此题目考查的是对Hibernate中交叉连接的理解。HQL支持SQL风格的交叉连接查询,交叉连接适用于两个类之间没有定义任何关联时。
在where字句中,通过属性作为筛选条件,如统计报表数据。使用交叉连接时应避免“from Dept,Emp”这样的语句出现。执行这条HQL
查询语句,返回DEPT表和EMP表的交叉组合,结果集的记录数为两个表的记录数之积,也就是数据库中的笛卡尔积。这样的查询结果没
有实际意义,因此选项b是正确的。A和C答案都是符合上述描述的,是适合使用交叉连接的场合。D答案认为以上三种都适合,与上述描
述冲突。由于题目要求选择不适合使用交叉连接的选项,因此选项B、C、D是错误的。
本题考核的是Hibernate-HQL查询中的HQL概述。答案A中,HQL的select语句中的类名和属性名是区分大小写的;答案B中,HQL是支持统计函数的;
答案D中,绑定参数的序号从0开始。所以ABD都不正确,只有C是正确的。因此答案是c。

load延迟加载 get立即加载

本题考查的是Hibernate-HQL连接查询中的查询性能优化的方式(Hibernate使用优化、HQL优化),参考的都是原生SQL语句的优化原则。
四个答案都符合,所以ABCD都对。答案是abcd。
此题目考查的是对Hibernate主要从哪些方面优化查询性能的理解。A答案中分别指定了迫切左外连接、迫切内连接和查询缓存等方式,其中迫
切左外连接和迫切内连接会将“左边”对象用于与“右边”对象关联的属性立即初始化,减少select语句的数目。同样地,查询缓存将一次查询的
多条记录放入缓存,下次查询同样的一批记录时,不需要向数据库发起SQL语句,也可以减少select语句的数目。B答案中指定使用延迟加载策
略来优化查询,延迟加载策略不立即加载与当前对象关联的对象,在第一次访问关联对象时才加载其信息,因此选项B也是Hibernate常用的性
能优化措施之一。D答案中建议使用iterate方法,因为iterate方法可以将查询结果缓存在Session中,多次查询时,iterate首先查询ID字
段,然后根据ID字段到Hibernate的Session缓存中查找匹配的持久化对象。如果存在,就直接把它加入到查询结果集中,否则就执行额外的
select语句,根据ID字段到数据库中查询对象。C答案将性能优化的重点放在了数据库上,没有提到Hibernate中相关的措施。由于本题要求
选择不是Hibernate中查询性能优化措施的选项,因此选项A、B、D是错误的,选项C是正确的。
此题考查的是:HQL查询语句,及HQL语句的别名的命名规则,答案A中,select可以省略,是正确的;答案B中,表达的也是正确的;
答案C中,HQL是支持聚合函数的,所以C的表达式错误的;答案D中,表达的也是正确的。本题选择的是错误的表达,所以ABD都不符合,只有C符合。因此答案是c。
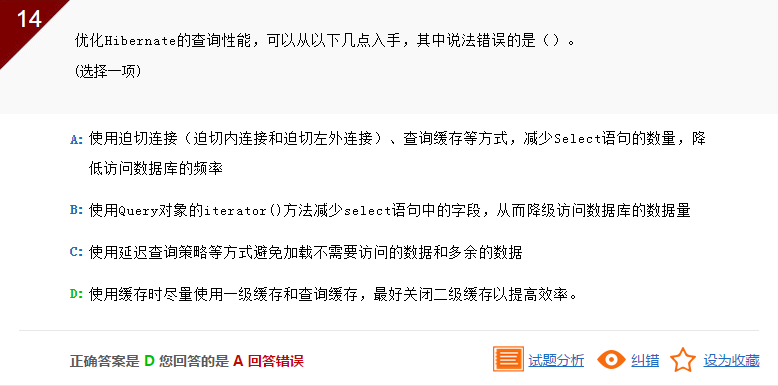
在使用查询缓存是是不能关闭二级缓存的。因此D选项不正确。

此题考查的是隐式内连接的效果 因为没有center join语法,所以C错; 因为题目是用cross join,所以AB错
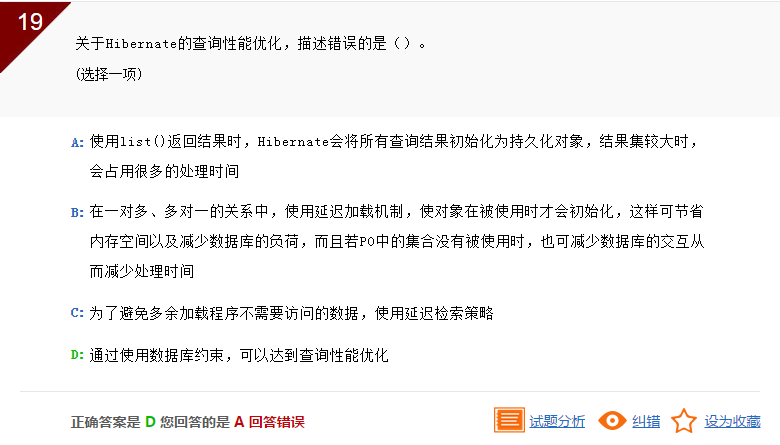
此题考查的是对查询性能优化的方式的理解; 因为通过使用数据库约束,而用多用在数据录入时对数据的校验,所以D错;

one-to-one配置的查询,必须查询到另一个实体

本题考查的是Hibernate中使用检索策略优化HQL的类级别检索策略的数据加载方法。get()方法在记录不存在时返回值为null,而load会抛出
HibernateException异常,选项A将两个说法说反类,因此A不正确;get()方法总是会立即加载对象,类级别的检索策略对get()无效,因此
B不正确。若lazy="true"时,即表示需要进行延迟加载,此时load()调用时并不会访问数据库创建select语句,而是创建代理类实例。只有
当访问非OID属性时才会访问数据库,因此D不正确。选项C是load()方法的正确说法。

经常被修改的数据需要一级缓存存储,而二级缓存存储查询的数据和常量数据。财务数据存储一些重要的数据,不只是需要简单的查询,需要修改,所以需要用一级缓存进行存储。

听信别人的话选错了!!
理解hibernate缓存的原理

此题考查的是隐式内连接连接的效果 因为没有center join语法,所以C错误; 因为题目是用内连接,所以D错
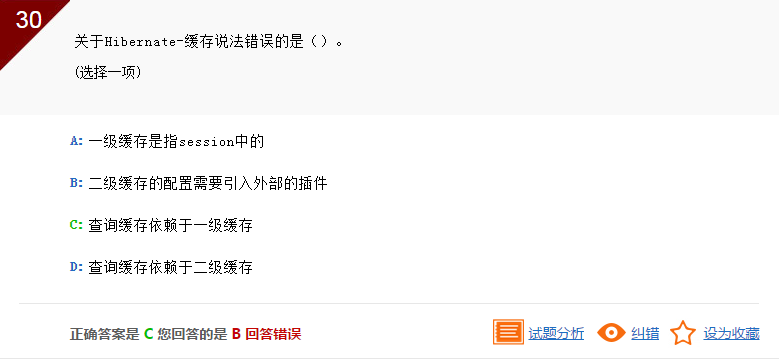
查询缓存是依赖于二级缓存
本题考查的是HQL语句优化查询检索策略。立即检索会产生多条select语句,因此选项A错误,迫切左外连是立即加载策略,与立即检索不同的是只执行1条select语句,因此C错误。B的说法是正确的。
SessionFactory是二级缓存 查询缓存依赖于二级缓存 所以B是对的

前面的错题有说过 二级缓存 一般用于不是很重要的数据和常量数据


执行时要使用查询缓存,需要调用Query的setCacheable(true)。

此题考查的是各种连接的效果 因为如 A right join B 即取出B表的所有数据,由on条件关联的A表数据,有则显示,没有则为空;所以B错;
此题目考查的是对Hibernate中迫切连接的简单应用。Hibernate中的迫切连接是通过fetch关键字实现的,fetch关键字表明“左边”对象用于
与“右边”对象关联的属性会立即被初始化,但可能会有一些重复的“左边”对象。在一个Dept部门下有多个Emp员工的情况下,左外连接使用一个
部门匹配一个员工的方式返回结果,因此造成结果集中出现重复的Dept部门对象的情况,因此选项B是正确的。A答案中的异常可能在session对
象为null的情况下抛出,但题目的假设是session对象是正常开启的并且未关闭,再者,就算是hql语句没有查到结果,query.list方法也不会
抛出NullPointerException异常,因此选项A是错误的。C答案是对迫切连接的原理理解不透彻造成的,迫切连接返回的List会采用“左边”对
象的泛型,而不是Object[],因此选项C是错误的。D答案只考虑了简单的情况,在简单情况下,即一个部门只有一个员工的情况,题目代码是没
有问题的。但是考虑到一个Dept部门下有多个Emp员工的情况,题目代码会返回包含重复Dept对象的List集合,因此,因此选项D是错误的。

本题考查的是HQL内连接与迫切内连接的区别。选项A的说法不正确,因为只有迫切内连接才会立即加载连接数据,普通内连接在初始化时set集合并不会立即加载数据。 选项B的说法是正确的,emps集合不会被初始化。选项C的说法也是正确的,第二句是迫切内连接,所以数据会立即加载。选项D是误导选项。
此题目考查的是Hibernate关系映射的使用。每个人有不同的名字这说明是一对一的关系人和人名不重复,多个人可以是同一个名字为对第一的关系。所以本题正确选项是AC。

本题考查的是HQL外连接的使用方式。本题中唯一错误的选项为D,因为fetch只对inner join 和left join有效,对right join无效。

此题目考查的是对Hibernate中隐式和显示内连接的简单应用。在HQL查询语句中,如果通过对Emp类赋别名“e”,可以通过e.dept.dname的形式
访问dept对象的dname属性,使用隐式内连接按部门条件查询员工信息,因此选项B是正确的。另外也可以显式使用inner join关键字内连接e.dept对象
,因此选项C也是正确的。A答案中虽然使用了inner join关键字,但是连接对象使用不正确,这样做会导致“could not found the property Dept of Emp”的错误
,即在Emp类中找不到叫作Dept的属性。原因是Hibernate是一款基于ORM的解决方案,在HQL语句执行之前已经对表和持久化对象作了映射,Hibernate只知道Emp中有dept属性,
而不知道Dept,因此选项A是错误的。B答案是照搬SQL语句的写法,该写法用在HQL中会导致将“研发部”这个部门对象与每一个Emp员工对象匹配的结果,总记录数等于Emp员工的记录数,
因此选项B是错误的。
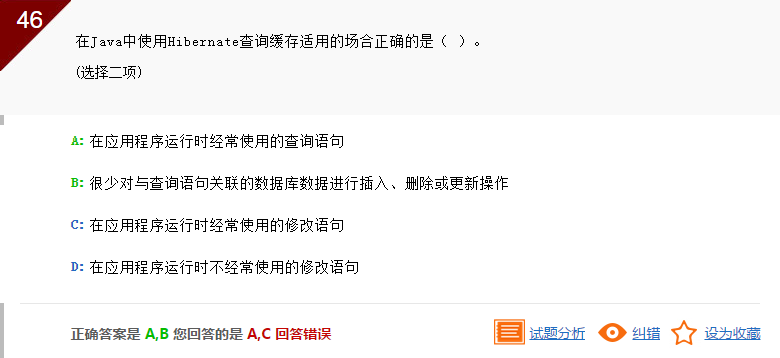
此题目考查的是Hibernate查询缓存适用的场合,对于经常使用的查询语句,如果启用了查询缓存,当第一次执行查询语句时,Hibernate会把查询结果存放在第二缓存中。
以后再次执行该查询语句时,只需从缓存中获得查询结果,从而提高查询性能。所以本题正确选项是AB。
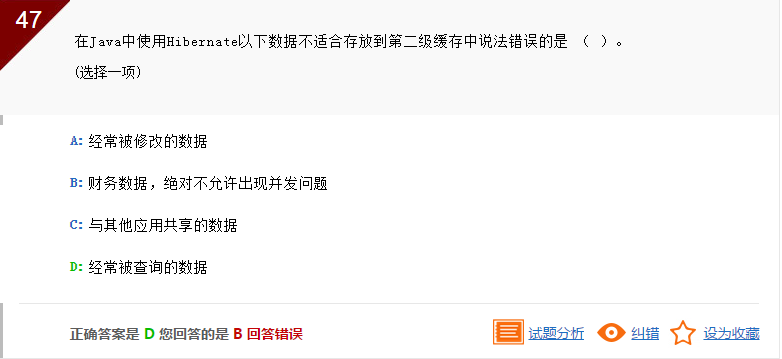
此题目考查的是Hibernate二级缓存相关内容。Hibernate的二级缓存策略,是针对于ID查询的缓存策略,经常被查询的数据,在没有条件时是可以用二级缓存的,因此答案应是D。
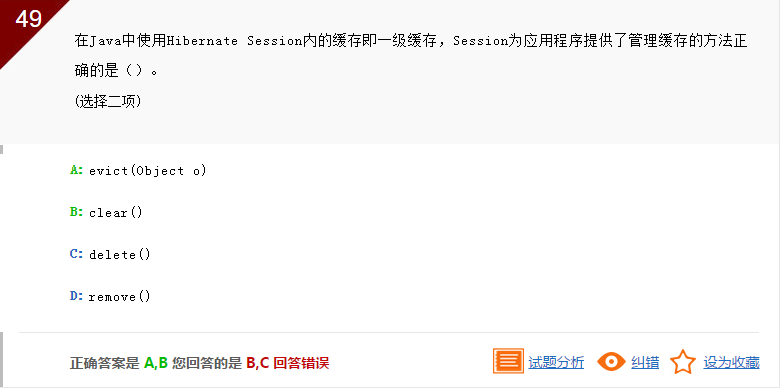
此题目考查的是Session一级缓存,Session提供俩个管理缓存的方法,evict(Object o):从缓存中清除参数指定的持久化对象,能够从缓存中清除特定的持久化对象,clear():清空缓存中所有持久化对象,因此本题目应该选择AB。

此题目考查的是对Hibernate中HQL迫切连接的简单应用。在HQL迫切连接中,fetch关键字只对inner join和left join有效。对于right join而言,
由于作为关联对象容器的“左边”对象可能为null,所以也就无法通过fetch关键字强制Hibernate进行集合填充操作,因此选项a是正确的。B答案是将
fetch用在迫切左外连接的正确用法。C答案是将fetch用在显示迫切内连接的正确用法。D答案是将fetch用在隐示迫切内连接的正确用法。由于题目要
求选择用法不正确的选项,因此选项B、C、D是错误的。
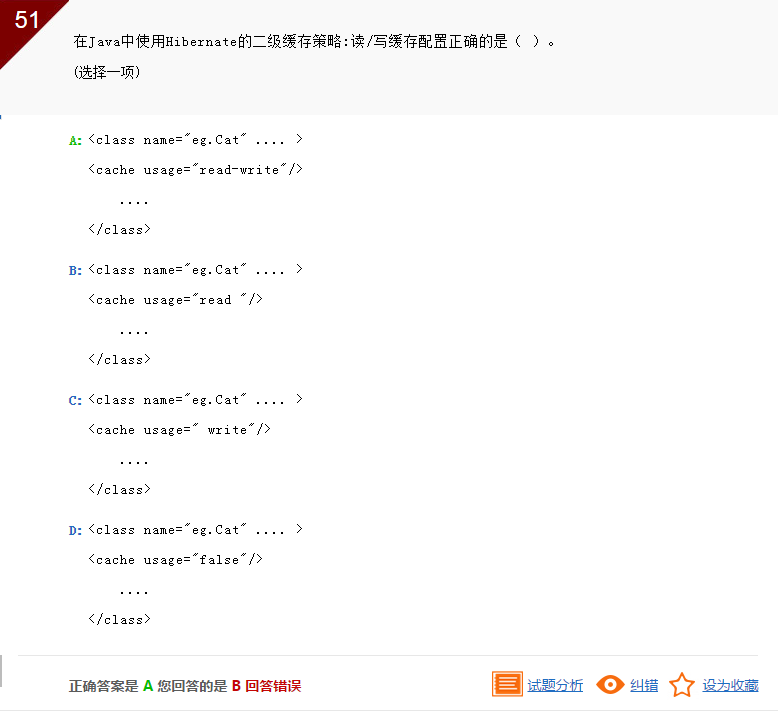
此题目考查的是Hibernate的二级缓存,读/写缓配置正确<cache usage="read-write"/>,所以本题正确选项是A。

此题目考查的是Hibernate二级缓存配置。首先要加载ehcache.xml,然后在配置文件中配置开启二级缓存信息,之后还有在配置文件上配置缓存产品提供商的信息,最后在修改持久化类的映射文件,因此答案应是B。

二级缓存和查询缓存需要在开启二级缓存才可以进行交互
此题目考查的是Hibernate优化查询性能,iterate()方法减少select语句中的字段,从而降低访问数据库的数据量,而list()方法是没有办法减少的,所以本题正确选项是D。

A一级缓存和二级缓存能进行交互,需要配置 关闭二级缓存 B 没有此配法 C 可以在相应的映射进行配置 D 正确
此题目考查的是Hibernate持久化层的缓存的并发访问策略,只读型:对于从来不会被修改的数据,所以本题正确选项是D。

执行from Dept d inner join d.emps返回的集合中,每个元素是一个Object[ ];执行from Dept d inner join fetch d.emps返回的集合中,
每个元素是一个Dept对象。执行from Dept d inner join d.emps所得到的Dept对象中的emps属性是未初始化,即没有存储关联的Emp对象;
执行from Dept d inner join fetch d.emps所得到的Dept对象中的emps属性才是初始化好的。
此题目考查的是对缓存的理解,查询少,变更多时,使用缓存反而会降低性能,所以a、b错误。如果按照id查询,可在id列上增加索引,但如果对每一列都增加索引可能会降低插入和修改性能,因此d错误。应选择c

B、数据库可以永久保存数据,而且有访问权限,可以保证数据的安全性。D、添加事务操作才能对数据进行操作,锁主要用于多用户环境下保证数据库完整性和一致性。

此题目考查的是hibernate中如何配置一对一关系,user应该持有card属性,因此a和c错误,一对一映射不需要用property标签,d错误,应选择b