前言:笔者之前是cv方向,因为工作原因需要学习NLP相关的模型,因此特意梳理一下关于NLP的几个经典模型,由于有基础,这一系列不会关注基础内容或者公式推导,而是更侧重对整体原理的理解。顺便推荐两个很不错的github项目——开箱即用的中文教程以及算法更全但是有些跑不通的英文教程。
一. 从encode和decode说起
encode和decode是一个非常常见的结构。encode可以理解为从输入得到特征的过程,而decode可以理解为从特征得到结果的过程。同样适用https://zhuanlan.zhihu.com/p/28054589的RNN网络结构图来说明。
实际上,我们利用RNN由输入得到h1~h4这4个状态的过程就是encode,同理包括从image经过大量cnn得到feature等。而decode则是从特征得到结果,比如在图像分类问题中,这一步骤可能是对feature map做avgpool然后经过若干个fc和softmax得到类别概率。而在之前的RNN中,decode过程则是直接取最后一个状态h4,然后经过fc和softmax得到类别概率。
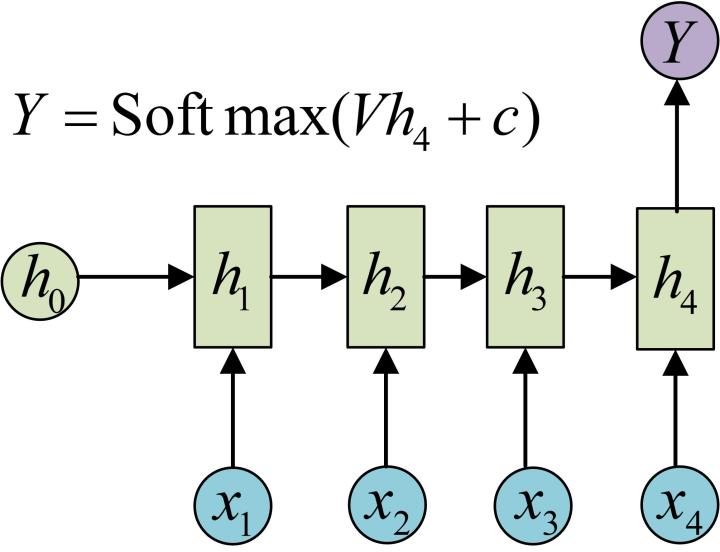
二. seq2seq与attention
原理
seq2seq指的是输入和输出都是序列的问题,比如翻译。在这种时候,显然是不能用之前RNN的思路的。但是实际上,两者并没有太大的差异。比如,我们完全可以使用相同的encode过程,用一个RNN来提取特征,但是我们每个(h_i)都经过fc和softmax,求出每个位置对应的最可能是什么词,这就是一个最简单的翻译网络了。当然直观上输入和输出必须是等长的,如果不等长,可以取两者最大公共长度补齐;或者也有其它方法,详情参考最上面给的博客。
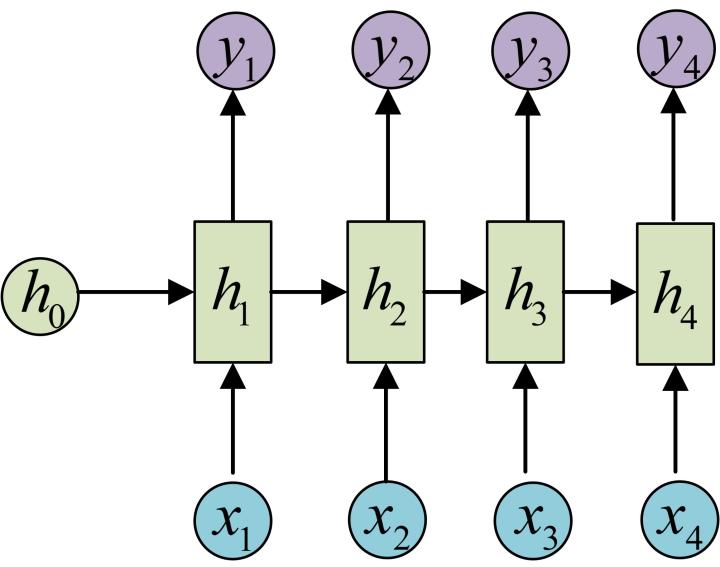
当然也有很多不同的操作,比如你可以给h1~h4做一个特征融合。然后用融合后的特征去decode,这里的c就代表从encode得到的最终用于decode的特征。这里我们可以把之前介绍的attention机制涌过来。
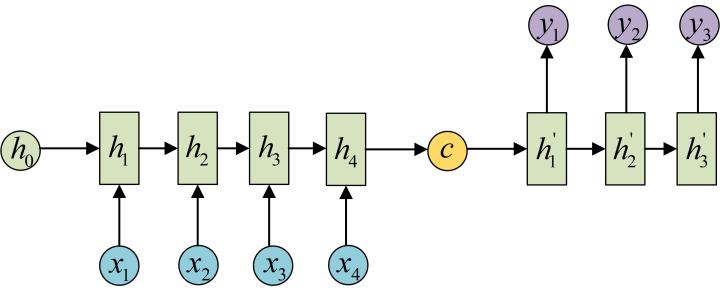
decode特征也可以是多个,比如现在是一个4对3的任务,有4个状态特征h1-h4,则可以用不同的注意力机制权重得到c1-c3,这里就是之前提到的翻译例子了:
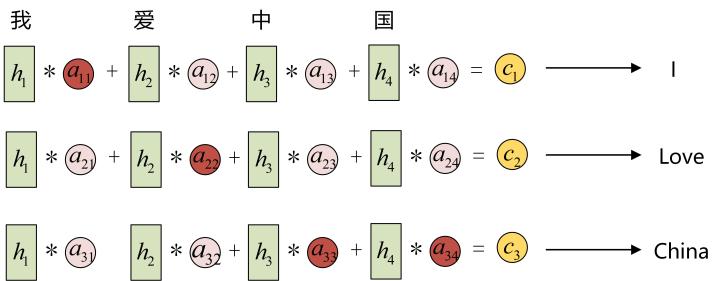
其它
Pytorch中,RNN和LSTM模块的输入和输出必须是等长的;意思是如果你输入是x个状态,那么输出也必然是x个状态。所以如果输入和输出是不等长的,需要自己填补到等长,Pytorch也提供了相关函数填补函数pad_sequence以及对应的解压函数。如果需要使用的可以自己了解。