一、python 简介
89年开发的语言,创始人范罗苏姆(Guido van Rossum),别称:龟叔(Guido).如下图:

经典格言也是Python程序员的信仰:人生苦短,我用python!
1.2、Python特点
python具有非常多并且强大的第三方库,使得程序开发起来得心应手.
1.3、开发方向:
机器学习人工智能 ,自动化运维&测试 ,数据分析&爬虫 ,python全栈开发
二、python 版本
python 2.x 版本,官方在 2020 年停止支持,原码不规范,重复较多
python 3.x 版本,功能更加强大且修复了很多bug,原码清晰,简单
三、编译型与解释型语言区别:
3.1、编译型:一次性,把所有代码编译成机器能识别的二进制码,在运行
代表语言:c,c++
优点: 执行速度块
缺点: 开发速度慢,调试周期长
3.2、解释型:代码从上到下一行一行解释并运行
代表语言:python,php
优点: 开发效率快,调试周期短
缺点: 执行速度相对慢
*linux 操作系统默认支持python语言,可直接使用
四、python的解释器:
(1)Cpython(官方推荐)
把python转化成c语言能识别的二进制码
(2)Jpython
把python转化成java语言能识别的二进制码
(3)其他语言解释器
把python转化成其他语言能识别的二进制码
(4)PyPy
将所有代码一次性编译成二进制码,加快执行效率(模仿编译型语言的一款python解释器)
五、变量
5.1、变量的概念: 可以改变的量就是变量。具体指代的是内存的一块空间
变量的概念 rujia_305 = "王文" rujia_305 = "李四" print(rujia_305)
win+R-->mspaint(画图板)

5.2、变量的声明:
# (1) 单个变量的定义
a = 1
b = 2
print(a)
print(b)
# (2) 多个变量的定义
a,b = 3,4
print(a , b)
# (3) 相同变量定义
a = b = 5
print( a , b )
5.3、变量的命名:
#字母数字下划线 ,首字符不能为数字
#严格区分大小写 ,且不能使用关键字
#变量命名有意义 ,且不能使用中文哦
_abc123 = 3 abc = 10 ABC = 20 print(abc) # 查看系统所有的关键字 # 引入 模块 import keyword # res => result res = keyword.kwlist print(res) """ ['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield'] """ # 变量名字要有意义 my_car = "宝马" abc = "宝马" """ 在python中,用中文命名变量没有语法错误,但是严禁使用 utf-8 国际标准字符编码(万国码) 一个中文占用3个字节,数字或者符号占用一个字节 gbk 国标编码 一个中文占用2个字节,数字,字母,符号占用一个字节 (1) 防止乱码 (2) 占用的空间更小 """ 中文 = "兔子各个" print(中文) word = "兔子各个"
5.4、变量的交换:
# 变量的交换 a = 10 a = 15
print(a) # 通用写法 tmp = a a = b b = tmp print(a , b) # python特有写法 a = 20 b = 30 a,b = b,a print(a,b)
5.5、常量:就是不可改变的量,python当中没有明确定义常量的关键字,所以约定俗成把变量名大写就是常量,表示不可改变。
如:P = 3.1415926,SHENFENZHENG = 210202200005016688
六、python六大标准数据类型:
6.1、数据类型分类:
(1)Number 数字类型 ( bool int float complex)
(2)str 字符串类型
(3)list 列表类型
(4)tuple 元组类型
(5)set 集合类型
(6)dict 字典类型
6.2、Number数字类型分类:
6.2.1、int : 整数类型 ( 正整数 0 负整数 )
# ### Number # int => 整型 (正整数 0 负整数) intvar = 1000 print(intvar) # type 获取类型 res = type(intvar) print(res) # id 获取地址 res = id(intvar) print(res)
内存地址的命名相当于内存地址号

# 二进制整型
intvar = 0b101 print(intvar) res = type(intvar) res = id(intvar) print(res) # 八进制整型 intvar = 0o127 print(intvar) # 十六进制整型 intvar = 0xff print(intvar)
6.2.2、float: 浮点数类型 ( 1普通小数 2科学计数法表示的小数 例:a = 3e-5 #3e-05 )
# float 浮点型(小数) # 表达方式一 floatvar = 3.14 print(floatvar) res = type(floatvar) print(res) # 表达方式二 (科学计数法) floatvar = 3.98e3 # 3.98乘以10的3次方(小数点向右移动3位) 结果:3980 floatvar = 3.98e-3 # 3.98乘以10的-3次方(小数点向左移动3位) 结果:0.00398 print(floatvar) res = type(floatvar) print(res)
6.2.3、bool: 布尔值类型 ( 真True 和 假False )
# bool 布尔型 (True真的 False假的) 注意:T和F是大写,小写则报错 boolvar = True print(boolvar) res = type(boolvar) print(res)
6.2.4、complex: 复数类型 ( 声明复数的2种方法 ) (复数用作于科学计算中,表示高精度的数据,科学家会使用)
# complex 复数 """ 复数 : 实数 + 虚数 例如 : 3 + 5j 实数 : 3 虚数 : 5j j : 如果有一个数,他的平方等于-1,那么这个数就是j,科学家认为有,表达的是高精度的类型,j是Python内部定义好的,记住就好。 """ # 表达方式一 complexvar = 2-90j complexvar = -90j print(complexvar,"<=====>") res = type(complexvar) print(res) # 表达方式二 """ complexvar = complex(实数,虚数) """ complexvar = complex(3,-90) print(complexvar , type(complexvar) )
6.3、容器类型分类:五个
字符串:str "nihao" 特点: 可获取,不可修改,有序 列表: list [1,2,3] 特点: 可获取,可修改,有序
元组: tuple (6,7,8) 特点: 可获取,不可修改,有序
集合: set {'a',1,2} 特点: 无序,自动去重
字典: dict {'a':1,'b':2} 特点:键值对存储的数据,表面上有序,实际上无序
6.3.1、字符串 str
# 字符串 str : 用引号引起来的就是字符串
"""
# 转义字符:通过进行转换
(1) 把无意义的字符变得有意义
(2) 把有意义的字符变得无意义
: 换行
: 换行
: 缩进(水平制表符)Python标准一个缩进是4个空格
: 把
后面的字符串直接拉到当前行行首
: 折行
"""
# (1) 单引号引起来的字符串 strvar = '今天天气不错' print(strvar , type(strvar)) # (2) 双引号引起来的字符串# 注意:Python中的单双引号是没有区别的
strvar = "大江东去浪涛尽,千古风流人物" print(strvar,type(strvar))
# 把无意义的字符变得有意义 strvar = "大江东去浪涛尽, 千古风流 人物" strvar = "大江东去浪涛尽, 千古风流人物" strvar = "大江东去浪涛尽, 千古风流人物" strvar = "大江东去 浪涛尽, 千古风流人物" print(strvar)
输出:
大江东去
千古风流人物
# 把有意义的字符变得无意义 strvar = "大江东去浪涛尽,千古'风流'人物" strvar = '大江东去浪涛尽,千古"风流"人物' strvar = "大江东去浪涛尽,千古"风流"人物" print(strvar)
# 的折行功能,一行代码过长阅读性差
strvar = "大江东去浪涛尽,
千古'风流'人物"
print(strvar)
输出:
大江东去浪涛尽,千古'风流'人物
# (3) 三引号引起来的字符串 (支持跨行) strvar = ''' 本来无'一'物, 何处惹"尘"埃 ''' print(strvar , type(strvar)) # (4) 元字符串 r + "字符串" => 表示不转义字符,原型化输出字符串,用在导入路径上 strvar = r"E:python29day3 oppp.py" print(strvar) # (5) 字符串的格式化 """ "字符串" % (值1,值2,值3 ... ) %d => 整型占位符 %f => 浮点型占位符 %s => 字符串占位符 """ # %d 整型占位符 strvar = "john同学今年%d岁" % (5) print(strvar) # %2d 占用2位空间,默认居右 strvar = "john同学今年%2d岁" % (5) print(strvar) # %-2d 占用2位空间,默认居左 strvar = "john同学今年%-2d岁" % (5) print(strvar) # %f 浮点型占位符(默认保留6位小数) strvar = "程序员过家家这个同学今天开工资了,发了%f元" % (9.18) print(strvar) # %.1f 小数点后边保留1位小数 (存在四舍五入的情况) strvar = "程序员过家家这个同学今天开工资了,发了%.1f元" % (9.18) print(strvar) # %s 字符串占位符 strvar = "%s" % ("这个同学真帅") print(strvar) # 综合案例 strvar = "%s今天开工资了,一共%.2f元,买了%d个布加迪威龙" % ("李",19.378,3) print(strvar) strvar = "%s今天开工资了,一共%s元,买了%s个布加迪威龙" % ("李",19.378,3) print(strvar)
"""
特点: 可获取,不可修改,有序
"""
# 0123
strvar = "abcd"
# -4-3-2-1
# 获取a元素
res = strvar[0]
print(res)
# 可以修改字符串当中的元素么? 不行
# strvar[0] = "z" error
6.3.2、列表list
""" 特点: 可获取,可修改,有序 """ # 定义一个空列表 listvar = [] print(listvar, type(listvar)) # (1) 定义一个普通的列表 # 正向索引下标 0 1 2 3 4 listvar = [1,3.14,False,3+4j,"你好帅哥"] # 逆向索引下标 -5 -4 -3 -2 -1 # (2) 获取列表当中的元素 res = listvar[3] # python特点,用下标-1 res = listvar[-1] # 获取列表中最后一个元素(通用写法) # len 获取容器类型数据的总长度(元素总个数) res = len(listvar) max_len = res - 1 print(max_len) # 4 val = listvar[max_len] print(val) # (3) 修改列表当中的元素 listvar[-4] = "太帅了" print(listvar)
6.2.3、元组 tuple()
""" 特点: 可获取,不可修改,有序 """ # 1.定义一个普通的元组 # 正向下标 0 1 2 3 tuplevar = ("a",True,9.1,123) # 逆向下表 -4 -3 -2 -1 # 获取元组当中的数据 res = tuplevar[2] print(res) # 2.是否可以修改元组当中的数据? 不可以 # tuplevar[0] = "bbb" # print(tuplevar) # 3.元组的注意点: # (1) 定义一个空元组 tuplevar = () # (2) 逗号是区分是否是元组的标识符 tuplevar = (True,) tuplevar = True,1 print(tuplevar, type(tuplevar))
6.3.4、集合 set()
# ### 集合set (作用:交差并补) """ 特点: 无序,自动去重 """ # 定义一个集合 setvar = {"刘德华","郭富城","张学友","王文"} print(setvar , type(setvar) ) # 1.集合无序 # 获取集合中的元素? 不可以 # res = setvar[0] # print(res) error # 修改集合中的元素? 不可以 # setvar[0] = "abc" error # 2.自动去重 setvar = {"刘德华","郭富城","张学友","王文","王文","王文"} print(setvar, type(setvar)) # 3.定义一个空集合 setvar = {} # 空字典 setvar = set() print(setvar , type(setvar))
6.3.5、字典
# ### 字典dict """ 特点:键值对存储的数据,表面上有序,实际上无序 语法: dictvar = {键1:值1,键2:值2,键3:值3 ... } """ # 1.定义一个字典 dictvar = {"top":"夏侯淳","middle":"安其拉","bottom":"程咬金","jungle":"李白","support":"蔡文姬"} print(dictvar , type(dictvar)) # 2.获取字典当中值 res = dictvar["middle"] print(res) # 3.修改字典当中的值 dictvar["bottom"] = "后裔" print(dictvar)
6.3.2、自动类型转换
当2个不同类型的数据进行运算的时候,默认向更高精度转换,数据类型精度从低到高: bool int float complex
# ### Number 的自动类型转换 (bool int float complex) """ 默认按照精度从低到高进行转换 bool -> int -> float -> complex 自动类型转换规则: 将低精度向高精度自动转换 """ # bool + int res = True + 100 print(res,type(res)) # bool + float res = False + 3.56 # False => 0.0 print(res,type(res)) # bool + complex res = True + 3+4j # True => 1 + 0j print(res) # int + float res = 100 + 6.8 # 100 => 100.0 print(res) # int + complex res = 100 + 6-7j #100 = > 100+0j print(res) # float + complex # 9.5 => 9.5+0j res = 9.5 + 3+4j print(res)
6.3.3、强制类型转换
Number部分
int : 整型 浮点型 布尔类型 纯数字字符串
float: 整型 浮点型 布尔类型 纯数字字符串
complex: 整型 浮点型 布尔类型 纯数字字符串 (复数)
bool: ( 容器类型数据 / Number类型数据 都可以 )
# Number 的强制类型转换 (int float complex bool ) var1 = 4 var2 = 6.89 var3 = 4-2j var4 = False var5 = "666888" var6 = "123abc" # 强制转换成int res = int(var2) # 6 # res = int(var3) # error res = int(var4) # True => 1 False => 0 res = int(var5) # 666888 # res = int(var6) # error print(res , type(res) ) # 强制转换成float res = float(var1) # 4.0 res = float(var4) # False => 0.0 True => 1.0 res = float(var5) # 666888.0 print(res , type(res)) # 强制转换成complex res = complex(var1) # 4 + 0j res = complex(var2) # 6.89 + 0j res = complex(var4) # True => 1 + 0j False => 0j res = complex(var5) # 666888 + 0j # res = complex(var6) # error print(res) # 强制转换成bool (True False) res = bool(None) print(res) # ***** bool类型为假的十种情况 """ 0 , 0.0 , 0j , False , '',[],(),set(),{} ,None None : 关键字,代表空的,什么也没有,一般用来做初始化操作 a = None """ """ int() bool() float() complex() 都可以为当前变量初始化一个默认值 """ res = complex() print(res)
容器类型部分
str: ( 容器类型数据 / Number类型数据 都可以 )
list: 字符串 列表 元组 集合 字典
tuple: 字符串 列表 元组 集合 字典
set: 字符串 列表 元组 集合 字典 (注意:相同的值,只会保留一份)
# ### 容器数据的强制类型转换 (list tuple set dict str) var1 = "abc" var2 = [1,2,3,4] var3 = ("a","b") var4 = {"a1","a2","a3"} var5 = {"a100":1,"b100":2} var6 = 90 # 强制转换成字符串 => str """ 强制转换成字符串:就是单纯的在当前数据类型的两边套上引号; """ res = str(var2) res = str(var3) res = str(var6) print(res , type(res) ) # repr 原型化输出字符串,可以显示引号 print(repr(res),type(res)) # 强制转换成列表 => list """ 如果是字符串,把里面的字符作为列表的新元素, 如果是字典,只保留字典的键,忽略掉值 否则,只是单纯的在原有数据类型的两边,套上[] """ res = list(var1) res = list(var3) res = list(var4) res = list(var5) print(res , type(res)) # 强制转换成元组 => tuple """ 如果是字符串,把里面的字符作为元组的新元素, 如果是字典,只保留字典的键,忽略掉值 否则,只是单纯的在原有数据类型的两边,套上() """ res = tuple(var1) res = tuple(var2) res = tuple(var5) print(res , type(res)) # 强制转换成集合 => set """ 如果是字符串,把里面的字符作为集合的新元素, 如果是字典,只保留字典的键,忽略掉值 否则,只是单纯的在原有数据类型的两边,套上{} """ res = set(var1) res = set(var2) res = set(var5) print(res)
dict: 使用 二级列表,二级元组,二级集合(里面的容器数据只能是元组)
# 二级容器 # 二级列表 lst = [1,2,3,4,5,[6,7,8,9,10]] # 二级元组 tup = (3,4,5,(6,7,8)) # 二级集合 setvar = {"a","b","c",("d","e","f")} # 二级字典 dic = {"a":1,"b":2,"c":{"f":10,"e":15}} res = dic["c"]["e"] print(res) # 四级容器 # 获取14这个元素? container = [1,2,3,4,5,(6,7,8,{"a":1,"b":2,"c":[11,12,13,14]})] # (6, 7, 8, {'a': 1, 'b': 2, 'c': [11, 12, 13, 14]}) res = container[-1] print(res) # {'a': 1, 'b': 2, 'c': [11, 12, 13, 14]} res2 = res[-1] print(res2) # [11, 12, 13, 14] res3 = res2["c"] print(res3) # 14 res4 = res3[-1] print(res4) # 简写 res = container[-1][-1]["c"][-1] print(res) # 等长的二级容器 """ (1) 里面的元素都是容器 (2) 并且容器里面的元素个数都相同 """ lst = [ (1,2,3,4) , {"a","b","c","d"} ] lst = ([1,3,5],(7,8,9)) # ### 强制转换成字典 """ 要求: 等长的二级容器,并且里面的元素个数是2个 """ # (1) 外面是列表,里面是等长的容器,元素个数是2个 lst = [ ["a",1] , ("b",2) , ("c",3) ] dic = dict(lst) print(dic , type(dic)) # (2) 外面是元组,里面是等长的容器,元素个数是2个 tup = ( ["c",1] ,("d",2) ) dic = dict(tup) print(dic , type(dic)) # (3) 外面是集合,里面是等长的容器,元素个数是2个 setvar = {("a",10),("b",15)} dic = dict(setvar) print(dic, type(dic)) # (4) 例外情况,语法上正确,不推荐使用 # 情况一 """字符串形式长度只能是2个,不能表达一个较大数据,不推荐使用""" lst = ["a1","b2"] #"c33" error dic = dict(lst) print(dic) # 情况二 """集合无序,本意是b作为字典的键,2作为字典的值,由于无序没有达到原来的本意,不推荐使用""" lst = [ ('a',1) , {"b",2} ] print(dict(lst)) # 快速去掉列表当中的重复数据 lst = [11,11,"a","a","a","c","c","c","dd","dd"] # 强制转换成集合 (去重) setvar = set(lst) print(setvar) # 强转转换成列表,恢复成原来的数据类型 listvar = list(setvar) print(listvar) """ str() list() tuple() set() dict() 可以为当前的数据类型创建一个默认值 """ res = dict() print(res)
6.3.4、字典和集合的注意点
哈希算法
定义:把不可变的任意长度值计算成固定长度的唯一值,这个值可正可负,可大可小,但长度固定该算法叫哈希算法(散列算法),这个固定长度值叫哈希值(散列值)
特点:
1.计算出来的值长度固定且该值唯一
2.该字符串是密文,且加密过程不可逆
作用:
用哈希计算得到一个字符串的用意?
例如:比对两个文件的内容是否一致?
例如:比对输入的密码和数据库存储的密码是否一致
字典的键和集合中的值都是唯一值,不可重复:
为了保证数据的唯一性,
用哈希算法加密字典的键得到一个字符串。
用哈希算法加密集合的值得到一个字符串。
如果重复,他们都是后面的替换前面的。自动去重
""" 对集合的值 和 字典的键 有数据类型上的要求 可哈希的数据类型: Number(int , bool , float ,complex) ,str , tuple 不可哈希的数据类型 list set dict
3.6版本之前都是 字典和集合都是无序的 3.6版本之后对字典做了优化,存储数据的时候用了哈希算法,但是拿出数据的时候,重新按照定义的顺序做了排序,所以看起来有序,实际上无序 记住:哈希算法是典型的无序的特征. ***推荐大家使用变量命名的字符串作为字典的键*** """ # 字典的键要求可哈希 dictvar = {3:"a",False:"b",4.56:"c",4+9j:"d","中文":"ff",(1,2,3):"zz"} print(dictvar) # 获取元素 zz res = dictvar[(1,2,3)] print(res) # 集合的值要求可哈希 setvar = {1,3.5,False,9+90j,"abc",(1,2,3)} print(setvar , type(setvar))
七、python运算符
| python运算符 | 注意点 |
| ------------ | ------------------------------------------------------------ |
| 算数运算符 | % 取余 , //地板除 , ** 幂运算 |
| 比较运算符 | == 比较两个值是否相等 != 比较两个值是否不同 |
| 赋值运算符 | a += 1 => a = a+1 |
| 成员运算符 | in 或 not in 判断某个值是否包含在(或不在)一个容器类型数据当中 |
| 身份运算符 | is 和 is not 用来判断内存地址是否相同 |
| 逻辑运算符 | 优先级 () > not > and > or |
| 位运算符 | 优先级 (<<或 >> ) > & > ^ > | 5 << 1 结果:10 , 5 >> 1 结果:2 |
(1)算数运算符: + - * / // % **
# 算数运算符: + - * / // % ** var1 = 10 var2 = 5 # + res = var1 + var2 print(res) # - res = var1 - var2 print(res) # * res = var1 * var2 print(res) # / (结果永远是小数) res = var1 / var2 print(res) # // 地板除 10 除以 5 10被除数,5是除数,得到值是商 (默认得到的是整数) res = var1 // var2 print(res) # 被除数或除数是一个小数,结果就是小数 res = 10 // 5.0 res = 14 // 8 print(res) # % 取余 res = 17 % 3 # 2 res = 11 % 7 # 4 res = -11 % 7 # 3 => -4 + 7 = 3 res = 11 % -7 # -3 => 4 + (-7) = -3 res = -11 % -7# -4 => -4 # res = 81 % 5 # 1 res = -81 % 5 # 4 res = 81 % -5 # -4 res = -81 % -5 # -1 print(res) # ** 幂运算 res = 2 ** 50 print(res)
(2)比较运算符: > < >= <= == !=
# 比较运算符: > < >= <= == != 结果只有两种 (True 真的 False 假的) res = 5 > 6 res = 6 < 1000 res = 90 <= 90 print(res) # == 等于 """一个等号是赋值操作,两个等号在做比较操作""" res = 100 == 100 print(res) # != 不等于 res = 100 != 100 print(res)
(3)赋值运算符: = += -= *= /= //= %= **=
# 赋值运算符 = += -= *= /= //= %= **= # = var1 = 10 var2 = 20 var1 = var2 print(var1,var2) # += var1 = 10 var2 = 20 # var1 = var1 + var2 var1 += var2 # var1 = var1 + 1 var1 += 1 print(var1) # -= var1 = 5 var2 = 10 # var1 = var1 - var2 var1 -= var2 print(var1) # %= var1 = 7 var2 = 4 # var1 = var1 % var2 var1 %= var2 print(var1)
(4)成员运算符: in 和 not in (针对于容器型数据)
# 成员运算符: in 和 not in (针对于容器型数据) # 针对于字符串 """要求字符串是一个连续的片段""" strvar = "好看的皮囊千篇一律,有趣的灵魂200多斤" res = "皮" in strvar res = "千篇一律" in strvar res = "灵多" in strvar print(res) # 针对于 list tuple set listvar = ["john","大江东去","繁星","dosir"] res = "大江东去" in listvar tuplevar = ("john","大江东去","繁星","dosir") res = "dosir" not in tuplevar setvar = {"john","大江东去","繁星","dosir"} res = "john1234" not in setvar print(res) # 针对于字典 dict """针对于字典中的键来进行判定""" dictvar = {"fx":"聪明","xx":"美丽","stone":"风流倜傥","fei":"睿智"} res = "美丽" in dictvar res = "xx" in dictvar res = "abc" not in dictvar print(res)
(5)身份运算符: is 和 is not (检测两个数据在内存当中是否是同一个值)
# 身份运算符: is 和 is not (检测两个数据在内存当中是否是同一个值) # 整型 -5 ~ 正无穷 var1 = 100 var2 = 100 res = var1 is var2 print(res) # 浮点型 非负数范围内 var1 = -9.13 var2 = -9.13 res = var1 is var2 print(res) # 容器类型数据,除了空元组和相同的字符串,剩下所有的容器类型数据id地址都不相同 var1 = () var2 = () var1 = [1,2] var2 = [1,2] res = var1 is not var2 print(res)
(6)逻辑运算符: and or not
# 逻辑运算符: and or not # and 逻辑与 """全真则真,一假则假""" res = True and True # True res = True and False # False res = False and True # False res = False and False # False print(res) # or 逻辑或 """全假则假,一真则真""" res = True or True # True res = True or False # True res = False or True # True res = False or False# False print(res) # not 逻辑非 """真变假,假变真""" res = not True res = not False print(res) # 逻辑短路 print("<=============>") """ 短路: 后面代码不执行 (1)True or print("我就是我,不一样的烟火") [在单个表达式或者多个表达式中,可以直接判断短路] (2)False and print("烟花一样的灿烂,是我逝去的青春") [只能在单个表达式当中判断是否短路] # 不发生短路 True and print("仙女一样的姑娘,是我渴望已久的愿望") """ res = 5 or 6 res = 5 and 6 res = not 5 # 逻辑优先级 """从高到低排列: () > not > and > or""" res = 5 or 6 and 7 # 5 or 7 => 5 res = 0 and 6 or 7 # 0 or 7 => 7 res = not 5 or 6 and 7 # False or 6 and 7 => False or 7 => 7 res = not (5 or 6) and 7 # not 5 and 7 => False and 7 => False res = 1>2 and 3<4 or 5>6 and 7<8 and 100>99 """ False and True or False and True and True False or False and True False or False False """ print(res,"<===标注===>") res = False and False # 返回的是第一个False res = False or False # 返回的是第二个False res = False and "闻哥,你为什么这么帅气,我已经爱上了你" res = False or "闻哥,你为什么这么帅气,我已经爱上了你" res = "闻哥哥,我爱你爱的受不了了" or True res = "闻哥哥,我爱你爱的受不了了" and True print(res) """ 额外解答: res = 100 or 200 res = 0 or 200 res = '' or 200 print(res) 例子:False or ? = 多少呢? False or True => True False or False => False False or 200 => 200 """
(7)位运算符: & | ~ ^ << >>
# 位运算符 & | ^ << >> ~ # 按位与 & var1 = 19 var2 = 15 res = var1 & var2 print(res) """ 先把19转换成二进制 10011 在把15转换成二进制 01111 结果 00011 把结果在转换成十进制 => 3 """ # 按位或 | var1 = 19 var2 = 15 res = var1 | var2 print(res) """ 10011 01111 11111 11111 => 十进制31 """ # 按位异或 ^ (两个值不一样,返回真1,两个值一样,返回假0) var1 = 19 var2 = 15 res = var1 ^ var2 print(res) """ 10011 01111 11100 """ # << 左移 (做乘法 乘以2的n次幂) res = 5 << 1 print(res) """ 000101 向左边移动一位 001010 向左边移动二位 010100 => 20 000 0 001 1 010 2 011 3 100 4 101 5 110 6 111 => 7 """ # >> 右移 (做除法 除以2的n次幂) res = 20 >> 2 print(res) """ 10100 向右边移动一位 01010 => 10 向右边移动二位 00101 => 5 """ # ~ 按位非 -(n+1) res = ~3 res = ~(-17) res = ~0 print(res) # ~19 => -20 # ~18 => -19 # ~17 => -18 # ~(-19) => 18 # ~(-18) => 17 # ~(-17) => 16 # ### 运算符总结: """ 优先级最高的符号是 ** 幂运算 优先级最低的符号是 = 赋值运算符 整体来说: 一元运算符 > 二元运算符 优先级 一元运算符 : 同一时间,只操作一个数字的就是一元 ( ~ , - ) 二元运算符 : 同一时间,只操作两个数字的就是二元 ( + - * / ..) 逻辑运算符: () > not > and > or 位运算符 : (<< >>) > & > ^ > | 算数运算符: 先算乘除,再算加减 算数运算符 > 位运算符 > 比较运算符 > 身份运算符 > 成员运算符 > 逻辑运算符 赋值运算符做收尾,等所有运算结束之后,赋值给等号左侧; 算位比身成逻 赋值运算做收尾 """ res = 5+5 << 6 // 3 is 40 and False """ 10 << 2 is 40 and False 40 is 40 and False True and False False """ print(res) # False # 通过() 提升运算的优先级 res = (5 + 5) << (6 // 3) is 40 and False
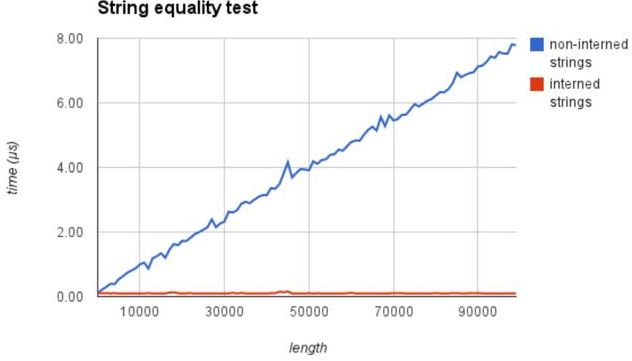
八、数据的在内存中的缓存机制
8.1、在同一文件(模块)里,变量存储的缓存机制 (仅对python3.6版本负责),3.7以后的缓存机制会有变化
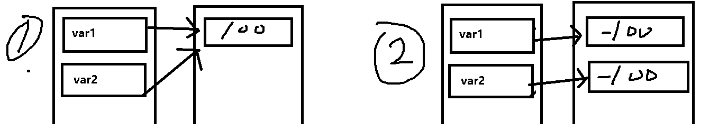
# ### 同一文件中,数据的缓存机制 [python3.6] # -->Number 部分 # 1.对于整型而言,-5~正无穷范围内的相同值 id一致 var1 = 100 var2 = 100 print(id(var1) , id(var2))
输出:496856384 496856384
var1 = -100 var2 = -100 print(id(var1) ,id(var2)) 输出:31312816 31312848 # 2.对于浮点数而言,非负数范围内的相同值 id一致 var1 = 5.78 var2 = 5.78 print(id(var1) , id(var2)) var1 = -6.89 var2 = -6.89 print(id(var1) , id(var2)) # 3.布尔值而言,值相同情况下,id一致 (True False) var1 = True var2 = True print(id(var1),id(var2)) # 4.复数在 实数+虚数 这样的结构中永不相同(只有虚数的情况例外) var1 = 5-2j var2 = 5-2j print(id(var1) , id(var2)) var1 = 9j var2 = 9j print(id(var1) , id(var2)) var1 = -9j var2 = -9j print(id(var1),id(var2)) # -->容器类型部分 # 5.字符串 和 空元组 相同的情况下,地址相同 var1 = "我" var2 = "我" print(id(var1) , id(var2)) var1 = () var2 = () print(id(var1),id(var2)) # 6.列表,元组,字典,集合无论什么情况 id标识都不同 [空元组例外] var1 = [1,2,3] var2 = [1,2,3] print(id(var1) , id(var2))
输出:37564552 37564616
var1 = (1,2,3) var2 = (1,2,3) print(id(var1),id(var2))
8.2、不同文件(模块)里,部分数据驻留小数据池中 (仅对python3.6版本负责 了解)
小数据池只针对:int,str,bool,空元祖(),None关键字 这些数据类型有效
(1)对于int而言python在内存中创建了-5 ~ 256 范围的整数,提前驻留在了内存的一块区域,如果是不同文件(模块)的两个变量,声明同一个值,在-5~256这个范围里,
那么id一致.让两个变量的值都同时指向一个值的地址,节省空间。
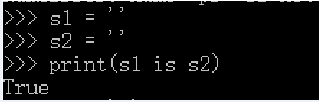
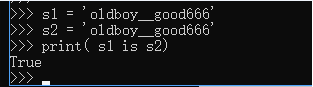
(2)对于str来说:
1.字符串的长度为0或者1,默认驻留小数据池
2.字符串的长度>1,且只含有大小写字母,数字,下划线时,默认驻留小数据池
3.用*号得到的字符串,分两种情况。
1)乘数等于1时: 无论什么字符串 * 1 , 都默认驻留小数据池
2)乘数大于1时: 乘数大于1,仅包含数字,字母,下划线时会被缓存,但字符串长度不能大于20
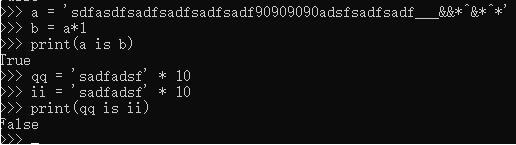
(3)指定驻留
可以指定任意字符串加入到小数据池中,无论声明多少个变量,只要此值相同,都指向同一个地址空间
# 从 sys模块 引入 intern 函数 让a,b两个变量指向同一个值 from sys import intern a = intern('大帅锅&*^^1234'*10) b = intern('大帅锅&*^^1234'*10) print(a is b) print(id(a),id(b)) 输出: True 6105752 6105752
8.3、 缓存机制的意义
无论是变量缓存机制还是小数据池的驻留机制,都是为了节省内存空间,提升代码效率