本系列是针对于DataWhale学习小组的笔记,从一个对统计学和机器学习理论基础薄弱的初学者角度出发,在小组学习资料和其他网络资源的基础上,对知识进行总结和整理,今后有了新的理解可能还会不断完善。由于水平实在有限,不免产生谬误,欢迎读者多多批评指正。如需要转载请与博主联系,谢谢
比赛核心思路
赛题内容理解
-
比赛目标及数据
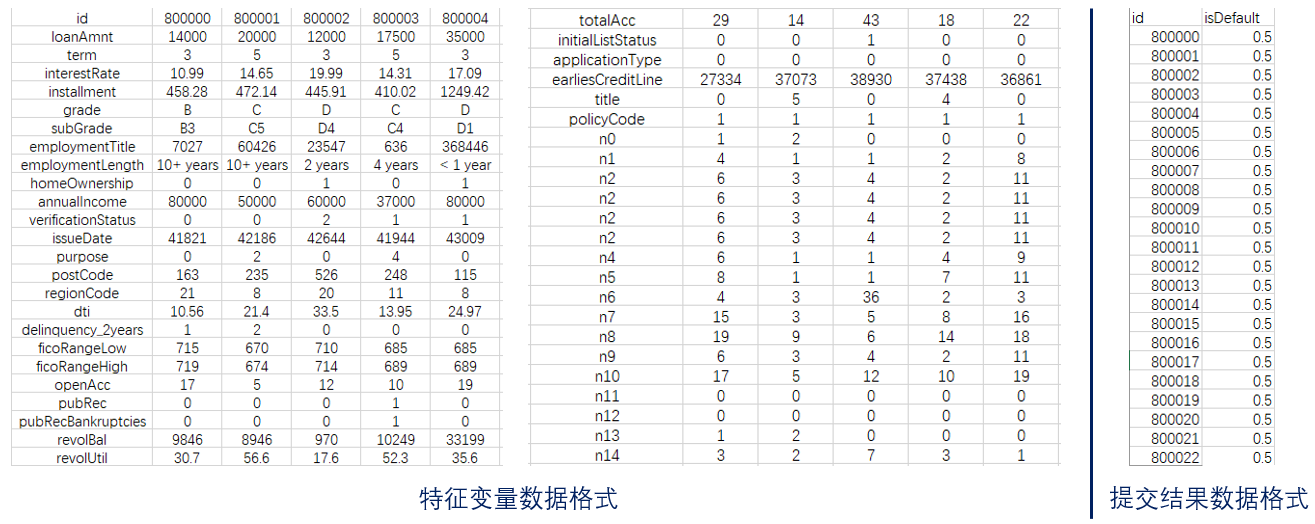
本场比赛的目标属于典型的分类问题,即依靠某信贷平台提供的超过120万条贷款记录,来构建预测未知新用户是否违约的模型。提供的训练集train.csv中包括各类与用户贷款信用相关的47列变量信息,其中15列为匿名变量,其中部分数据可能出错或空缺,因此需要进行分析和预处理,除此之外还有一列isDefault数据代表该用户是否违约(数值为1则违约,0则未违约),总共80万条数据;提供的测试集testA.csv用于选手进行线下验证,除没有标签isDefault外其他特征信息与训练集类似,总共20万条。47条样本特征字段及其含义如下图所示:

训练集特征的数据格式及最终预测结果的提交数据格式如下图所示(注意提交的数据为待预测用户id及对应的0-1之间的违约概率):
-
金融风控预测常用指标
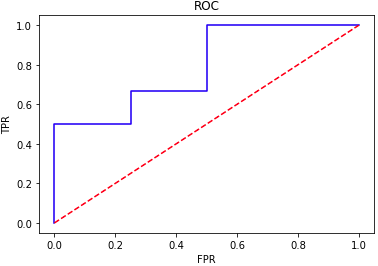
- ROC(Receiver Operating Characteristic)即“受试者工作特征”曲线常被用来评价分类模型的效果。在之前的新闻文本分类赛中我们曾经介绍了分类模型评估的几个基本指标,即样例可根据其真实类别与学习器所预测类别的组合划分为真正例(true positive,TP)——将正例正确预测为正例、假正例(false positive,FP)——将负例错误的预测为正例、真反例(true negative,TN)——将负例正确的预测为负例、假反例(false negative,FN)——将正例错误预测为负例四种情形。而在这里我们又需要引入假正例率(FPR)和真正例率(TPR)的概念,其计算公式如下:
ROC曲线所在的二维空间将FPR定义为X轴,TPR定义为Y轴(两个轴的坐标值都从0-1变化)。作图时我们首先需要设定从高到低的一系列判定阈值用于区分模型输出样例的类别(由于我们模型会针对每条测试样本输出0-1之间的一个概率值,因此具体标签值是0还是1需要设定一个阈值来判别,模型输出概率高于此阈值时认为此条样例被归为类别1,否则被归为类别0),每取一个阈值时都会获得一个不同的样本输出类别分布,因此可以计算出一组FPR、TPR的值。将不同阈值下计算出的FPR及TPR作为横纵坐标在图中画出对应的点,然后用线连接起来即获得了我们需要的ROC曲线。
# ROC曲线示例
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
import numpy as np
y_pred = np.random.rand(10)
y_true = np.array([0, 1, 1, 0, 1, 0, 1, 1, 0, 1])
FPR,TPR,thresholds=roc_curve(y_true, y_pred, pos_label=1)
plt.title('ROC')
plt.plot(FPR, TPR,'b')
plt.plot([0,1],[0,1],'r--')
plt.ylabel('TPR')
plt.xlabel('FPR')
plt.show()
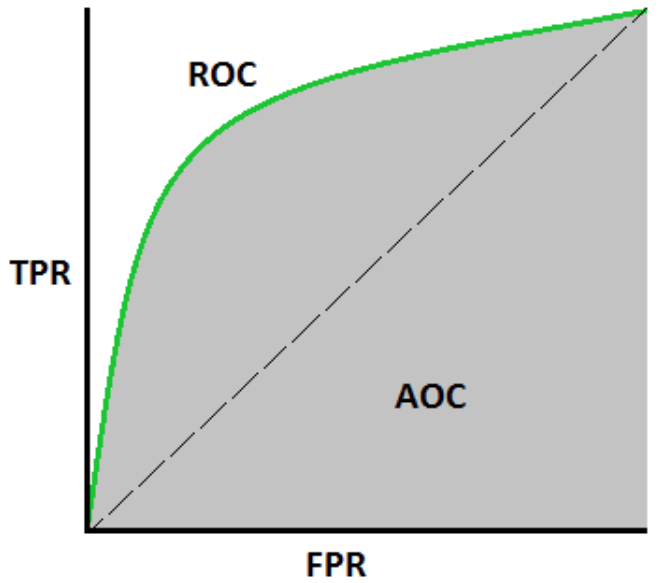
- 线下面积AUC(Area Under Curve)被定义为在ROC图中由ROC曲线及其右侧和下方的坐标轴围成的图形面积。一般ROC曲线位于对角线y=x的上方,因此取值范围在0.5~1之间(ROC横纵坐标构成的方形总面积为1)。当AUC值越接近于1,则认为模型预测准确性越高,反之则越低。如下图所示:
- KS(Kolmogorov-Smirnov)曲线同样利用了TPR和FPR指标,但将二者均当作纵轴,横轴为0~1之间等间隔划分的n个阈值,每个阈值取值下可计算出一组TPR和FPR值,因此可以分别绘制出TPR和FPR随判定阈值变化的两条曲线。通常TPR曲线在上,FPR曲线在下,二者之间差值的最大值即为KS值。一般来说KS>20%即说明模型效果良好,KS>75%时区分效果过好可能存在问题。
# KS值计算示例
from sklearn.metrics import roc_curve
import numpy as np
y_pred = np.random.rand(10)
y_true = np.array([0, 1, 1, 0, 1, 0, 1, 1, 0, 1])
FPR,TPR,thresholds=roc_curve(y_true, y_pred)
KS=abs(FPR-TPR).max()
print('KS值=',KS)
'''
>> KS值= 0.5833333333333334
'''
数据分析及预处理
- 数据读取和查看
# -*- coding: UTF-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
import warnings
import pandas.util.testing as tm
warnings.filterwarnings('ignore')
data_train = pd.read_csv('D://人工智能资料//数据比赛//贷款风险预测//train.csv') # 读取训练集
# pd.read_csv中加入nrows=n参数可设置读取文件的前n行(对于大文件);chunksize=m参数可以将数据读取为可迭代的形式,其中每一组有m个点存为一个DataFrame
data_test_a = pd.read_csv('D://人工智能资料//数据比赛//贷款风险预测//testA.csv') # 读取测试集
print(data_test_a.shape)
'''
(200000, 48)
'''
print(data_train.shape)
'''
(800000, 47)
'''
print(data_train.columns)
'''
Index(['id', 'loanAmnt', 'term', 'interestRate', 'installment', 'grade',
'subGrade', 'employmentTitle', 'employmentLength', 'homeOwnership',
'annualIncome', 'verificationStatus', 'issueDate', 'isDefault',
'purpose', 'postCode', 'regionCode', 'dti', 'delinquency_2years',
'ficoRangeLow', 'ficoRangeHigh', 'openAcc', 'pubRec',
'pubRecBankruptcies', 'revolBal', 'revolUtil', 'totalAcc',
'initialListStatus', 'applicationType', 'earliesCreditLine', 'title',
'policyCode', 'n0', 'n1', 'n2', 'n2.1', 'n4', 'n5', 'n6', 'n7', 'n8',
'n9', 'n10', 'n11', 'n12', 'n13', 'n14'],
dtype='object')
'''
print(data_train.info()) # 获得数据类型
'''
# 以下只展示一部分,实际上可以获得完整信息
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 800000 entries, 0 to 799999
Data columns (total 47 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 800000 non-null int64
1 loanAmnt 800000 non-null float64
2 term 800000 non-null int64
3 interestRate 800000 non-null float64
4 installment 800000 non-null float64
5 grade 800000 non-null object
6 subGrade 800000 non-null object
7 employmentTitle 799999 non-null float64
8 employmentLength 753201 non-null object
9 homeOwnership 800000 non-null int64
...
44 n12 759730 non-null float64
45 n13 759730 non-null float64
46 n14 759730 non-null float64
dtypes: float64(33), int64(9), object(5)
memory usage: 286.9+ MB
None
'''
print(data_train.describe()) # 获得一些基本统计量,直接用data_train.describe()即可得到可移动查看的表格
'''
id loanAmnt term interestRate
count 800000.000000 800000.000000 800000.000000 800000.000000
mean 399999.500000 14416.818875 3.482745 13.238391
std 230940.252015 8716.086178 0.855832 4.765757
min 0.000000 500.000000 3.000000 5.310000
25% 199999.750000 8000.000000 3.000000 9.750000
50% 399999.500000 12000.000000 3.000000 12.740000
75% 599999.250000 20000.000000 3.000000 15.990000
max 799999.000000 40000.000000 5.000000 30.990000
...
n11 n12 n13 n14
count 730248.000000 759730.000000 759730.000000 759730.000000
mean 0.000815 0.003384 0.089366 2.178606
std 0.030075 0.062041 0.509069 1.844377
min 0.000000 0.000000 0.000000 0.000000
25% 0.000000 0.000000 0.000000 1.000000
50% 0.000000 0.000000 0.000000 2.000000
75% 0.000000 0.000000 0.000000 3.000000
max 4.000000 4.000000 39.000000 30.000000
'''
print(data_train.head(3).append(data_train.tail(3))) # 查看原始数据的前三行和最后三行
'''
id loanAmnt term interestRate installment grade subGrade
0 0 35000.0 5 19.52 917.97 E E2
1 1 18000.0 5 18.49 461.90 D D2
2 2 12000.0 5 16.99 298.17 D D3
799997 799997 6000.0 3 13.33 203.12 C C3
799998 799998 19200.0 3 6.92 592.14 A A4
799999 799999 9000.0 3 11.06 294.91 B B3
employmentTitle employmentLength homeOwnership ... n5 n6
0 320.0 2 years 2 ... 9.0 8.0
1 219843.0 5 years 0 ... NaN NaN
2 31698.0 8 years 0 ... 0.0 21.0
799997 2582.0 10+ years 1 ... 4.0 26.0
799998 151.0 10+ years 0 ... 10.0 6.0
799999 13.0 5 years 0 ... 3.0 4.0
n7 n8 n9 n10 n11 n12 n13 n14
0 4.0 12.0 2.0 7.0 0.0 0.0 0.0 2.0
1 NaN NaN NaN 13.0 NaN NaN NaN NaN
2 4.0 5.0 3.0 11.0 0.0 0.0 0.0 4.0
799997 4.0 10.0 4.0 5.0 0.0 0.0 1.0 4.0
799998 12.0 22.0 8.0 16.0 0.0 0.0 0.0 5.0
799999 4.0 8.0 3.0 7.0 0.0 0.0 0.0 2.0
[6 rows x 47 columns]
'''
- 数据分析
print(f'There are {data_train.isnull().any().sum()} columns in train dataset with missing values.') # df.isnull().any()会判断哪些列包含缺失值,该列存在缺失值则返回True,反之False;加上.sum()则可求得列数
'''
There are 22 columns in train dataset with missing values.
'''
have_null_fea_dict = (data_train.isnull().sum()/len(data_train)).to_dict() # 这一部分用于判断缺失率高于某个值的特征列
fea_null_moreThanHalf = {}
for key,value in have_null_fea_dict.items():
if value > 0.05: # 记录缺失率高于5%的列及其缺失值比率
fea_null_moreThanHalf[key] = value
print(fea_null_moreThanHalf)
missing = data_train.isnull().sum()/len(data_train)
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar() # 绘制缺失率分布图
'''
{'employmentLength': 0.05849875, 'n0': 0.0503375, 'n1': 0.0503375, 'n2': 0.0503375, 'n2.1': 0.0503375, 'n5': 0.0503375, 'n6': 0.0503375, 'n7': 0.0503375, 'n8': 0.05033875, 'n9': 0.0503375, 'n11': 0.08719, 'n12': 0.0503375, 'n13': 0.0503375, 'n14': 0.0503375}
'''
one_value_fea = [col for col in data_train.columns if data_train[col].nunique() == 1] # 寻找训练集和测试集中是否有特征列仅出现了一种取值
one_value_fea_test = [col for col in data_test_a.columns if data_test_a[col].nunique() == 1]
print(one_value_fea)
print(one_value_fea_test)
'''
['policyCode']
['policyCode']
'''
numerical_fea = list(data_train.select_dtypes(exclude=['object']).columns) # 筛选数值型特征
category_fea = list(filter(lambda x: x not in numerical_fea,list(data_train.columns))) # 筛选类别型特征
def get_numerical_serial_fea(data,feas):
numerical_serial_fea = []
numerical_noserial_fea = []
for fea in feas:
temp = data[fea].nunique()
if temp <= 10:
numerical_noserial_fea.append(fea)
continue
numerical_serial_fea.append(fea)
return numerical_serial_fea,numerical_noserial_fea
numerical_serial_fea,numerical_noserial_fea = get_numerical_serial_fea(data_train,numerical_fea)
print(numerical_serial_fea) # 查看哪些是连续型变量
'''
['id', 'loanAmnt', 'interestRate', 'installment', 'employmentTitle', 'annualIncome', 'purpose', 'postCode', 'regionCode', 'dti', 'delinquency_2years', 'ficoRangeLow', 'ficoRangeHigh', 'openAcc', 'pubRec', 'pubRecBankruptcies', 'revolBal', 'revolUtil', 'totalAcc', 'title', 'n0', 'n1', 'n2', 'n2.1', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n13', 'n14']
'''
print(numerical_noserial_fea) # 查看哪些是离散型变量
'''
['term', 'homeOwnership', 'verificationStatus', 'isDefault', 'initialListStatus', 'applicationType', 'policyCode', 'n11', 'n12']
'''
print(data_train['homeOwnership'].value_counts()) # 查看某个离散型变量取值的分布情况
'''
0 395732
1 317660
2 86309
3 185
5 81
4 33
Name: homeOwnership, dtype: int64
'''
f = pd.melt(data_train, value_vars=numerical_serial_fea) # 筛选连续型数值变量
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False) # 绘制分布直方图(会绘制所有连续变量,下面只展示两个),注意它的输入只能是df或Series
g = g.map(sns.distplot, "value")

# 也可以单独绘制某个特征的取值分布图,看变量(或取log后的变量)是否符合正态分布,
plt.figure(figsize=(16,12))
plt.suptitle('Transaction Values Distribution', fontsize=22)
plt.subplot(221)
sub_plot_1 = sns.distplot(data_train['loanAmnt'])
sub_plot_1.set_title("loanAmnt Distribuition", fontsize=18)
sub_plot_1.set_xlabel("")
sub_plot_1.set_ylabel("Probability", fontsize=15)
plt.subplot(222)
sub_plot_2 = sns.distplot(np.log(data_train['loanAmnt']))
sub_plot_2.set_title("loanAmnt (Log) Distribuition", fontsize=18)
sub_plot_2.set_xlabel("")
sub_plot_2.set_ylabel("Probability", fontsize=15)

print(category_fea) # 观察哪些变量是类别型变量
'''
['grade', 'subGrade', 'employmentLength', 'issueDate', 'earliesCreditLine']
'''
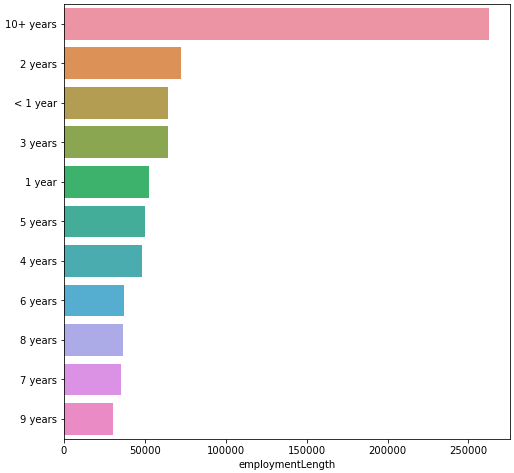
print(data_train['employmentLength'].value_counts()) # 显示其中一个类型变量的取值分布
'''
10+ years 262753
2 years 72358
< 1 year 64237
3 years 64152
1 year 52489
5 years 50102
4 years 47985
6 years 37254
8 years 36192
7 years 35407
9 years 30272
Name: employmentLength, dtype: int64
'''
plt.figure(figsize=(8, 8))
sns.barplot(data_train["employmentLength"].value_counts(dropna=False)[:20],
data_train["employmentLength"].value_counts(dropna=False).keys()[:20])
plt.show()
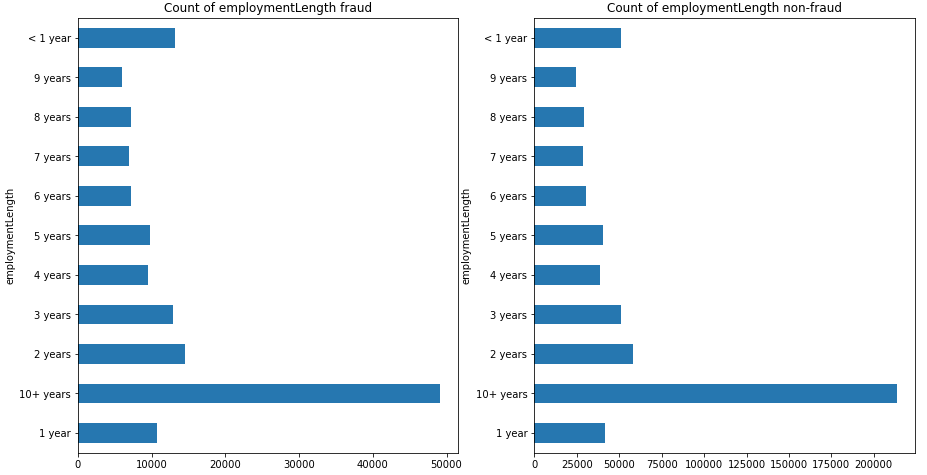
train_loan_fr = data_train.loc[data_train['isDefault'] == 1]
train_loan_nofr = data_train.loc[data_train['isDefault'] == 0] # 分别取出标签'isDefault'等于0和1的样本集
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 8))
train_loan_fr.groupby('employmentLength')['employmentLength'].count().plot(kind='barh', ax=ax1, title='Count of employmentLength fraud')
train_loan_nofr.groupby('employmentLength')['employmentLength'].count().plot(kind='barh', ax=ax2, title='Count of employmentLength non-fraud') # 统计并绘制两种标签取值下该类别特征的取值(类别)分布
plt.show()
import pandas_profiling # 生成数据报告
pfr = pandas_profiling.ProfileReport(data_train)
pfr.to_file("./example.html")
- 特征预处理
- 缺失值处理:首先要考虑对数据集中缺失的特征进行处理,使其能够以正确的方式输入到之后的模型中。
# data_train = data_train.fillna(0) # 用指定值替换缺失值
# data_train = data_train.fillna(axis=0,method='ffill') # axis=0按行方向进行填充,=1沿列方向进行填充,'ffill'/’bfill'用该方向的前一个/后一个值填充,可用limit=n限制连续缺失时最多填充n个值
# data_train[numerical_fea] = data_train[numerical_fea].fillna(data_train[numerical_fea].median()) # 按照中位数填充数值型特征
data_train[numerical_fea] = data_train[numerical_fea].fillna(data_train[numerical_fea].mean()) # 按照平均数填充数值型特征
data_test_a[category_fea] = data_test_a[category_fea].fillna(data_train[category_fea].mode()) # 按照众数填充类别型特征
data_train.isnull().sum() # 查看此时缺失值的统计情况(这里不再展示结果)
- 时间格式处理:将以字符串存储的、不规范的时间数据转化为时间戳存储的、规范化的时间格式
for data in [data_train, data_test_a]:
data['issueDate'] = pd.to_datetime(data['issueDate'],format='%Y-%m-%d') # 后一个参数代表需要按什么格式从前一个输入的序列中进行匹配,下一行同理
startdate = datetime.datetime.strptime('2007-06-01', '%Y-%m-%d')
#构造时间特征
data['issueDateDT'] = data['issueDate'].apply(lambda x: x-startdate).dt.days
print(type(data['issueDate'][0]))
'''
<class 'pandas._libs.tslibs.timestamps.Timestamp'> 可以看到该列数据的类型由字符串变为了pd的时间戳
'''
- 将类别特征转化为数值特征:如'employmentLength'一列以'1 year'、'2 years'等作为特征取值,难以直接输入模型中,需要转化为数值标签处理
def employmentLength_to_int(s): # 自定义函数用于提取年份信息并转化为相应的数值
if pd.isnull(s):
return s
else:
return np.int8(s.split()[0])
for data in [data_train, data_test_a]:
data['employmentLength'].replace(to_replace='10+ years', value='10 years', inplace=True) # '10+ years'这一类取值需转化为'10 years'格式后才方便统一处理,下一行同理
data['employmentLength'].replace('< 1 year', '0 years', inplace=True)
data['employmentLength'] = data['employmentLength'].apply(employmentLength_to_int) # .apply将每个取值应用到函数中,并以返回值替代原值
data['employmentLength'].value_counts(dropna=False).sort_index()
'''
0.0 15989
1.0 13182
2.0 18207
3.0 16011
4.0 11833
5.0 12543
6.0 9328
7.0 8823
8.0 8976
9.0 7594
10.0 65772
NaN 11742
Name: employmentLength, dtype: int64
'''
# 同理对'earliesCreditLine'一列进行处理
data_train['earliesCreditLine'].sample(5)
'''
519915 Sep-2002
564368 Dec-1996
768209 May-2004
453092 Nov-1995
763866 Sep-2000
Name: earliesCreditLine, dtype: object
'''
for data in [data_train, data_test_a]:
data['earliesCreditLine'] = data['earliesCreditLine'].apply(lambda s: int(s[-4:]))
# 对'grade'这种取值有优先顺序的特征可以使用连续的数字进行映射
for data in [data_train, data_test_a]:
data['grade'] = data['grade'].map({'A':1,'B':2,'C':3,'D':4,'E':5,'F':6,'G':7})
# 类型数在2之上,又不是高维稀疏的,且纯分类特征,可以用one hot进行编码
for data in [data_train, data_test_a]:
data = pd.get_dummies(data, columns=['subGrade', 'homeOwnership', 'verificationStatus', 'purpose', 'regionCode'], drop_first=True)
- 异常值处理:处理时要尽可能辨别该异常值到底是偶然误差还是代表了某种罕见的现象,前者可以直接删除该样本,后者则要纳入模型的考虑之中。
# 常用方法:均方差判别异常值,然后分析异常值与样本标签之间的关联
def find_outliers_by_3segama(data,fea): # 3σ原则:正态分布中大约 68% 的数据值会在均值的一个标准差范围内,大约 95% 会在两个标准差范围内,大约 99.7% 会在三个标准差范围内
data_std = np.std(data[fea])
data_mean = np.mean(data[fea])
outliers_cut_off = data_std * 3
lower_rule = data_mean - outliers_cut_off
upper_rule = data_mean + outliers_cut_off
data[fea+'_outliers'] = data[fea].apply(lambda x:str('异常值') if x > upper_rule or x < lower_rule else '正常值')
return data
data_train = data_train.copy()
for fea in numerical_fea:
data_train = find_outliers_by_3segama(data_train,fea)
print(data_train[fea+'_outliers'].value_counts())
print(data_train.groupby(fea+'_outliers')['isDefault'].sum())
print('*'*10)
# 结果不在这里展示,但是分析可得异常值在两个标签上的分布与整体的分布无明显差异,因此可认为这些异常值属于偶然误差,可以删除
#删除异常值
for fea in numerical_fea:
data_train = data_train[data_train[fea+'_outliers']=='正常值']
data_train = data_train.reset_index(drop=True)
- 数据分桶:分桶操作实际上是对特征取值的模糊化和离散化,可以降低变量的复杂性,减少噪音的影响,也提升模型的稳定性。分桶既可以对连续变量使用,也可以对较多取值的离散变量使用。分箱的关键在于找到合适的切分点,尽量保证每个箱内都有一定的数据量(不要出现空桶),也不要让某个桶内样本的标签相同。这里有几种最简单的办法:
# 方法一:固定间隔分桶
# 通过除法映射到间隔均匀的分箱中,每个分箱的取值范围都是loanAmnt/1000
data['loanAmnt_bin1'] = np.floor_divide(data['loanAmnt'], 1000)
# 方法二:指数间隔分桶
## 通过对数函数映射到指数宽度分箱
data['loanAmnt_bin2'] = np.floor(np.log10(data['loanAmnt']))
# 方法三:分位数分桶
data['loanAmnt_bin3'] = pd.qcut(data['loanAmnt'], 10, labels=False)
模型建立与调参
- 数据准备
在完成上面部分所述的数据分析和预处理过程后,我们可以着手准备训练和测试模型所用的数据。可以看一下baseline中的代码(数据导入和特征预处理部分都省略):
features = [f for f in data.columns if f not in ['id','issueDate','isDefault']] # 除这三列之外均作为模型特征记录下来
# baseline中为了处理特征方便已将两个数据集合并data = pd.concat([train, testA], axis=0, ignore_index=True),在这里要重新分开
train = data[data.isDefault.notnull()].reset_index(drop=True)
test = data[data.isDefault.isnull()].reset_index(drop=True)
x_train = train[features] # 选取训练集中做为模型特征的列组成训练输入
x_test = test[features] # 选取测试集中做为模型特征的列组成测试输入
y_train = train['isDefault'] # 挑出训练集样本的标签列
- 模型构建
这里说的模型构建实际上仅是定义一个函数来封装机器学习模型的操作流程和参数,因为我们只是调用现成模块,因此不用自己写算法的实现细节。baseline中选用了三种常见的决策树集成类的模型。
import lightgbm as lgb
import xgboost as xgb
# from catboost import CatBoostRegressor # catboost模块在我自己的电脑上安装总是出问题,因此无法使用
def cv_model(clf, train_x, train_y, test_x, clf_name):
folds = 5
seed = 2020
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
train = np.zeros(train_x.shape[0])
test = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
if clf_name == "lgb":
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'min_child_weight': 5,
'num_leaves': 2 ** 5,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.1,
'seed': 2020,
'nthread': 28,
'n_jobs':24,
'silent': True,
'verbose': -1,
}
model = clf.train(params, train_matrix, 50000, valid_sets=[train_matrix, valid_matrix], verbose_eval=200,early_stopping_rounds=200)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
# print(list(sorted(zip(features, model.feature_importance("gain")), key=lambda x: x[1], reverse=True))[:20])
if clf_name == "xgb":
train_matrix = clf.DMatrix(trn_x , label=trn_y)
valid_matrix = clf.DMatrix(val_x , label=val_y)
test_matrix = clf.DMatrix(test_x)
params = {'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'gamma': 1,
'min_child_weight': 1.5,
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.04,
'tree_method': 'exact',
'seed': 2020,
'nthread': 36,
"silent": True,
}
watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]
model = clf.train(params, train_matrix, num_boost_round=50000, evals=watchlist, verbose_eval=200, early_stopping_rounds=200)
val_pred = model.predict(valid_matrix, ntree_limit=model.best_ntree_limit)
test_pred = model.predict(test_matrix , ntree_limit=model.best_ntree_limit)
'''
if clf_name == "cat":
params = {'learning_rate': 0.05, 'depth': 5, 'l2_leaf_reg': 10, 'bootstrap_type': 'Bernoulli',
'od_type': 'Iter', 'od_wait': 50, 'random_seed': 11, 'allow_writing_files': False}
model = clf(iterations=20000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
cat_features=[], use_best_model=True, verbose=500)
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
train[valid_index] = val_pred
test = test_pred / kf.n_splits
cv_scores.append(roc_auc_score(val_y, val_pred))
print(cv_scores)
'''
print("%s_scotrainre_list:" % clf_name, cv_scores)
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
print("%s_score_std:" % clf_name, np.std(cv_scores))
return train, test
- 模型训练和预测
# 这三个函数实际上仅相当于将模型名称加入到函数名中
def lgb_model(x_train, y_train, x_test):
lgb_train, lgb_test = cv_model(lgb, x_train, y_train, x_test, "lgb")
return lgb_train, lgb_test
def xgb_model(x_train, y_train, x_test):
xgb_train, xgb_test = cv_model(xgb, x_train, y_train, x_test, "xgb")
return xgb_train, xgb_test
'''
def cat_model(x_train, y_train, x_test):
cat_train, cat_test = cv_model(CatBoostRegressor, x_train, y_train, x_test, "cat")
return cat_train, cat_test
'''
lgb_train, lgb_test = lgb_model(x_train, y_train, x_test) # lgb模型训练(下面仅展示训练过程中的部分输出)
'''
************************************ 1 ************************************
Training until validation scores don't improve for 200 rounds
[200] training's auc: 0.742781 valid_1's auc: 0.730238
[400] training's auc: 0.755391 valid_1's auc: 0.731421
[600] training's auc: 0.766076 valid_1's auc: 0.731637
[800] training's auc: 0.776276 valid_1's auc: 0.731616
[1000] training's auc: 0.785706 valid_1's auc: 0.731626
Early stopping, best iteration is:
[850] training's auc: 0.778637 valid_1's auc: 0.731771
************************************ 2 ************************************
Training until validation scores don't improve for 200 rounds
[200] training's auc: 0.743829 valid_1's auc: 0.726629
[400] training's auc: 0.756563 valid_1's auc: 0.728084
[600] training's auc: 0.767445 valid_1's auc: 0.728527
[800] training's auc: 0.777538 valid_1's auc: 0.728466
Early stopping, best iteration is:
[652] training's auc: 0.770397 valid_1's auc: 0.728656
************************************ 3 ************************************
...
'''
xgb_train, xgb_test = xgb_model(x_train, y_train, x_test) # xgb模型训练(输出省略)
rh_test = lgb_test*0.5 + xgb_test*0.5 # 将模型预测值进行融合可能有助于提升预测效果
testA['isDefault'] = rh_test
testA[['id','isDefault']].to_csv('test_sub.csv', index=False) # 生成结果文件
模型融合
模型融合一般是比赛后期上分的关键技术之一,其基本思想就是通过对多个单模型的预测结果进行汇总融合以提升整体预测效果。
常用的模型融合方法可以分为以下几类:
- 平均法
即简单的将不同模型的输出结果(前提是格式一致)进行相加或加权相加后取平均。这是最简单的办法,有时也会取得不错的效果,类似上一部分内容中所展示的那样:
rh_test = lgb_test*0.3 + xgb_test*0.7
- 投票法
对于分类问题,可以利用几个不同模型进行预测,然后利用预测的结果对每条测试样本的标签类别进行投票,以此决定测试集的预测结果。
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=4, min_child_weight=2, subsample=0.7,objective='binary:logistic')
vclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('xgb', clf3)]) # 简单投票
# vclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('xgb', clf3)], voting='soft', weights=[2, 1, 1]) # 加权投票
vclf = vclf .fit(x_train,y_train)
print(vclf .predict(x_test))
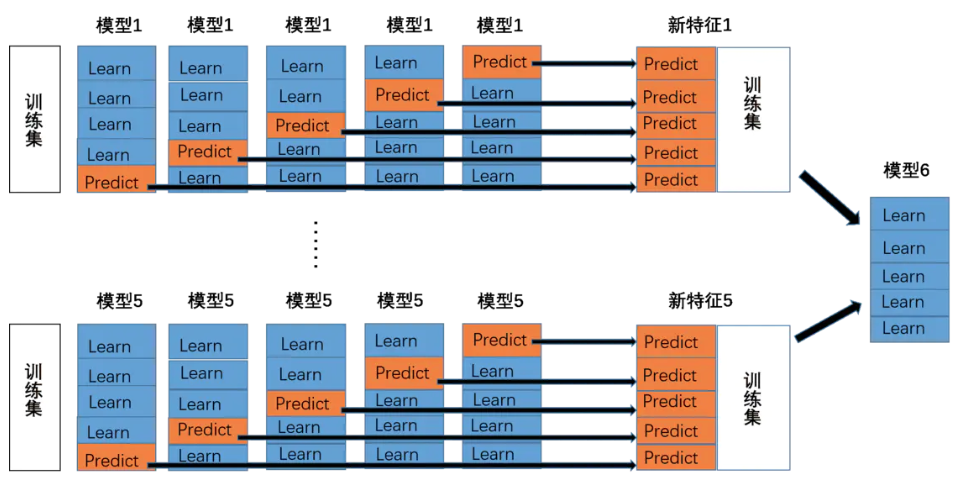
- stacking
stacking的核心思想就是建立两层预测模型来获得更精准的预测效果。假设第一层由五个不同类的模型组成,则如下图所示,利用类似五折验证的方式分别获得每个模型对训练集的预测结果,将这些结果融合后作为第二层模型的训练数据(注意这里利用预测的结果作为一列新的特征,因此第二层模型确实存在过拟合的风险),同样测试集也通过第一次模型预测结果的融合获得一列新的特征,然后利用第二层模型进行预测。
import warnings
warnings.filterwarnings('ignore')
import itertools
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from mlxtend.plotting import plot_learning_curves
from mlxtend.plotting import plot_decision_regions
# 以python自带的鸢尾花数据集为例
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
label = ['KNN', 'Random Forest', 'Naive Bayes', 'Stacking Classifier']
clf_list = [clf1, clf2, clf3, sclf]
fig = plt.figure(figsize=(10,8))
gs = gridspec.GridSpec(2, 2)
grid = itertools.product([0,1],repeat=2)
clf_cv_mean = []
clf_cv_std = []
for clf, label, grd in zip(clf_list, label, grid):
scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy')
print("Accuracy: %.2f (+/- %.2f) [%s]" %(scores.mean(), scores.std(), label))
clf_cv_mean.append(scores.mean())
clf_cv_std.append(scores.std())
clf.fit(X, y)
- blending
blending的思路与stacking类似,最关键的区别在于blending对于每个模型分别留出训练集的一部分作为预测对象,然后将预测的结果按顺序排列作为第二层训练集的新特征,而不是分别进行n者验证后融合获得新特征列。

# 以python自带的鸢尾花数据集为例
data_0 = iris.data
data = data_0[:100,:]
target_0 = iris.target
target = target_0[:100]
#模型融合中基学习器
clfs = [LogisticRegression(),
RandomForestClassifier(),
ExtraTreesClassifier(),
GradientBoostingClassifier()]
#切分一部分数据作为测试集
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.3, random_state=914)
#切分训练数据集为d1,d2两部分
X_d1, X_d2, y_d1, y_d2 = train_test_split(X, y, test_size=0.5, random_state=914)
dataset_d1 = np.zeros((X_d2.shape[0], len(clfs)))
dataset_d2 = np.zeros((X_predict.shape[0], len(clfs)))
for j, clf in enumerate(clfs):
#依次训练各个单模型
clf.fit(X_d1, y_d1)
y_submission = clf.predict_proba(X_d2)[:, 1]
dataset_d1[:, j] = y_submission
#对于测试集,直接用这k个模型的预测值作为新的特征。
dataset_d2[:, j] = clf.predict_proba(X_predict)[:, 1]
print("val auc Score: %f" % roc_auc_score(y_predict, dataset_d2[:, j]))
#融合使用的模型
clf = GradientBoostingClassifier()
clf.fit(dataset_d1, y_d2)
y_submission = clf.predict_proba(dataset_d2)[:, 1]
print("Val auc Score of Blending: %f" % (roc_auc_score(y_predict, y_submission)))
参考资料:
- https://github.com/datawhalechina/team-learning-data-mining/tree/master/FinancialRiskControl Datawhale小组学习资料
- https://tianchi.aliyun.com/competition/entrance/531830/introduction 阿里云-天池零基础入门金融风控-贷款违约预测
- https://blog.csdn.net/qq_30992103/article/details/99730059 ROC曲线学习总结
- https://blog.csdn.net/anshuai_aw1/article/details/82498557 模型融合之stacking&blending原理及代码
- https://blog.csdn.net/wuzhongqiang/article/details/105012739 零基础数据挖掘入门系列(六) - 模型的融合技术大总结与结果部署