date: 2015-09-06 19:45:38
Java最基本的数据结构有数组和链表。
数组的特点是空间连续(大小固定)、寻址迅速,但是插入和删除时需要移动元素,所以查询快,增加删除慢。
链表恰好相反,可动态增加或减少空间以适应新增和删除元素,但查找时只能顺着一个个节点查找,所以增加删除快,查找慢。
那么问题来了,有没有一种综合数组和链表优点的数据结构呢?
The answer is HashMap!
HashMap
首先看看HashMap是怎么个存储方式,下图无明确作者,在此不添加Reference了! 尊重原创!
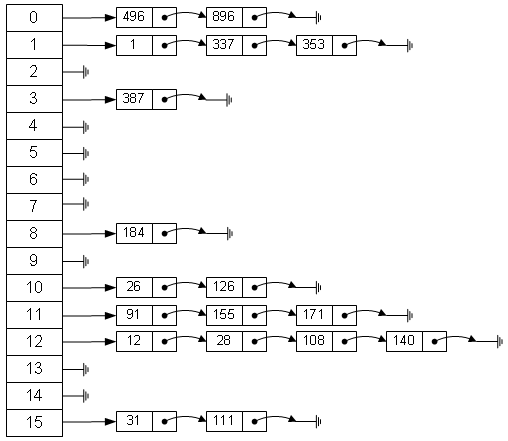
如图,hash表就是由数据+链表组成的。首先数组每个元素存储一个链表节点,通过一定算法,比如hash(key)%length
来存储后续的节点,比如31%16=15,就放到元素15开头的链表中。
看了HashMap的源码,其实HashMap是基于一个线性的数组结构来实现的:
o n e: HashMap内部定义了一个Entry<k,v>数组
t w o: static class Entry<k,v> implements Map<k,v>,并且具有key/value/next等属性,类似JavaBean
three: 也就是,Entry[]数据存储了Map<k,v>这种结构的数据
分析一段源码,来自HashMap中的put()方法:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
其实思路并不复杂,通过一个hash算法得到hash值,通过hash值得到Entry数组下标index,然后找到数组位置,通过链式结构匹配Key值,get it!
那么,问题在这,这是源码里的hash算法:
static int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
我真是惊呆了,费脑筋~
虽然能猜出来其作用,大体大概是防止hash冲突,但是具体为什么这样,而不是那样,我解释不清楚了=。=!
计算index的方法,倒是很清新,用到了效率最高的位运算,其中length-1防止数组越界:
static int indexFor(int h, int length) { return h & (length-1); }
另,解决hash冲突的方法:
- 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
- 再哈希法
- 链地址法
- 建立一个公共溢出区
显然HashMap采用的是链地址法
EOF