https://zhuanlan.zhihu.com/p/28871960
深度学习模型中的卷积神经网络(Convolution Neural Network, CNN)近年来在图像领域取得了惊人的成绩,CNN直接利用图像像素信息作为输入,最大程度上保留了输入图像的所有信息,通过卷积操作进行特征的提取和高层抽象,模型输出直接是图像识别的结果。这种基于”输入-输出”直接端到端的学习方法取得了非常好的效果,得到了广泛的应用。
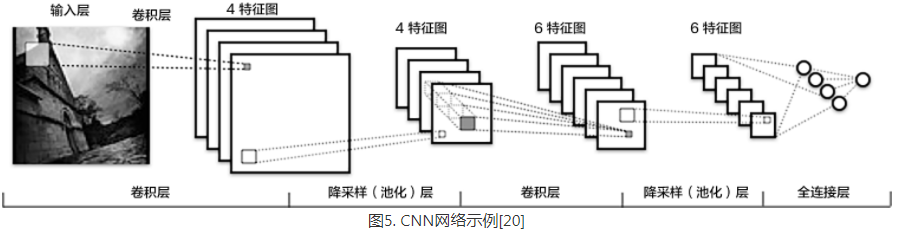
- 卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。
- 池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
- 全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。
- 非线性变化: 卷积层、全连接层后面一般都会接非线性变化层(探测层),例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。 ReLu激活函数: $f(x) = max(0, x)$
- Dropout [10] : 在模型训练阶段随机让一些隐层节点不工作(权重置为0),提高网络的泛化能力,一定程度上防止过拟合。
另外,在训练过程中由于每层参数不断更新,会导致下一次输入分布发生变化,这样导致训练过程需要精心设计超参数。如2015年Sergey Ioffe和Christian Szegedy提出了Batch Normalization (BN)算法 [14] 中,每个batch对网络中的每一层特征都做归一化,使得每层分布相对稳定。BN算法不仅起到一定的正则作用,而且弱化了一些超参数的设计。经过实验证明,BN算法加速了模型收敛过程,在后来较深的模型中被广泛使用。
接下来我们主要介绍VGG,GoogleNet和ResNet网络结构。(需要进一步了解,各自的优缺点和参数细节,看相应的论文)
VGG
牛津大学VGG(Visual Geometry Group)组在2014年ILSVRC提出的模型被称作VGG模型 [11] 。该模型相比以往模型进一步加宽和加深了网络结构,它的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,五组卷积操作中卷积核的数目由较浅组的64增多到最深组的512(feature map的数目),同一组中的卷积核的数目相同,每组卷积操作由(若干组conv)->BN->ReLu->Dropout和一组pooling组成。五组卷积之后接两层全连接层【两层或以上fully connected layer就可以很好地解决非线性问题】,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,下图展示一个16层的网络结构。VGG模型结构相对简洁,提出之后也有很多文章基于此模型进行研究,如在ImageNet上首次公开超过人眼识别的模型[19]就是借鉴VGG模型的结构。
https://arxiv.org/pdf/1405.3531.pdf [11]
Convolutional neural networks details
CNN training
CNN fine-tuning on the target dataset
Low-dimensional CNN feature training
Data augmentation details
代码:
http://www.robots.ox.ac.uk/~vgg/research/deep_eval
http://www.robots.ox.ac.uk/~vgg/software/deep_eval/
http://x-algo.cn/index.php/2017/01/08/1471/
def vgg_bn_drop(input): ''' conv_block为一组卷积网络,卷积核大小为3x3,池化窗口大小为2x2,窗口滑动大小为2,groups决定每组VGG模块 是几次连续的卷积操作,dropouts指定Dropout操作的概率.num_channels是输入的通道数(卷积核的数目),一般图像作为第一层输入有RGB 3个通道 img_conv_group是在paddle.networks中预定义的模块,由若干组 Conv->BN->ReLu->Dropout 和 一组 Pooling 组成 ''' def conv_block(ipt, num_filter, groups, dropouts, num_channels=None): return paddle.networks.img_conv_group( input=ipt, num_channels=num_channels, pool_size=2, pool_stride=2, conv_num_filter=[num_filter] * groups, conv_filter_size=3, conv_act=paddle.activation.Relu(), conv_with_batchnorm=True, conv_batchnorm_drop_rate=dropouts, pool_type=paddle.pooling.Max()) # 五组卷积操作 conv1 = conv_block(input, 64, 2, [0.3, 0], 3) conv2 = conv_block(conv1, 128, 2, [0.4, 0]) conv3 = conv_block(conv2, 256, 3, [0.4, 0.4, 0]) conv4 = conv_block(conv3, 512, 3, [0.4, 0.4, 0]) conv5 = conv_block(conv4, 512, 3, [0.4, 0.4, 0]) # dropout层 drop = paddle.layer.dropout(input=conv5, dropout_rate=0.5) # 两层512维的全连接:fc1, fc2 fc1 = paddle.layer.fc(input=drop, size=512, act=paddle.activation.Linear()) bn = paddle.layer.batch_norm( input=fc1, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) fc2 = paddle.layer.fc(input=bn, size=512, act=paddle.activation.Linear()) return fc2
全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽 。卷积核数目等于全连接层的输出节点数。
如何把3x3x5的输出,转换成1x4096的形式:https://www.zhihu.com/question/41037974
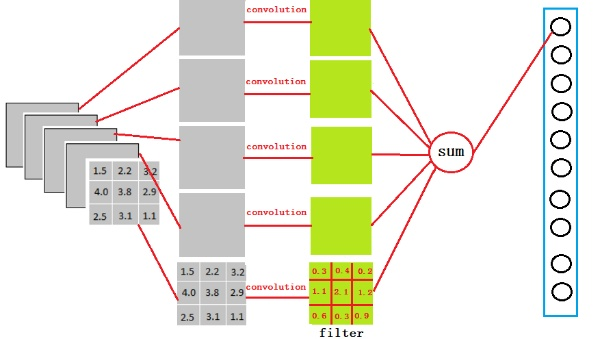
我们用一个3x3x5的filter【默认卷积核的channel等于输入的channel】 去卷积激活函数的输出,得到的结果就是一个fully connected layer 的一个神经元的输出,这个输出就是一个值。由于我们有4096个神经元,我们实际就是用一个3x3x5x4096的卷积层去卷积激活函数的输出。
卷积层后的全连接层的作用是把特征representation整合到一起,输出为一个值,大大减少特征位置对分类带来的影响。

GoogleNet
GoogleNet [12] 在2014年ILSVRC的获得了冠军,在介绍该模型之前我们先来了解NIN(Network in Network)模型 [13] 和Inception模块,因为GoogleNet模型由多组Inception模块组成,模型设计借鉴了NIN的一些思想。
NIN模型主要有两个特点:1) 引入了多层感知卷积网络(Multi-Layer Perceptron Convolution, MLPconv)代替一层线性卷积网络。MLPconv是一个微小的多层卷积网络,即在线性卷积后面增加若干层1x1的卷积,这样可以提取出高度非线性特征。2) 传统的CNN最后几层一般都是全连接层,参数较多。而NIN模型设计最后一层卷积层包含类别维度大小的特征图,然后采用全局均值池化(Avg-Pooling)替代全连接层,得到类别维度大小的向量,再进行分类。这种替代全连接层的方式有利于减少参数。
Inception模块如下图7所示,图(a)是最简单的设计,输出是3个卷积层和一个池化层的特征拼接(池化层的stride是多少,降维怎么办?)。这种设计的缺点是池化层不会改变特征通道数,拼接后会导致特征的通道数较大,经过几层这样的模块堆积后,通道数会越来越大,导致参数和计算量也随之增大。为了改善这个缺点,图(b)引入3个1x1卷积层进行降维,所谓的降维就是减少通道数,同时如NIN模型中提到的1x1卷积也可以修正线性特征。
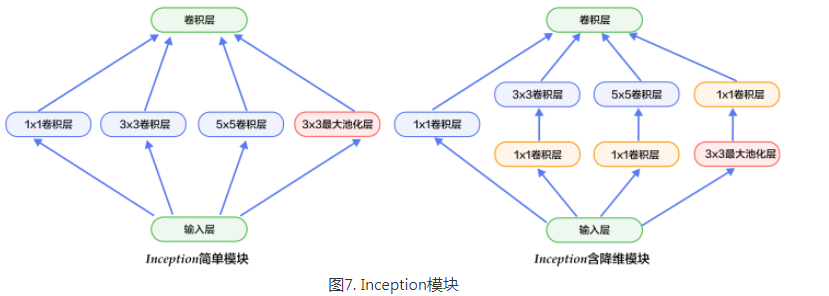
GoogleNet由多组Inception模块堆积而成。另外,在网络最后也没有采用传统的多层全连接层,而是像NIN网络一样采用了均值池化层;但与NIN不同的是,池化层后面接了一层到类别数映射的全连接层。除了这两个特点之外,由于网络中间层特征也很有判别性,GoogleNet在中间层添加了两个辅助的softmax,在后向传播中增强梯度并且增强正则化(怎么增强正则化?),而整个网络的损失函数是这个三个分类器的损失加权求和。
GoogleNet整体网络结构如图8所示,总共22层网络:开始由3层普通的卷积组成;接下来由三组子网络组成,第一组子网络包含2个Inception模块,第二组包含5个Inception模块,第三组包含2个Inception模块;然后接均值池化层、全连接层。
上面介绍的是GoogleNet第一版模型(称作GoogleNet-v1)。GoogleNet-v2 [14] 引入BN层;GoogleNet-v3 [16] 对一些卷积层做了分解,进一步提高网络非线性能力和加深网络;GoogleNet-v4 [17] 引入下面要讲的ResNet设计思路。从v1到v4每一版的改进都会带来准确度的提升,介于篇幅,这里不再详细介绍v2到v4的结构。
ResNet
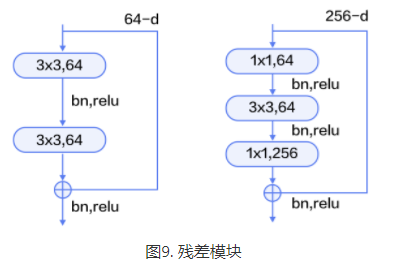
ResNet(Residual Network) [15] 是2015年ImageNet图像分类、图像物体定位和图像物体检测比赛的冠军。针对训练卷积神经网络时加深网络导致准确度下降的问题【梯度消失】,ResNet提出了采用残差学习。在已有设计思路(BN, 小卷积核,全卷积网络)的基础上,引入了残差模块。每个残差模块包含两条路径,其中一条路径是输入特征的直连通路,另一条路径对该特征做两到三次卷积操作得到该特征的残差,最后再将两条路径上的特征相加。
残差模块如图9所示,左边是基本模块连接方式,由两个输出通道数相同的3x3卷积组成。右边是瓶颈模块(Bottleneck)连接方式,之所以称为瓶颈,是因为上面的1x1卷积用来降维(图示例即256->64),下面的1x1卷积用来升维(图示例即64->256),这样中间3x3卷积的输入和输出通道数都较小(图示例即64->64)。
一张500 * 500且厚度depth为100 的图片在20个filter上做1*1的卷积,那么结果的大小为500*500*20。1*1的卷积核是要和要处理的数据通道保持一致的,要处理的如果是RGB原始图,那么1*1卷积核应该是1*1*3,灰度图是1*1,(纯粹线性变换),要处理的如果是N个特征图对应的数据,那么1*1卷积核大小应该是1*1*N了。filter的数量控制了下一层的channel数
如果卷积的输出输入都只是一个平面,那么1x1卷积核并没有什么意义,它是完全不考虑像素与周边其他像素关系。但卷积的输出输入是长方体,所以1x1卷积实际上是对每个像素点,在不同的channels上进行线性组合(前提:channel > 1)(信息整合),且保留了图片的原有平面结构,调控depth,从而完成升维或降维的功能。
一组残差模块,由若干个残差模块堆积而成,
resnet_cifar10 的连接结构: 输入 -> 卷积层 -> 三组残差模块 -> 池化层
# conv_bn_layer : 带BN的卷积层,(img_conv -> linear) -> (bn -> relu) def conv_bn_layer(input, ch_out, filter_size, stride, padding, active_type=paddle.activation.Relu(), ch_in=None): tmp = paddle.layer.img_conv( input=input, filter_size=filter_size, num_channels=ch_in, num_filters=ch_out, stride=stride, padding=padding, act=paddle.activation.Linear(), bias_attr=False) return paddle.layer.batch_norm(input=tmp, act=active_type) # shortcut : 残差模块的”直连”路径,”直连”实际分两种形式:残差模块输入和输出特征通道数不等时,采用1x1卷积的 # 升维操作;残差模块输入和输出通道相等时,采用直连操作。 def shortcut(ipt, ch_in, ch_out, stride): if ch_in != ch_out: return conv_bn_layer(ipt, ch_out, 1, stride, 0, paddle.activation.Linear()) else: return ipt # basicblock : 一个基础残差模块,由两组3x3卷积组成的路径和一条”直连”路径组成 def basicblock(ipt, ch_in, ch_out, stride): tmp = conv_bn_layer(ipt, ch_out, 3, stride, 1) tmp = conv_bn_layer(tmp, ch_out, 3, 1, 1, paddle.activation.Linear()) short = shortcut(ipt, ch_in, ch_out, stride) return paddle.layer.addto(input=[tmp, short], act=paddle.activation.Relu()) # layer_warp : 一组残差模块,由若干个残差模块堆积而成 def layer_warp(block_func, ipt, ch_in, ch_out, count, stride): tmp = block_func(ipt, ch_in, ch_out, stride) for i in range(1, count): tmp = block_func(tmp, ch_out, ch_out, 1) return tmp ''' resnet_cifar10 的连接结构: 输入 -> 卷积层 -> 三组残差模块 -> 池化层 1、底层输入连接一层 conv_bn_layer,即带BN的卷积层。 2、然后连接3组残差模块即下面配置3组 layer_warp ,每组采用图 10 左边残差模块组成。 3、最后对网络做均值池化并返回该层。 ''' def resnet_cifar10(ipt, depth=32): # depth should be one of 20, 32, 44, 56, 110, 1202 assert (depth - 2) % 6 == 0 n = (depth - 2) / 6 nStages = {16, 64, 128} conv1 = conv_bn_layer( ipt, ch_in=3, ch_out=16, filter_size=3, stride=1, padding=1) res1 = layer_warp(basicblock, conv1, 16, 16, n, 1) res2 = layer_warp(basicblock, res1, 16, 32, n, 2) res3 = layer_warp(basicblock, res2, 32, 64, n, 2) pool = paddle.layer.img_pool( input=res3, pool_size=8, stride=1, pool_type=paddle.pooling.Avg()) return pool
神经网络参数计算:https://zhuanlan.zhihu.com/p/57437131
卷积层: $K^2 * C_i * C_0 + C_0$
其中 为卷积核大小,
为输入channel数,
为输出的channel数(也是filter的数量),算式第二项是偏置项的参数量 。(虽然一般不写偏置项,因为不会影响总参数量的数量级,但是我们为了准确起见,把偏置项的参数量也考虑进来)
BN层:$2 * C_i$, 其中$C_i$为输入的channel数
(BN层有两个需要学习的参数,平移因子和缩放因子)
全连接层:$T_i * T_0 + T_0$, $T_i$为输入向量的长度,$T_0$为输出向量的长度,其中第二项为偏置项参数量。
作者:小鸭子蛋
链接:https://www.nowcoder.com/discuss/37873?type=0&order=0&pos=28&page=1
来源:牛客网
链接:https://www.nowcoder.com/discuss/48981?type=0&order=0&pos=16&page=1
来源:牛客网