首先了解一下java内存模型(并不是java内存结构,java内存结构是堆栈方法区):https://mp.weixin.qq.com/s/x0cuhZdUN3XOppwRv-edPA
其次是线程池:

1.多线程(原理)
线程和进程各自有什么区别和优劣呢?
-
进程是资源分配的最小单位,线程是程序执行的最小单位。
-
进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
-
线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。
-
但是多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。
Thread实现多线程:


只要启用多线程就必须使用thread中的start函数。
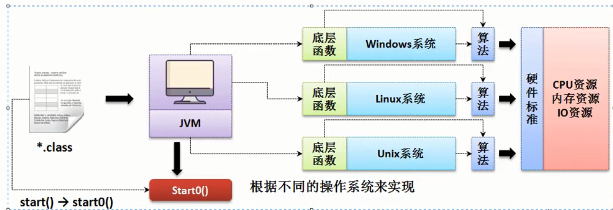
runnable实现多线程(避免单继承的局限):
runable是接口,可以实现多继承,但是没有start方法,所以无法直接开始线程,但是thread的构造方法中可以把runnable作为参数,所以可以通过构造方法来进行传递。

其中Mythread实现了runnable接口。以后多线程的实现优先考虑runnable。
thread和runnable之间的关系:
查看源码 :
![]()
发现thread类实现了runnable接口,在之前继承thread类的时候,实际上覆写的还是runnable中的run方法。而执行start之后实际上是调用run方法,一张图表示runnable和thread之间的关系:

在进行thread启动多线程的时候调用的是start方法,而后找到的是run方法。
![]()
当通过thread类的构造方法传递了一个runnable的接口对象的时候,那么该接口对象将被thread类中的target属性所保存。在thread中调用start方法时会调用下面的run方法:

而这个覆写的run方法会调用runnable接口子类(上面图中的new Mythread对象,这个对象实现了runnable接口)被覆写过的run方法。
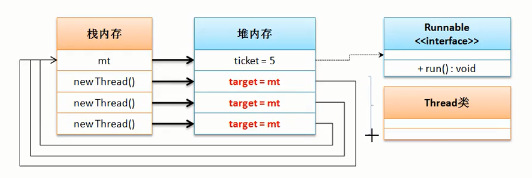
当有多个线程时的结构:

在实际情况下这里的线程对象就可能是各个用户。
模拟多个用户买票的程序:

内存如下图所示:
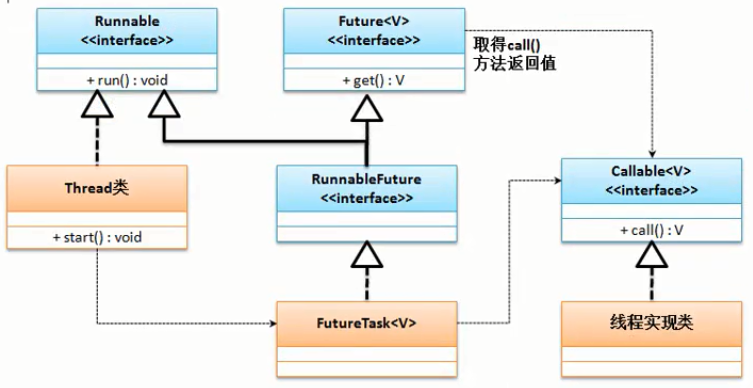
Callable实现多线程:
callable调用内存关系图:
相关程序演示:

runnable和callable的区别:

但是不管用什么,用thread中的start启动线程是不变的定理。
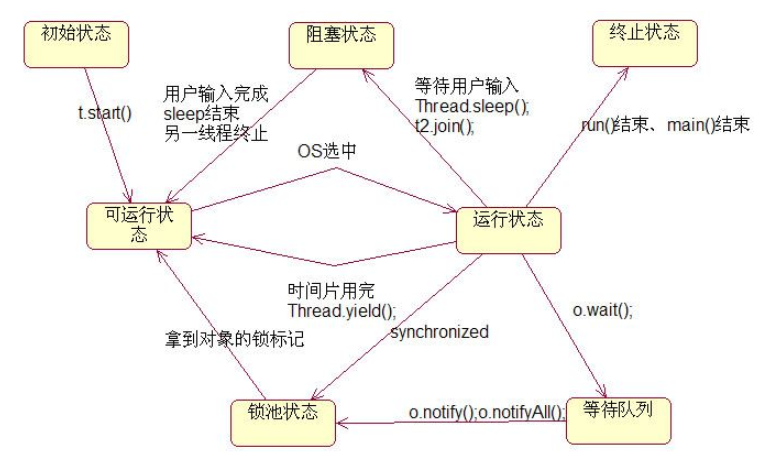
线程的运行:
实际上所有的线程都是通过start开始,但是start仅仅只是代表就绪,真正的开始是run方法,下面给出一张图:
深度好文:https://www.cnblogs.com/jijijiefang/articles/7222955.html
面试问题:请问为什么stop方法和suspend方法为什么不推荐使用?
https://blog.csdn.net/caolaosanahnu/article/details/19491351
2.线程的操作
线程的命名和取得:
对于程序的开发过程之中,需要通过获得线程来进行一些操作,所以线程的名字至关重要:

获取名字的代码操作如下:

输出: ,如果没有名字,会给一个默认的不重复的名字。
,如果没有名字,会给一个默认的不重复的名字。
对于名字的不重复,使用到了static关键字:

其实main函数也是一个线程,查看下面的代码:

输出main和线程对象,可以发现main也是一个线程,那么进程是什么呢?
每当使用java命令执行程序的时候就表示启动了一个jvm的进程,一台电脑上可以启动若干个jvm进程,jvm进程都会有各自的线程。

在任何开发之中,主线程可以创建若干子线程,一般开发情况下,主线程负责整体流程,子线程负责处理耗时操作。

线程休眠:
![]()
millis是毫秒,nanos是纳秒。
此时产生五个线程对象,5个线程对象执行的方法体相同。
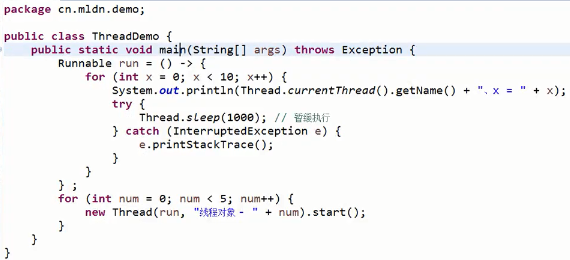
执行的时候并不是同时休眠,同时唤醒,中间会有适当的延迟操作。
线程中断:
所有正在执行的线程都是可以被中断的,中断线程必须进行异常处理。

线程强制执行和礼让:
在进行强制执行的时候必须先获得线程对象,然后调用join方法,实现强制执行,强制执行方法中可以写入参数。
https://www.cnblogs.com/lcplcpjava/p/6896904.html
线程的礼让方法:yield方法,每次礼让都只会礼让当前当前的资源

当执行的时候发现有礼让,则礼让当前资源,下次又执行的时候,如果还有礼让则继续礼让当前资源。
线程优先级:

这些优先级都有对应的常量,分别是10,5,1。但是高优先级的只是有可能先执行,并不是绝对的先执行。其中主线程是中等优先级(5),而默认创建的线程也是中等优先级。
线程的同步和死锁:
线程同步:
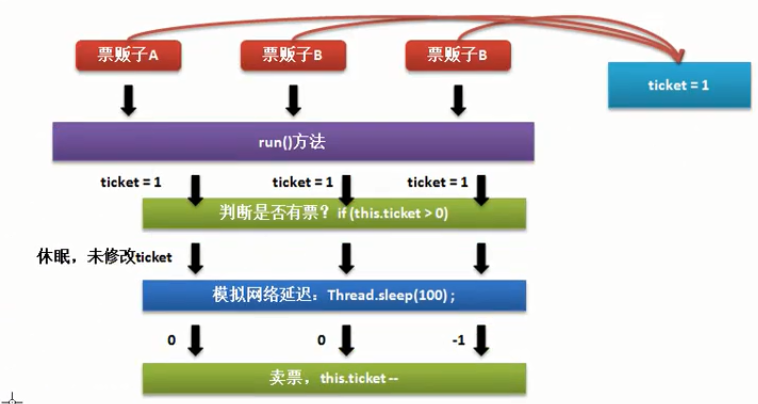
问题引入,线程的不同步问题,模拟一个卖票程序,
前一个线程进入run()后开始执行售卖操作,票数减一,操作还没结束,另一个线程也进来了,此时的票数其实已经减过了(负数),后来的线程之后执行到输出语句的时候才知道是负数.
所以,就需要在一个线程进入之后锁住这一方法,等操作结束另一线程才能进入.这一线程操作的时候,其他线程只能等待:
Synchronized关键字:https://blog.csdn.net/zjy15203167987/article/details/82531772
面试题:为什么分布式环境下synchronized失效?如何解决这种情况?(看了上面那篇文章都会了解到)
面试题:同步方法和同步代码块的区别?https://www.cnblogs.com/xujingyang/p/6565606.html
面试题:解释一下synchronize的可重入性?https://www.jianshu.com/p/7fc3eb310ca1
Synchronized和CAS(compare and swap)的区别:https://www.cnblogs.com/myopensource/p/8177074.html
Synchronized和lock的区别:https://www.cnblogs.com/iyyy/p/7993788.html
要实现同步可以由同步代码块和同步方法,其中常用的是同步方法。但是同步会实现性能的下降。
https://blog.csdn.net/weixin_39641494/article/details/78437823
线程死锁和解决方法:
https://blog.csdn.net/ls5718/article/details/51896159
生产者消费者模式:
生产者消费者模式是最基本的,最原始的多线程实现方式。
https://www.cnblogs.com/fankongkong/p/7339848.html
volatile关键字:
首先了解java内存模型,java内存模型:https://blog.csdn.net/hollis_chuang/article/details/80880118
volatile关键字详解:https://www.cnblogs.com/zhengbin/p/5654805.html
volatile是如何保证可见性的:
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
先看一段代码,假如线程1先执行,线程2后执行:
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;
这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
使用volatile关键字会强制将修改的值立即写入主存;
使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效,然后线程1读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。
那么线程1读取到的就是最新的正确的值。