句子由单词构成,把句子表示成单词列表,则一个句子在一个语料库出现的概率为:
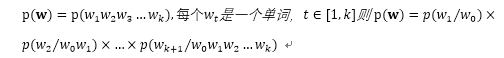
而利用极大似然估计可以计算每个后验概率:
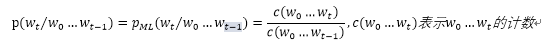
随着句子长度的增大,语料库极有可能统计不到长句子的频次,导致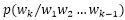 =0
=0
马尔科夫链:给定时间线上一串事件顺序发生,每个事件发生概率只取决于前一个事件。
(bigram) 模型: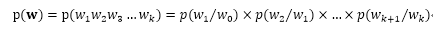 ,即每个单词出现的概率仅取决于该单词前一个单词。
,即每个单词出现的概率仅取决于该单词前一个单词。
(n-gram) 模型:  ,每个单词出现的概率仅取决于该单词之前的n-1个单词。
,每个单词出现的概率仅取决于该单词之前的n-1个单词。
(n=1是一元语法,n=3是三元语法;n>=4时,数据稀疏和计算代价又变得显著起来。)
所以可以将一段文本中相邻两个字符构成的所有二元语法作为词。而不一定需要分词。(这就要构建一个质量高,分量足的语料库(人工标注))
如何训练一个语言模型:
根据上面的概率公式,我们需要统计这些语法频次,通过极大似然估计和平滑策略,最终估计任意句子的概率分布。
步骤一:我们需要一个“正确答案”,即经过分词后的语料库,这些句子是人为认可的。
步骤二:我们要从语料库中的句子中“切片”,以二元语法为例,我们要求得两个单词在“一块”的频次
步骤三:拿到一个新句子,每一种分词方式代表一种路径。而两个词一同出现可以用概率来表示,这时任务目标变成了解决有向无环图的最长路径问题。
而句子中会有一些常用单词对分类决策的帮助不大,消除这些单词的影响,可以用停用词表和卡方非参数检验
卡方非参数检验:
与所分的类别独立性很高的词语,不适合做为特征。
如果类别有多个时,我们可以多次计算某个特征卡方值,取最大的卡方值。