一、DDL操作(定义操作)
1、创建表
(1)建表语法结构
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)] //字段注释
[COMMENT table_comment] //表的注释
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] //分区,前面没有出现的字段
[CLUSTERED BY (col_name, col_name, ...) //分桶,前面出现的字段
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
分区:不用关注数据的具体类型,放入每一个分区里; 分桶:调用哈希函数取模的方式进行分桶
(2)建表语句相关解释
create table: 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用 户可以用 IF NOT EXISTS 选项来忽略这个异常。
external :关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的 路径( LOCATION), Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建 外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部
表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。 (经典面试问题)
partitioned :在 Hive Select 查询中一般会扫描整个表内容,会消耗很多时间做没必要的 工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了 partition 概念。 个 表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下,
分区是以字段的形式在表结构中存在,通过 desc table 命令可以查看到字段存在,但是 该字段不存放实际的数据内容,仅仅是分区的表示。分区建表分为 2 种,一种是单分区, 也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现
多文件夹嵌套模式
like: 允许用户复制现有的表结构,但是不复制数据。
comment: 可以为表与字段增加描述
row format:

stored as :如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
clustered by (分桶):

location:指定数据文件存放的 hdfs 目录
(3)hive的建表示例
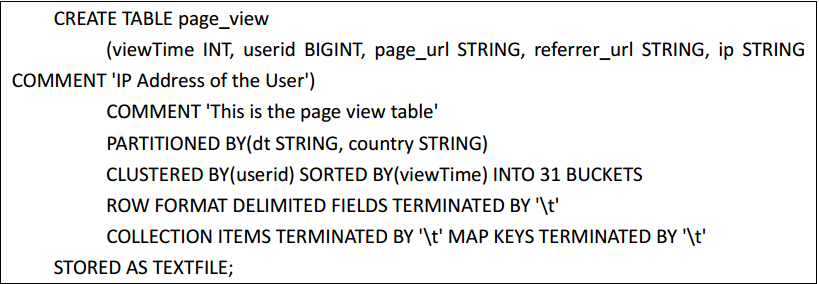
执行查看表结构:desc formatted page_view
(4)Hive QL对SQL语句的支持
1、 select * from db.table1
2、 select count(distinct uid) from db.table1
3、 支持 select、 union all、 join( left、 right、 full join)、 like、 where、各种聚合函数、支 持 json 解析
4、 UDF( User Defined Function) / UDAF(多行合并为一行)
5、 不支持 update 和 delete
6、 hive 支持 in/exists, hive 使用 semi join 的方式来代替实现,而且效率更高。
(5)具体示例
a、创建内部表
create table mytable (id int, name string) row format delimited fields terminated by ','
stored as textfile;

b、创建外部表
create external table mytable2 (id int, name string) row format delimited fields
terminated by ',' location '/user/hive/warehouse/mytable2';

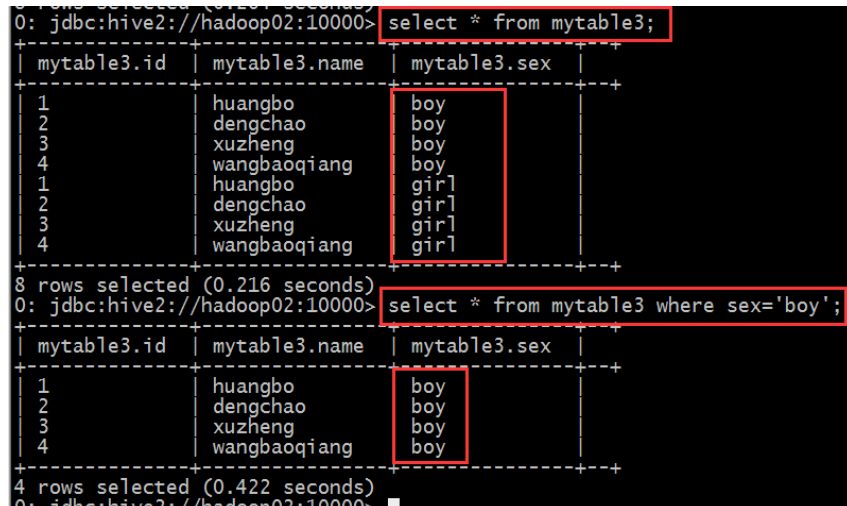
c、创建分区表
create table mytable3(id int, name string)
partitioned by(sex string) row format delimited fields terminated by ','stored as textfile;
插入数据
插入男分区数据: load data local inpath '/root/hivedata/mingxing.txt' overrite into table
mytable3 partition(sex='boy');
插入女分区数据: load data local inpath '/root/hivedata/mingxing.txt' overrite into table
mytable3 partition(sex='girl');

d、创建分桶表
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string)
clustered by(Sno) sorted by(Sno DESC) into 4 buckets
row format delimited fields terminated by ',';
2、修改表
(1)重命名表 ALTER TABLE table_name RENAME TO new_table_name
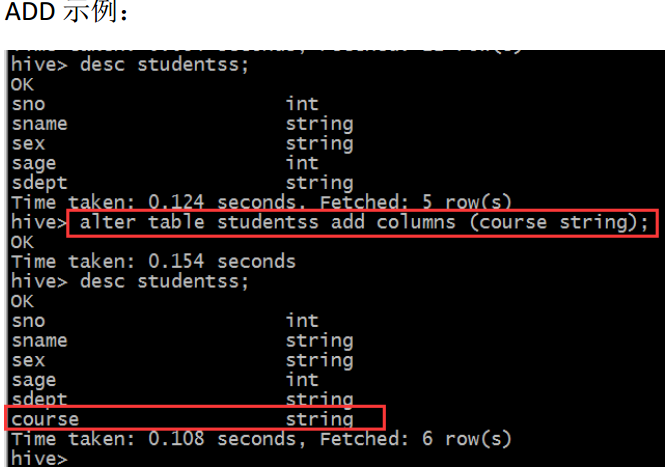
(2)增加、删除、改变、替换列

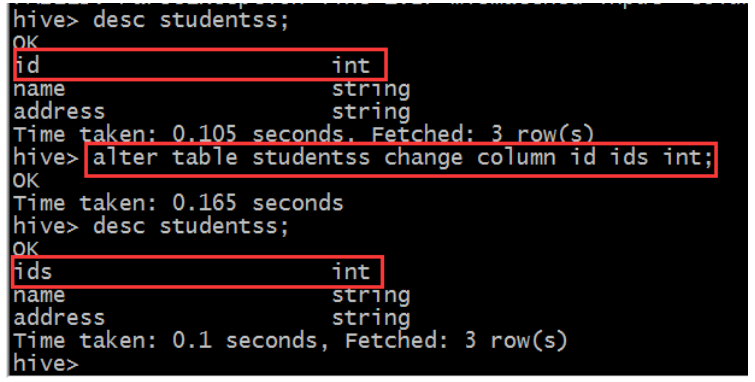
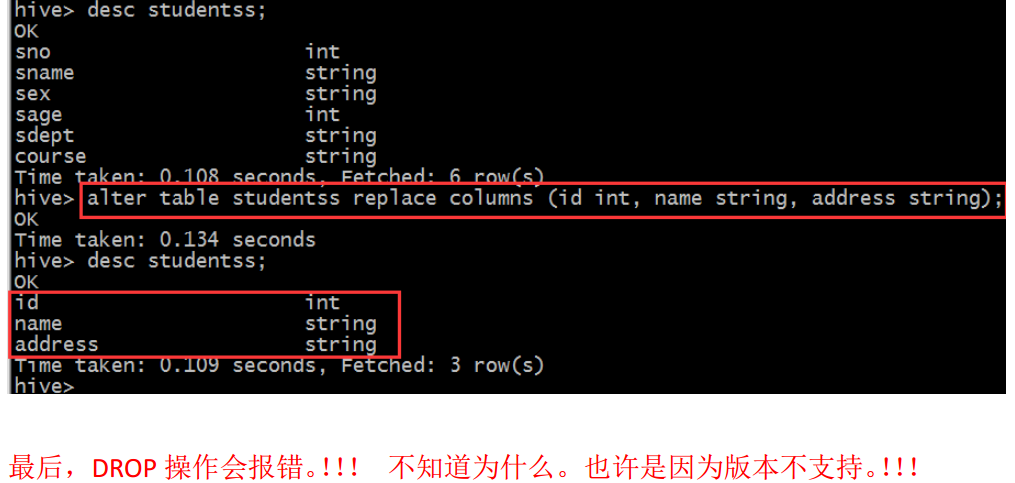
(3)删除表 DROP TABLE [IF EXISTS] table_name;
(4)增加、删除分区
增加分区语法结构:
ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ]
partition_spec [ LOCATION 'location2' ] ...
删除分区语法结构:ALTER TABLE table_name DROP partition_spec, partition_spec,...
具体示例:alter table student_p add partition(part='a') partition(part='b');
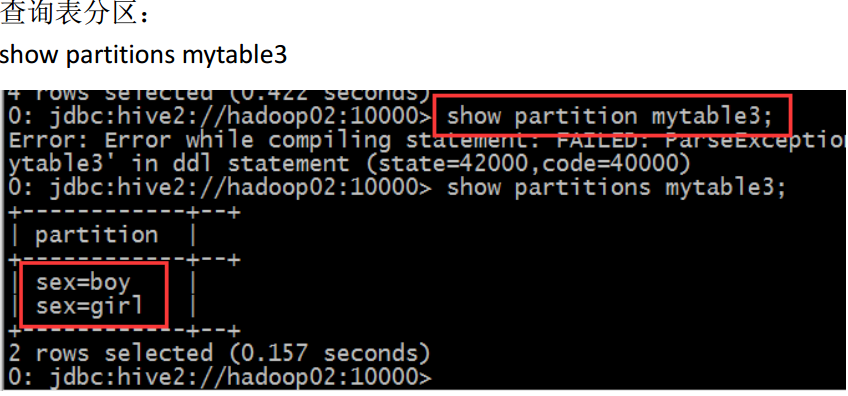
显示命令:
show tables;
show databases;
show partitions table_name;
show functions; 展示内置函数
desc extended table_name;
desc formatted table_name;
二、DML操作
1、load装载数据 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
说明:
(1) Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。
(2) filepath:
相对路径,例如: project/data1
绝对路径,例如: /user/hive/project/data1
包含模式的完整 URI,列如:
hdfs://namenode_host:9000/user/hive/project/data1
(3) local 关键字
如果指定了 LOCAL, load 命令会去查找本地文件系统中的 filepath。
如果没有指定 LOCAL 关键字,则根据 inpath 中的 uri 查找文件
注意: uri 是指 hdfs 上的路径,分简单模式和完整模式两种,例如:
简单模式: /user/hive/project/data1
完整模式: hdfs://namenode_host:9000/user/hive/project/data1
(4)overwrite 关键字
如果使用了 OVERWRITE 关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现 有的文件会被新文件所替代。
2、insert 插入数据
(1)插入一条数据 INSERT INTO TABLE table_name VALUES(XX,YY,ZZ);
(2)利用查询语句将结果导入新表:
INSERT OVERWRITE [INTO] TABLE table_name [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1 FROM from_statement
(3)多重插入
FROM from_statement
INSERT OVERWRITE TABLE table_name1 [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1
INSERT OVERWRITE TABLE table_name2 [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement2] ...
示例:从 mingxing 表中,按不同的字段进行查询得的结果分别插入不同的 hive 表
from mingxing insert into table mingxing2 select id,name,sex,age insert into table mingxing select
id,name,sex ,age,department ;
(4)分区插入
分区插入有两种,一种是静态分区,另一种是动态分区。如果混合使用静态分区和动态分区, 则静态分区必须出现在动态分区之前。现分别介绍这两种分区插入。
静态分区:创建静态分区表、从查询结果中导入数据、查看插入结果
动态分区:
静态分区需要创建非常多的分区,那么用户就需要写非常多的 SQL! Hive 提供了一个动态分 区功能,其可以基于查询参数推断出需要创建的分区名称。
A)、创建分区表,和创建静态分区表是一样的
B)、 参数设置
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
注意: 动态分区默认情况下是没有开启的。开启后,默认是以”严格“模式执行的,在
这种模式下要求至少有一列分区字段是静态的。这有助于阻止因设计错误导致查询产生
大量的分区。但是此处我们不需要静态分区字段,估将其设为 nonstrict。
C)、 动态数据插入 (partition字段必须出现在select字段的最后)
insert into table test2 partition (age) select name,address,school,age from students;
注意:查询语句 select 查询出来的 age 字段必须放在最后,和分区字段对应,不然结果
会出错
D)、 查看插入结果
(5)case(create table ... as select..)
在实际情况中,表的输出结果可能太多,不适于显示在控制台上,这时候,将 Hive 的查 询输出结果直接存在一个新的表中是非常方便的,我们称这种情况为 CTAS
展示:
CREATE TABLE mytest AS SELECT name, age FROM test;
注意: CTAS 操作是原子的,因此如果 select 查询由于某种原因而失败,新表是不会创建 的!
3、insert 导出数据 (如果有local 导出到本地,不带local,导入HDFS)
单模式导出:
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement
多模式导出:
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...
具体示例:
导出数据到本地 Insert overwrite local directory '/root/hivedata/student.txt' select * from studentss;
注意: 数据写入到文件系统时进行文本序列化,且每列用^A 来区分,
为换行符。用
more 命令查看时不容易看出分割符,可以使用: sed -e 's/x01/|/g' filename 来查看。
导出数据到HDFS: Insert overwrite directory 'hdfs://hadoop02:9000/user/hive/warehouse/mystudent' select * from studentss;
4、select 查询数据
语法结构:
SELECT [ALL | DISTINCT] select_ condition, select_ condition, ...
FROM table_name a
[JOIN table_other b ON a.id = b.id]
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list | ORDER BY col_list] ]
[LIMIT number]
说明:
(1)select_ condition 查询字段
(2)table_name 表名
(3) order by 会对输入做全局排序,因此只有一个 reducer,只有一个 reduce task 的结果, 比如文件名是 000000_0,会导致当输入规模较大时,需要较长的计算时间。
(4) sort by 不是全局排序,其在数据进入 reducer 前完成排序。因此,如果用 sort by 进行排 序,并且设置 mapred.reduce.tasks>1,则 sort by 只保证每个 reducer 的输出有序,不保 证全局有序。
那万一,我要对我的所有处理结果进行一个综合排序,而且数据量又非常大,那么怎么 解决?
我们不适用 order by 进行全数据排序,我们适用 sort by 对数据进行局部排序,完了之 后,再对所有的局部排序结果做一个归并排序
(5)distribute by(字段)根据指定的字段将数据分到不同的 reducer,且分发算法是 hash 散列。
(6)Cluster by(字段) 除了具有 Distribute by 的功能外,还会对该字段进行排序。
因此,如果分桶和 sort 字段是同一个时,此时, clustered by = distribute by + sort by 如果我们要分桶的字段和要排序的字段不一样,那么我们就不能适用 clustered by
分桶表的作用:最大的作用是用来提高 join 操作的效率;
( 思考这个问题: select a.id,a.name,b.addr from a join b on a.id = b.id;如果 a 表和 b 表已经是 分桶表,而且分桶的字段是 id 字段做这个 join 操作时,还需要全表做笛卡尔积吗)
实例:(1)获取年龄大的三个学生
select id ,age,name from student where stat_date='20140101' order by age desc limit 3;
(2)查询学生年龄,按降序排序
select id,age,name from student sort by age desc;
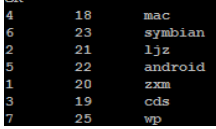
select id,age,name from student order by age desc;
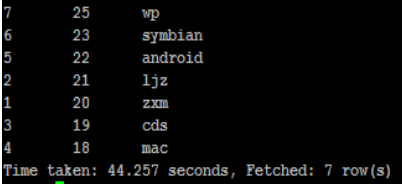
select id,age,name from student distribute by age;
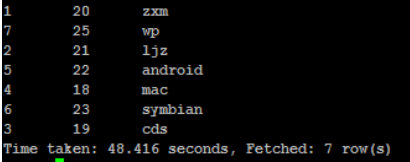
这是分桶和排序的组合操作,对 id 进行分桶,对 age, id 进行降序排序
insert overwrite directory '/root/outputdata6' select * from mingxing2 distribute by id sort
by age desc, id desc;
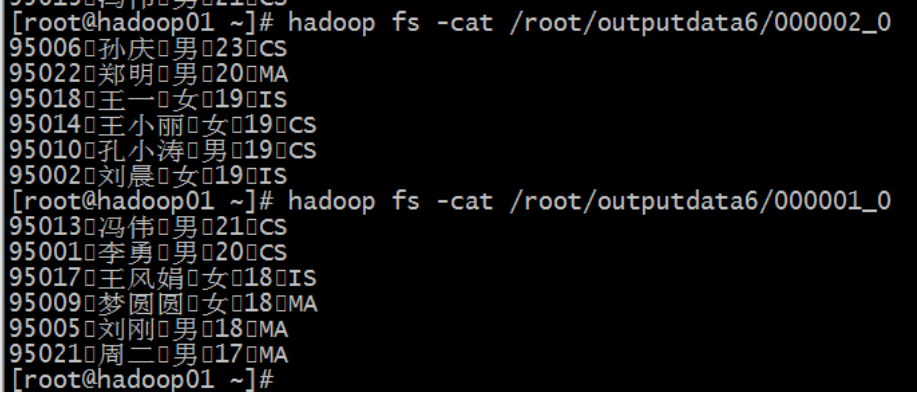
这是分桶操作,按照 id 分桶,但是不进行排序
insert overwrite directory '/root/outputdata4' select * from mingxing2 distribute by id sort
by age;
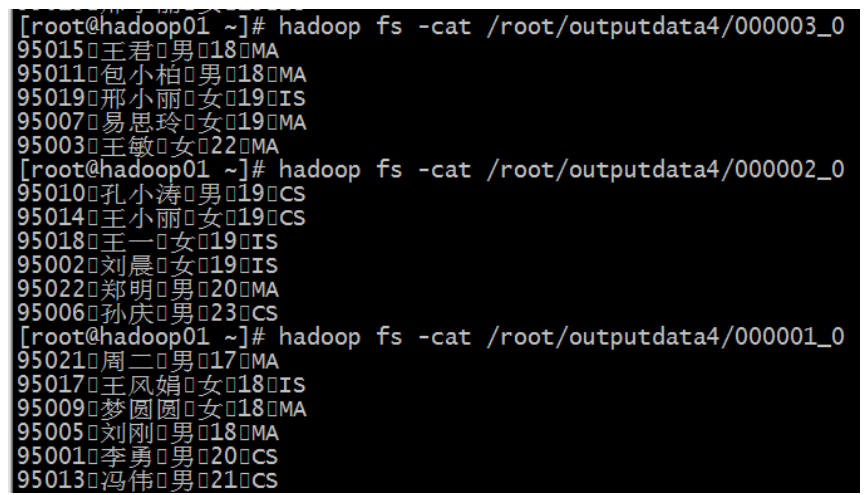
这是分桶操作,按照 id 分桶,并且按照 id 排序
insert overwrite directory '/root/outputdata3' select * from mingxing2 cluster by id;
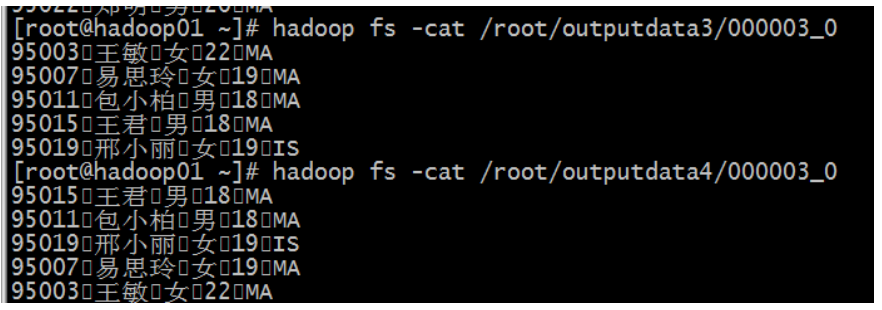
分桶查询:
指定开启分桶:
set hive.enforce.bucketing = true;
指定 reducetask 数量,也就是指定桶的数量
set mapreduce.job.reduces=4;
insert overwrite directory '/root/outputdata3' select * from mingxing2 cluster by id;
(3)按学生名称汇总学生年龄
select name ,sum(age) from student group by name;
解释三个执行参数:
直接使用不带设置值得时候是可以查看到这个参数的默认值:
set hive.exec.reducers.bytes.per.reducer
hive.exec.reducers.bytes.per.reducer:一个 hive,就相当于一次 hive 查询中,每一个 reduce
任务它处理的平均数据量
如果要改变值,我们使用这种方式:
set hive.exec.reducers.bytes.per.reducer=51200000
查看设置的最大 reducetask 数量
set hive.exec.reducers.max
hive.exec.reducers.max:一次 hive 查询中,最多使用的 reduce task 的数量
我们可以这样使用去改变这个值:
set hive.exec.reducers.max = 20
查看设置的一个 reducetask 常量数量
set mapreduce.job.reduces
mapreduce.job.reduces:我们设置的 reducetask 数量
三个参数的优先级顺序是:
mapreduce.job.reduces > hive.exec.reducers.max > hive.exec.reducers.bytes.per.reducer
补充:
// 创建内部表 student create table student(id int, name string, sex string, age int, department string) row format delimited fields terminated by ',' //行分隔符用 lines stored as textfile; // 从本地导入数据 load data local inpath '/home/hadoop/student.txt' into table student; // 查询数据 select id, name, sex, age, department from student; // 创建一个external表 create external table ext_student(id int, name string, sex string, age int, department string) row format delimited fields terminated by ',' location '/ext_student'; // 导入数据 hadoop fs -put student.txt /ext_student; load data local inpath '/home/hadoop/mingxing.txt' into table ext_student; // 查询数据 select id, name ,sex, age , department from ext_student; // 创建内部表引用外部路径 create table mng_student(id int, name string, sex string, age int, department string) row format delimited fields terminated by ',' location '/ext_student'; // 创建分区表 create table ptn_student(id int, name string, sex string, age int, department string) partitioned by(code string) row format delimited fields terminated by ','; // 往分区表导入数据 load data local inpath '/home/hadoop/student.txt' into table ptn_student partition(code='112233'); load data local inpath '/home/hadoop/student.txt' into table ptn_student1 partition(code='335566'); // 创建多字段分区表 create table ptn_student1(id int, name string, sex string, age int, department string) partitioned by(code string, province string) row format delimited fields terminated by ','; // 往多分区表导入数据,需指定两个分区字段值 load data local inpath '/home/hadoop/student.txt' into table ptn_student1 partition(code='335566', province='beijing'); load data local inpath '/home/hadoop/student.txt' into table ptn_student1 partition(code='335566', province='tianjing'); load data local inpath '/home/hadoop/student.txt' into table ptn_student1 partition(code='kk', province='tianjing'); // 创建分桶表 create table bck_student(id int, name string, sex string, age int, department string) clustered by(department) into 4 buckets row format delimited fields terminated by ','; // 重命名表 alter table student rename to studentss; // 修改表的字段 alter table studentss add columns(abc string, efg int); // 删除表的字段,有一些问题。drop字段有问题。不确定能不能执行成功 alter table studentss drop column efg; // 修改表的字段 alter table studentss change abc code int; // 修改表的字段,并且改变字段的位置 alter table studentss change efg province string after name; // 替换所有字段 alter table studentss replace columns(id int, name string, sex string , age int , department string); // 删除表 drop table bck_student; drop table if exists bck_student; // 添加分区 alter table ptn_student add partition(code='445566'); alter table ptn_student add partition(code='445566') partition(code='778899'); // 删除分区 alter table ptn_student drop partition(code='445566'); // insert ... select ..... insert into table student select id, name, sex, age, department from studentss where department = 'MA'; // 以下两句操作是为多重插入准备两张表 create table student11(id int, name string) row format delimited fields terminated by ',' stored as textfile; create table student22(sex string, age int, department string) row format delimited fields terminated by ',' stored as textfile; // 多重插入 from studentss insert into table student11 select id, name insert into table student22 select sex, age, department; // 静态分区插入 load data local inpath 'student.txt' into table ptn_student partition(code='112233'); // 动态分区插入 set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; insert into table d_student partition(age) select id, name, sex, department,age from studentss; // 创建一个分区表,为上面的动态分区做准备的 create table d_student(id int, name string, sex string ,department string) partitioned by(age int) row format delimited fields terminated by ','; // CTAS create table my_student as select id, name , sex, age, department from studentss; // like create table like_student like studentss; // insert导出hive表数据到本地 insert overwrite local directory '/home/hadoop/myoutput' select id, name, sex, age, department from studentss;