一、Hive 执行过程实例分析
1、join
对于 join 操作:
SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.userid = u.userid);
执行的最后结果条数: page_view 表中的 userid 数目 * user 表中的 userid 数目
实现过程:
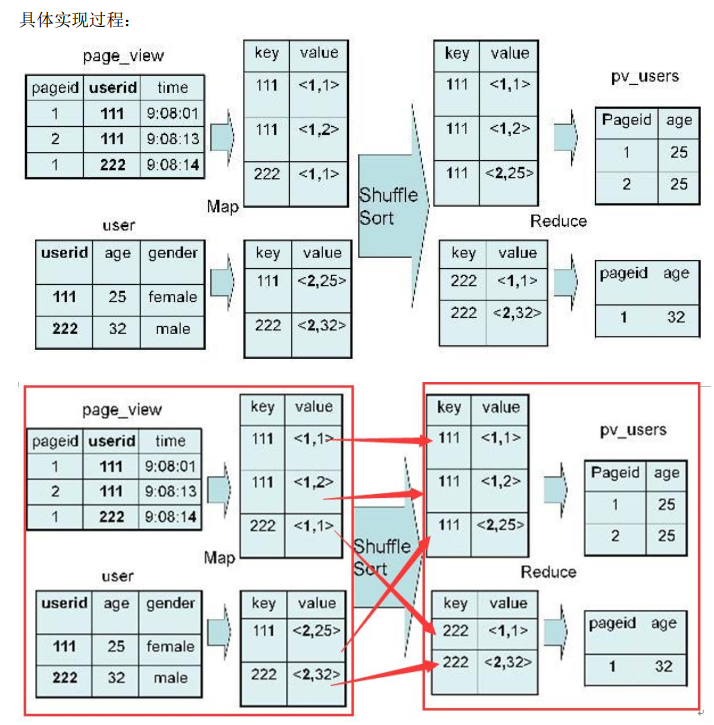
Map:
(1)以 JOIN ON 条件中的列作为 Key,如果有多个列,则 Key 是这些列的组合
(2)以 JOIN 之后所关心的列作为 Value,当有多个列时, Value 是这些列的组合。在 Value 中还会包含表的 Tag 信息,用于标明此 Value 对应于哪个表。
(3) 按照 Key 进行排序。
Shuffle:
(1) 根据 Key 的值进行 Hash,并将 Key/Value 对按照 Hash 值推至不同对 Reduce 中。
Reduce:
(1) Reducer 根据 Key 值进行 Join 操作,并且通过 Tag 来识别不同的表中的数据。
具体实现过程:
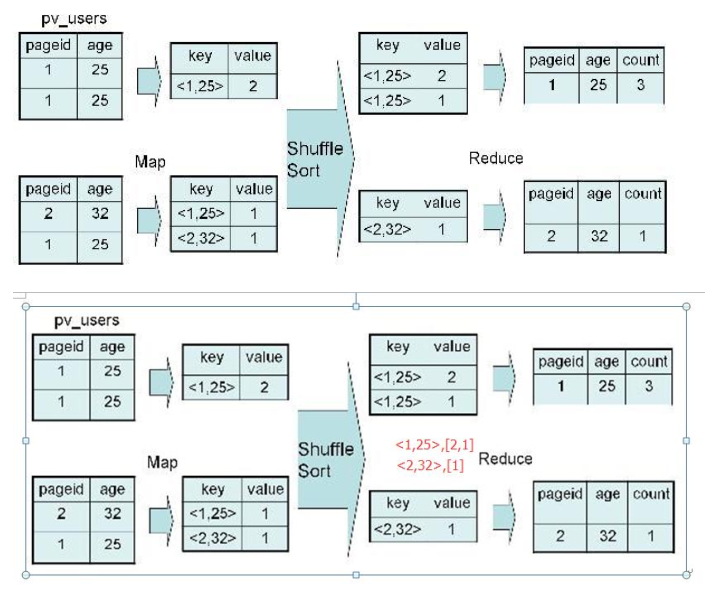
2、group by
对于 group by:
SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;
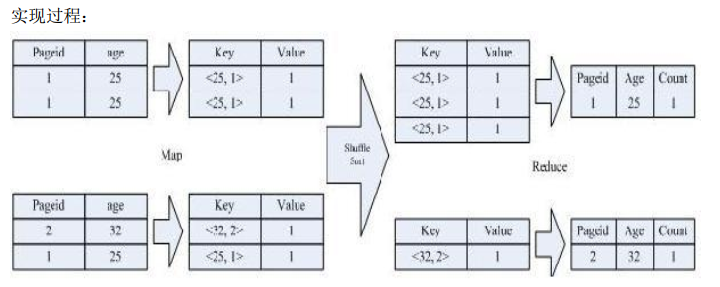
3、distinct
对于 distinct:
SELECT age, count(distinct pageid) FROM pv_users GROUP BY age;
按照 age 分组,然后统计每个分组里面的不重复的 pageid 有多少个。
二、hive优化策略
1、hadoop框架计算特性
(1) 数据量大不是问题,数据倾斜是个问题。
(2) jobs 数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次汇总,产生十几个 jobs,耗时很长。原因是 map reduce 作业初始化的时间是比较长的。
(3) sum,count,max,min 等 UDAF,不怕数据倾斜问题,hadoop 在 map 端的汇总合并优化,使数据倾斜不成问题。
(4)count(distinct userid),在数据量大的情况下,效率较低,如果是多 count(distinct userid,month)
效率更低,因为 count(distinct)是按 group by 字段分组,按 distinct 字段排序,一般这种分布 方式是很倾斜的,比如男 uv,女 uv,淘宝一天 30 亿的 pv,如果按性别分组,分配 2 个 reduce, 每个 reduce 处理 15 亿数据。
2、优化常用手段
(1)好的模型设计事半功倍。
(2)解决数据倾斜问题。
(3) 减少 job 数。
(4) 设置合理的 map reduce 的 task 数,能有效提升性能。 (比如, 10w+级别的计算,用 160 个 reduce,那是相当的浪费, 1 个足够)。
(5) 了 解 数 据 分 布 , 自 己 动 手 解 决 数 据 倾 斜 问 题 是 个 不 错 的 选 择 。 set hive.groupby.skewindata=true;这是通用的算法优化,但算法优化有时不能适应特定业务背景, 开发人员了解业务,了解数据,可以通过业务逻辑精确有效的解决数据倾斜问题。
(6) 数据量较大的情况下,慎用 count(distinct), group by 容易产生倾斜问题。
(7) 对小文件进行合并,是行至有效的提高调度效率的方法,假如所有的作业设置合理的文 件数,对云梯的整体调度效率也会产生积极的正向影响。
(8) 优化时把握整体,单个作业最优不如整体最优。
3、全排序
Cluster by: 对同一字段分桶并排序,不能和 sort by 连用
Distribute by: 分桶,保证同一字段值只存在一个结果当中
Sort by: 单机排序,单个 reduce 结果
Order by: 全局排序
一定要区分这四种排序的使用。
4、怎样做笛卡尔积
当 Hive 设定为严格模式( hive.mapred.mode=strict)时,不允许在 HQL 语句中出现笛卡尔积,这实际说明了 Hive 对笛卡尔积支持较弱。因为找不到 Join key, Hive 只能使用 1 个 reducer来完成笛卡尔积。
当然也可以用上面说的 limit 的办法来减少某个表参与 join 的数据量,但对于需要笛卡尔积语义的需求来说,经常是一个大表和一个小表的 Join 操作,结果仍然很大(以至于无法用单机处理),这时 MapJoin 才是最好的解决办法。
MapJoin,顾名思义,会在 Map 端完成 Join 操作。这需要将 Join 操作的一个或多个表完全读入内存。
MapJoin的用法是在查询/子查询的 SELECT关键字后面添加/*+ MAPJOIN(tablelist) */提示优化器转化为 MapJoin (目前 Hive 的优化器不能自动优化 MapJoin)。其中 tablelist 可以是一个表,或以逗号连接的表的列表。 tablelist 中的表将会读入内存,应该将小表写在这里。
PS:有用户说 MapJoin 在子查询中可能出现未知 BUG。在大表和小表做笛卡尔积时,规避笛卡尔积的方法是,给 Join 添加一个 Join key, 原理很简单:将小表扩充一列 join key,并将小表的条目复制数倍, join key 各不相同;将大表扩充一列 join key 为随机数。
精髓就在于复制几倍,最后就有几个 reduce 来做, 而且大表的数据是前面小表扩张 key 值范围里面随机出来的,所以复制了几倍 n,就相当于这个随机范围就有多大 n,那么相应的,大表的数据就被随机的分为了 n 份。并且最后处理所用的 reduce 数量也是 n,而且也不会出现数据倾斜。
5、怎样写in/exists语句
虽然经过测验, hive1.2.1 也支持 in 操作,但还是推荐使用 hive 的一个高效替代方案: left semi join
6、怎样决定 reduce 的个数(设置reduce的个数比分桶数大于或等于,不能小于)
Hadoop MapReduce 程序中, reducer 个数的设定极大影响执行效率,这使得 Hive 怎样决定reducer 个数成为一个关键问题。遗憾的是 Hive 的估计机制很弱,不指定 reducer 个数的情况下, Hive 会猜测确定一个 reducer 个数,基于以下两个设定:
1. hive.exec.reducers.bytes.per.reducer(默认为 256000000)
2. hive.exec.reducers.max(默认为 1009)
3. mapreduce.job.reduces=-1(设置一个常量 reducetask 数量)
计算 reducer 数的公式很简单:
N=min(参数 2,总输入数据量/参数 1)
通常情况下,有必要手动指定 reducer 个数。考虑到 map 阶段的输出数据量通常会比输入有大幅减少,因此即使不设定 reducer 个数,重设参数 2 还是必要的。依据 Hadoop 的经验, 可以将参数 2 设定为 0.95*(集群中 datanode 个数)。
7、合并mapreduce操作
FROM (SELECT a.status, b.school, b.gender FROM status_updates a JOIN profiles b ON (a.userid =
b.userid and a.ds='2009-03-20' ) ) subq1
INSERT OVERWRITE TABLE gender_summary PARTITION(ds='2009-03-20')
SELECT subq1.gender, COUNT(1) GROUP BY subq1.gender
INSERT OVERWRITE TABLE school_summary PARTITION(ds='2009-03-20')
SELECT subq1.school, COUNT(1) GROUP BY subq1.school
上述查询语句使用了 Multi-group by特性连续 group by了 2 次数据,使用不同的 group by key。这一特性可以减少一次 MapReduce 操作
8、Bucketing和Sampling
Bucket 是指将数据以指定列的值为 key 进行 hash, hash 到指定数目的桶中。这样就可以支持高效采样了。
如下例就是以 userid 这一列为 bucket 的依据,共设置 32 个 buckets

Sampling 可以在全体数据上进行采样,这样效率自然就低,它还是要去访问所有数据。而
如果一个表已经对某一列制作了 bucket,就可以采样所有桶中指定序号的某个桶,这就减
少了访问量。
如下例所示就是采样了 page_view 中 32 个桶中的第三个桶。
SELECT * FROM page_view TABLESAMPLE(BUCKET 3 OUT OF 32);
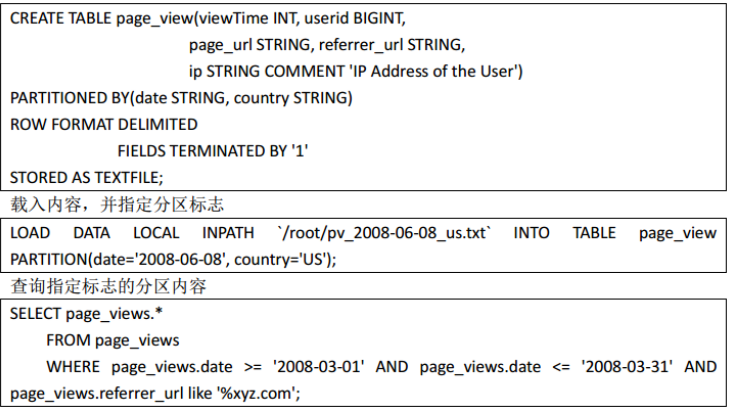
9、Partition(分区,查询时where条件可以是范围)
Partition 就是分区。分区通过在创建表时启用 partition by 实现,用来 partition 的维度并不是实际数据的某一列,具体分区的标志是由插入内容时给定的。当要查询某一分区的内容时可以采用 where 语句,形似 where tablename.partition_key > a 来实现。
创建含分区的表
10、join
Join 原则: 在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在Join 操作符的左边。原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率。对于一条语句中有多个 Join 的情况,如果 Join 的条件相同,比如查询
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x ON (u.userid = x.userid);
如果 Join 的 key 相同,不管有多少个表,都会则会合并为一个 Map-Reduce一个 Map-Reduce 任务,而不是 ‘ n’ 个
在做 OUTER JOIN 的时候也是一样
如果 join 的条件不相同,比如:
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x on (u.age = x.age);
Map-Reduce 的任务数目和 Join 操作的数目是对应的,上述查询和以下查询是等价的
INSERT OVERWRITE TABLE tmptable
SELECT * FROM page_view p JOIN user u
ON (pv.userid = u.userid);
INSERT OVERWRITE TABLE pv_users
SELECT x.pageid, x.age FROM tmptable x
JOIN newuser y ON (x.age = y.age);
11、小文件合并
文件数目过多,会给 HDFS 带来压力,并且会影响处理效率,可以通过合并 Map 和 Reduce的结果文件来消除这样的影响:
hive.merge.mapfiles = true 是否和并 Map 输出文件,默认为 True
hive.merge.mapredfiles = false 是否合并 Reduce 输出文件,默认为 False
hive.merge.size.per.task = 256*1000*1000 合并文件的大小
12、group by
Map 端部分聚合:
并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端
进行部分聚合,最后在 Reduce 端得出最终结果。
MapReduce 的 combiner 组件
参数包括:
hive.map.aggr = true 是否在 Map 端进行聚合,默认为 True
hive.groupby.mapaggr.checkinterval = 100000 在 Map 端进行聚合操作的条目数目
有数据倾斜的时候进行负载均衡:
hive.groupby.skewindata = false
在 MR 的第一个阶段中, Map 的输出结果集合会缓存到 maptaks 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的
Reduce 中,从而达到负载均衡的目的;第二个阶段 再根据预处理的数据结果按照 Group ByKey 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce中),最后完成最终的聚合操作。