Nosql概述
现在处于大数据时代,传统数据库已经无法进行分析和处理。
历史进程
单机版
瓶颈
- 数据量太大,一个机器放不下
- 数据的索引(B+ Tree),一个机器的内存也放不下
- 访问量(读写混合),单个服务器承受不了
缓存发展过程
优化数据结构和索引----文件缓存(IO操作)----> 缓存
分库分表 + 水平拆分 + MySQL集群
本质:数据库(读,写)
早些年MyISAM:表锁,影响效率
InnoDB:行锁
慢慢开始使用分库分表来解决写的压力。MySQL在那个年代就推出了表分区!并没有多少公司使用。
接下来推出了MySQL集群,很好的满足了那个年代的所有需求。
如今的年代
数据多样性:定位,音频,人物画像等
MySQL等关系型数据库就不够用了,数据量很多,变化很快。
MySQL存储大文件,博客,图片等,数据库表很大,效率就低,因此,非关系型数据库就诞生了。
MySQL的压力就变得非常小(研究如何处理这些问题),大数据IO的压力下,表几乎没法更改
灰度发布(金丝雀发布)
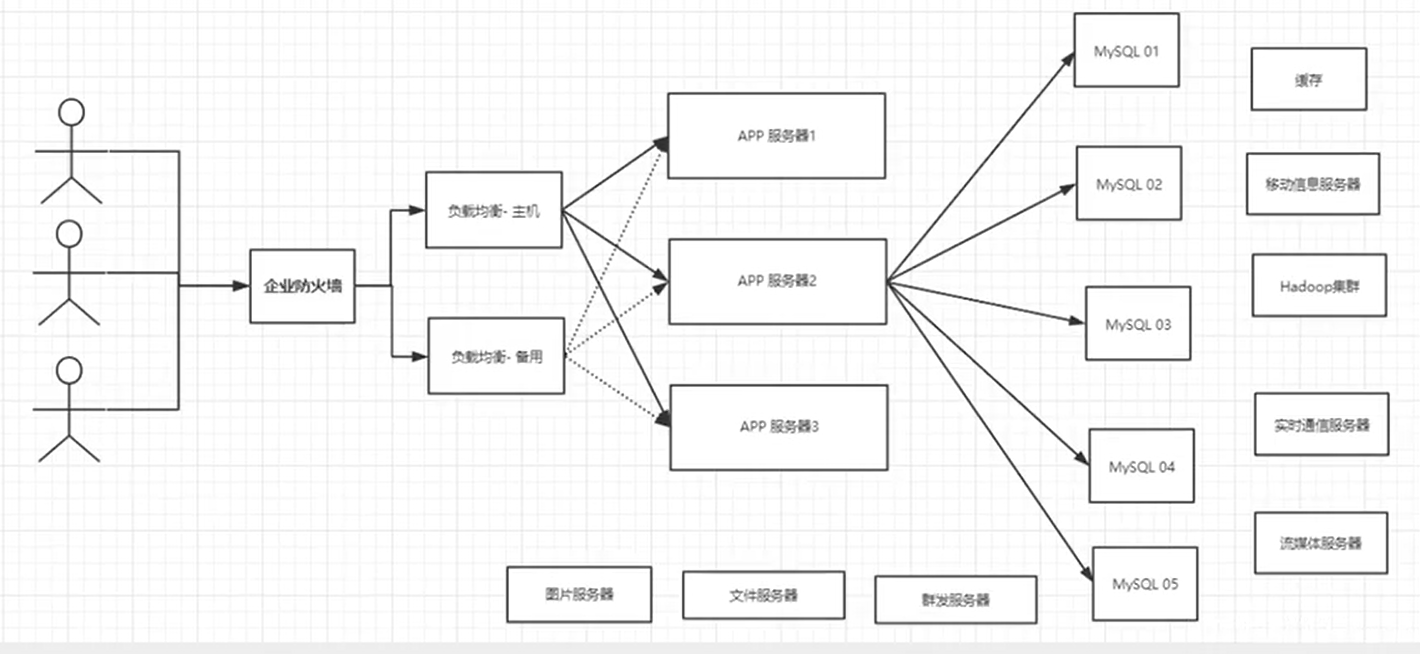
为什么用NoSQL
用户的个人信息,社交网络,地理位置,用户自己产生的数据,用户的日志等等爆发式增长。
这时候就需要使用NoSQL数据库,可以很好的处理以上的情况。
什么是NoSQL?
NoSQL:非关系型数据库
NoSQL = Not Only SQL(不仅仅是SQL)
泛指非关系型数据库。随着web2.0互联网的诞生,传统的关系型数据库很难对付web2.0时代,尤其是超大规模的高并发的社区。NoSQL在当今大数据环境下发展十分迅速。
什么是关系型数据库:由表格,行和列组成的 。
很多的数据类型比如用户的个人信息,社交网络,地理位置,这些数据类型的存储不需要一个固定的格式(行+列),不需要多余的操作就可以横向扩展(集群)。
NoSQL的特点
-
方便扩展(数据之间没有关系,很好扩展)
-
大数据量,高性能(官方数据:redis一秒8万次,读取11万次,NoSQL的缓冲记录级,是一种细粒度的缓存,性能会比较高!)
-
数据类型是多样的(不需要事先设计数据库表,随取随用,如果是数据量十分大的表, 很多人就无法设计了!)
-
传统的RDBMS和NoSQL
传统的RDBMS NoSQL 结构化组织 不仅仅是数据库 SQL 没有固定的查询语言 数据和关系都存在单独的表中 kv键值对存储,列存储,图形数据库,文档存储 数据操作员,数据定义语言 最终一致性 严格的一致性(ACID) CAP定理 和 BASE理论(异地多活) 基础的事务 高性能,高可用,高可扩展
了解3v+3高
大数据时代的3v: 主要是描述问题的
- 海量Volume
- 多样Variety
- 实时Velocity
大数据时代的3高:主要是对程序的要求
- 高并发
- 高可扩(水平拆分)
- 高性能(保证用户体验和性能)
真正在公司中的实践:NoSQL+RDBMS一起使用
阿里巴巴演进分析




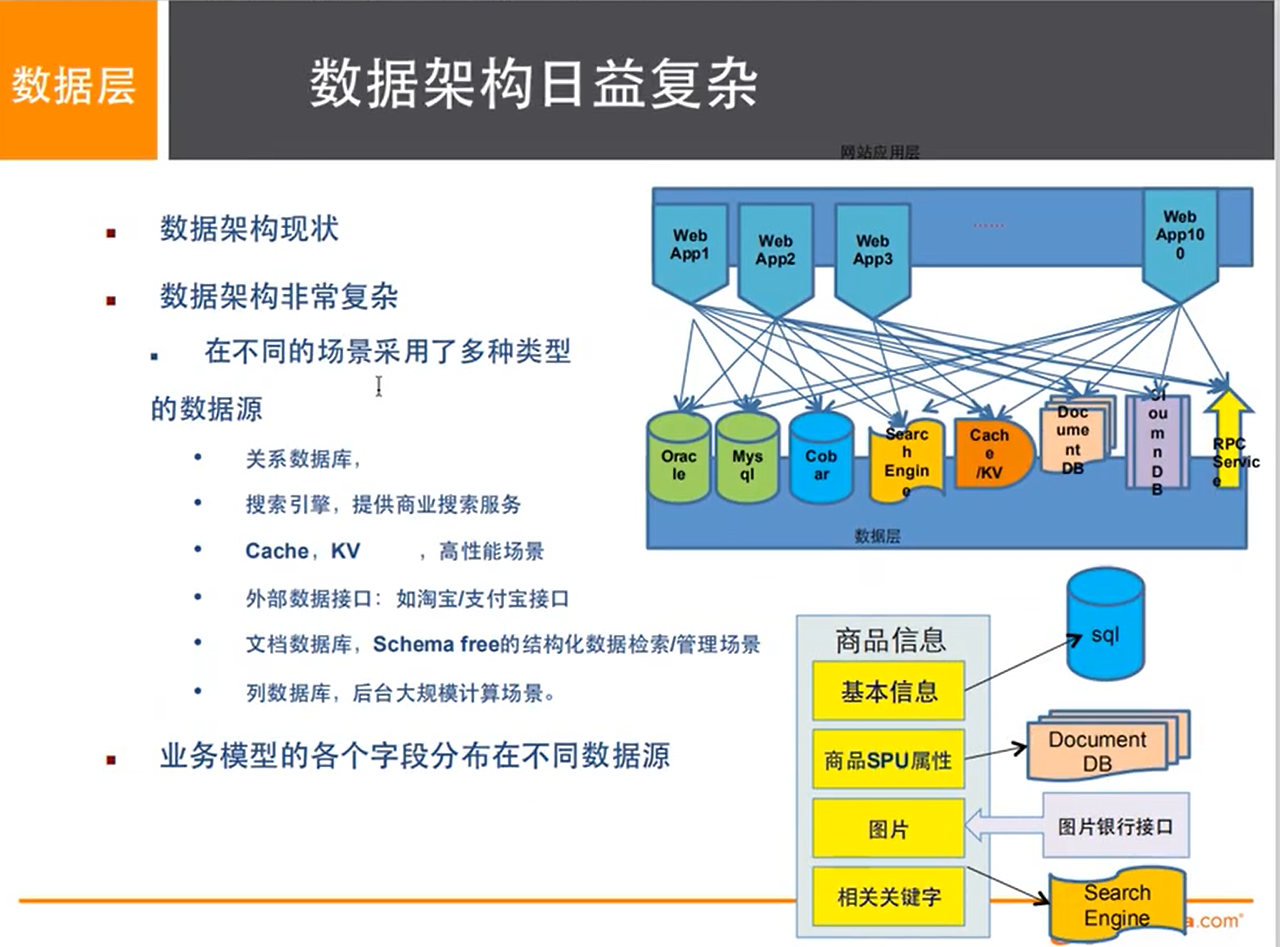

# 1. 商品的基本信息
名称,价格,商家信息
关系型数据库就可以解决了。(MySQL/Oracle(淘宝早些年就去IOE了!- 王坚:推荐文章:阿里云的这群疯子)
淘宝内部用的MySQL不是大家用的MySQL
# 2. 商品描述、评论(文字比较多)
文档型数据库,mongoDB
# 3. 图片
分布式文件系统 FastDFS
- 淘宝自己的 TFS
- Google GFS
- Hadoop HDFS
- 阿里云 oss
# 4. 商品的关键信息
- 搜索引擎 solr elasticsearch
- ISearch: 多隆
所有牛逼的人都有一段苦逼的岁月!但是你只要像SB一样的去坚持,终将牛逼!
# 5. 商品热门的波段信息
- 内存数据库
- Redis memcache Tair
# 6. 商品的交易,外部的支付接口
- 三方应用(银行)
要知道,一个简单的网页背后的技术,一定不是大家所想的那么简单!
大型互联网应用问题:
- 数据源太多,数据类型太多
- 数据源繁多,经常重构
- 数据要改造,大面积改造(比如:MySQL)


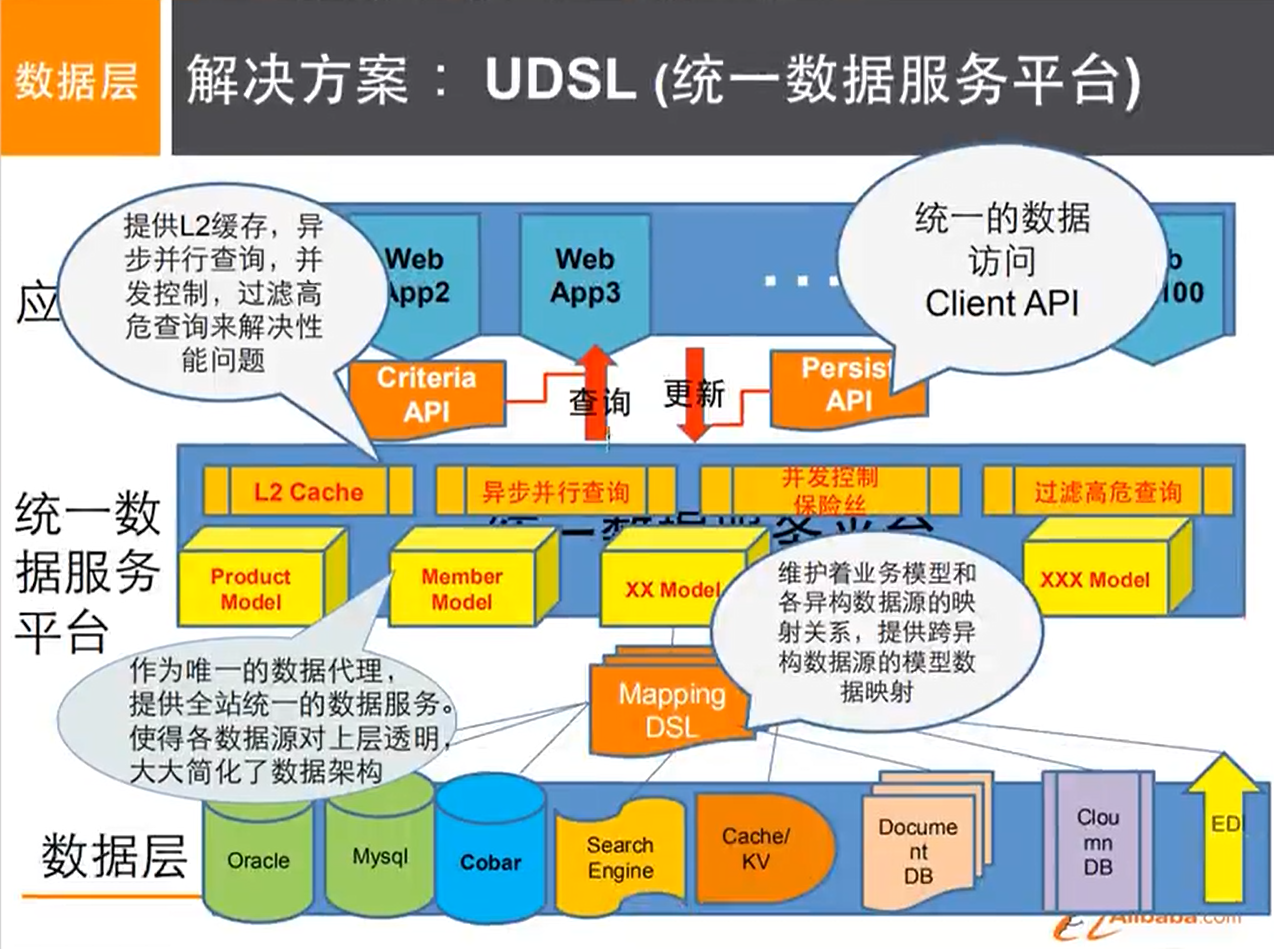

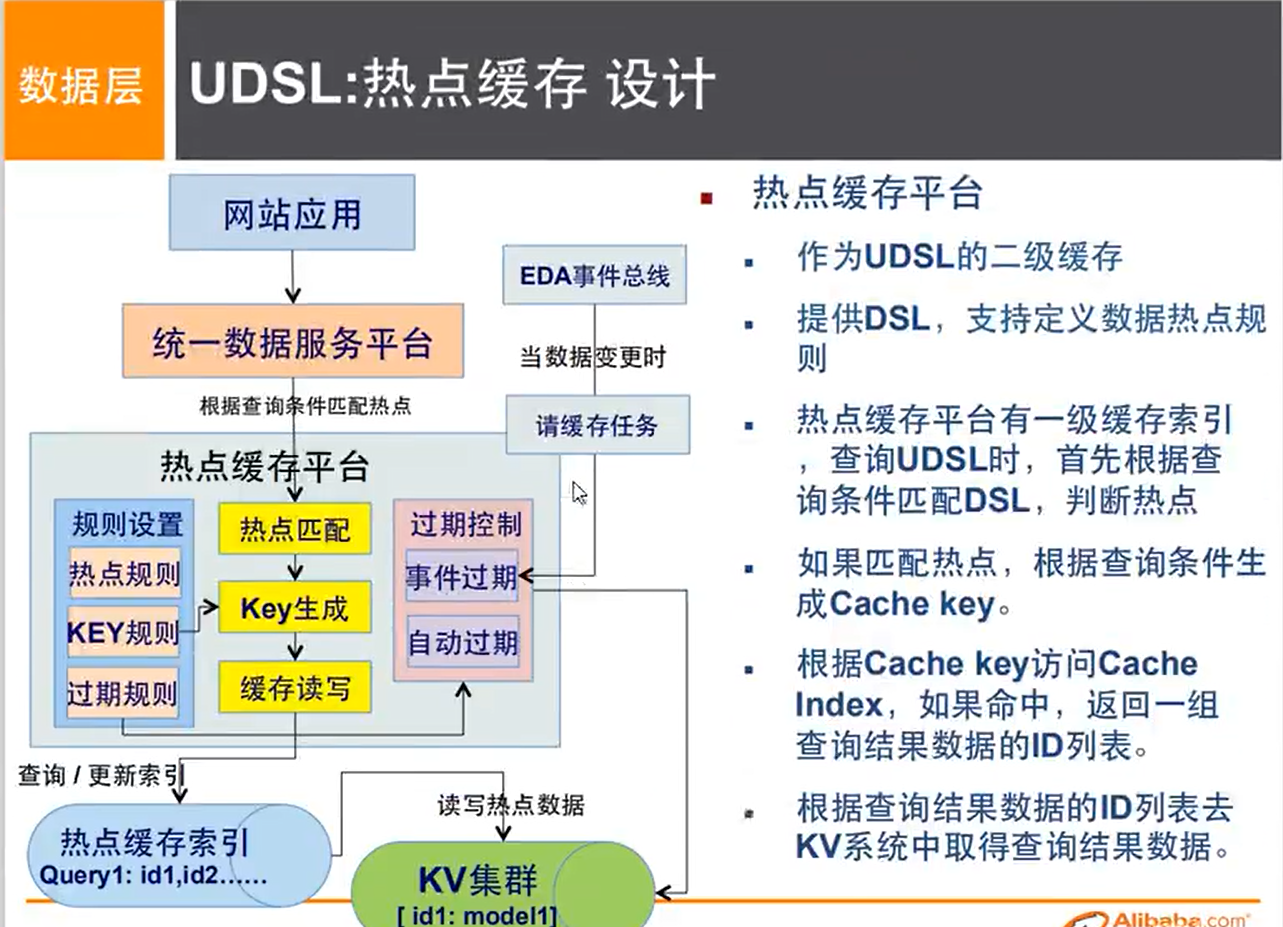
NoSQL的四大分类
kv键值对
- 新浪:redis
- 美团:redis + Tair
- 阿里、百度:Redis + memcache
文档型数据库(bson格式,和json一样)
- MongoDB(一般必须要掌握)
- 基于分布式文件存储的数据库,C++编写的,主要用来处理大量的文档
- MongoDB是一个介于关系型数据库和非关系型数据库中,中间的产品。MongoDB是非关系型数据库中功能最丰富的,最像关系型数据库的。
列存储数据库
- HBase
- 分布式文件系统
图关系数据库
-
它不是存图形的,放的是关系。比如:朋友圈社交网络,广告推荐。
-
Neo4j,infoGrid
四者对比
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |