预测 ((52 x 52) + (26 x 26) + 13 x 13)) x 3 = 10647
个边界框。但是,我们的示例中只有一个对象——一只狗。那么我们怎么才能将检测次数从 10647 减少到 1 呢?
目标置信度阈值:首先,我们根据它们的 objectness 分数过滤边界框。通常,分数低于阈值的边界框会被忽略。
非极大值抑制:非极大值抑制(NMS)可解决对同一个图像的多次检测的问题。例如,上图红色网格单元的 3 个边界框可以检测一个框,或者临近网格可检测相同对象。
一方面基本采用全卷积(YOLO
v2中采用pooling层做feature map的sample,这里都换成卷积层来做了),另一方面引入了residual结构(YOLO
v2中还是类似VGG那样直筒型的网络结构,层数太多训起来会有梯度问题,所以Darknet-19也就19层,因此得益于ResNet的residual结构,训深层网络难度大大减小,因此这里可以将网络做到53层,精度提升比较明显)。
Darknet-53只是特征提取层,源码中只使用了pooling层前面的卷积层来提取特征,因此multi-scale的特征融合和预测支路并没有在该网络结构中体现,具体信息可以看源码:https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg。预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3X(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示objectness score。模型训练方面还是采用原来YOLO v2中的multi-scale training
