1.概述
传统的user协同,先是找到topk相似user,再利用打分公式预测目标用户未有过行为item的评分,基于这个评分从大到小输出推荐。本次的回归推荐方法跟user协同也是大同小异,最主要的不同是回归推荐是学习用户的特征偏好,所以本方法用到了评分数据以及item的特征分布。这个item特征分布应是已知的,比如一件商品它可以是电子产品、娱乐产品、学习产品等的不同类别;一部电影可以是恐怖、娱乐、搞笑等类别,可以简单的用0,1表示该item是否具有某种特征或类别,或者是某种从属概率。
简单来説本方法是利用user特征与item特征分布去拟合评分矩阵。模型利用线性回归,采用梯度下降优化,目标是从用户评过分的item中学习出用户的特征分布(或可以称为用户特征画像)。
2.评分矩阵为 ,M个user,N个item。其中还有一个item的特征矩阵。
,M个user,N个item。其中还有一个item的特征矩阵。
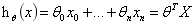 ,,其中x0=1,x维度:m*(n+1),利用线性回归来拟合评分。
,,其中x0=1,x维度:m*(n+1),利用线性回归来拟合评分。
3.损失为平方损失+L2正则项

其中, 是需要学习出的用户特征分布,x是项目的特征分布,rij是用户i对项目j的实际评分,k为特征数量。
是需要学习出的用户特征分布,x是项目的特征分布,rij是用户i对项目j的实际评分,k为特征数量。
4.使用SGD训练(达到迭代次数或loss小于阈值)
 ,其中1式中为k=0;2式中k>0。
,其中1式中为k=0;2式中k>0。
5.如果通过以上学习出用户的偏好分布,那么可以针对某个用户可以利用它的评分或偏好找到其最相似的用户,然后利用目标用户的偏好与其未评分的项目特征分布进行预估;或者某个用户没有特征偏好,可以利用该用户的评分计算出其最相似的用户,将其最相似用户学习出的偏好分布作为其自己的偏好,利用这个偏好和未评分的项目的特征分布进行预估。
以上第二种代码如下,完整(data from movielens-100k),https://github.com/jiangnanboy/recommendation_methods/blob/master/com/sy/reco/recommendation/content/contentregression.py
import numpy as np import math from com.sy.reco.similarity.cosine import Cosine ''' 这里使用正则化的线性回归方法,基于评分矩阵和item特征矩阵,训练用户偏好。 ''' class UserFeatureRegression(): ''' 初始化ratingMatrix,itemsFeatures,alpha, λ ratingMatrix:评分矩阵 itemsFeatures:项目的特征矩阵 alpha:学习速率 λ:正则化参数,以防过拟合 ''' def __init__(self,ratingMatrix,itemsFeatures,alpha,λ): self.ratingMatrix=ratingMatrix self.itemsFeaturesMatrix=itemsFeatures self.alpha=alpha self.λ=λ #预测 def predict(self,vec1,vec2): product=0. for a,b in zip(vec1,vec2): product+=a*b return product #迭代训练分解,max_iter:迭代次数,学习到所有的用户特征(画像) def iteration_train(self,max_iter): n_features = len(self.itemsFeaturesMatrix[0])+1 # 第0行,总共多少个特征,这里加1是线性回归中的截距项b=1 n_users=len(self.ratingMatrix)#用户数 n_items=len(self.ratingMatrix[0])#项目数 #将项目特征矩阵放入items_features中,第0列为截距项1 #其实就是为项目特征矩阵itemsFeaturesMatrix增加一列截距项全为1 items_features=np.ones((n_items,n_features)) items_features[:,1:]=self.itemsFeaturesMatrix items_features=items_features.astype(float) self.ratingMatrix=self.ratingMatrix.astype(float) #初始化用户特征矩阵,这里是需要求解的权重(在线性回归中) users_featuers=np.random.rand(n_users,n_features) users_featuers[:,0]=1.#第0列是截距项,这里设置为全1 #迭代求解,得到所有用户的特征 for iteration in range(max_iter): for user in range(n_users): for feature in range(n_features): if feature==0:#这里是截距项,不需要正则化 for item in range(n_items): if self.ratingMatrix[user,item]>0:#训练评过分的数据 #预测值与真实值的差 difference=self.predict(users_featuers[user],items_features[item])-self.ratingMatrix[user,item] users_featuers[user,feature]-=self.alpha*difference*items_features[item,feature]#items_features[item,feature]一项代表这个项目是否有此特征,有则是1,无则是0 else: for item in range(n_items): if self.ratingMatrix[user,item]>0:#训练评过分的数据 difference=self.predict(users_featuers[user],items_features[item])-self.ratingMatrix[user,item] users_featuers[user,feature]-=self.alpha*(difference*items_features[item,feature]+self.λ*users_featuers[user,feature]) self.users_features=users_featuers self.items_features=items_features # 预测误差训练,convergence:误差收敛,小于这个误差,停止 def convergence_train(self, convergence): n_features = len(self.itemsFeaturesMatrix[0]) + 1 # 第0行,总共多少个特征,这里加1是线性回归中的截距项b=1 n_users = len(self.ratingMatrix) # 用户数 n_items = len(self.ratingMatrix[0]) # 项目数 # 将项目特征矩阵放入items_features中,第0列为截距项1 # 其实就是为项目特征矩阵itemsFeaturesMatrix增加一列截距项全为1 items_features = np.ones((n_items, n_features)) items_features[:, 1:] = self.itemsFeaturesMatrix items_features = items_features.astype(float) self.ratingMatrix = self.ratingMatrix.astype(float) # 初始化用户特征矩阵,这里是需要求解的权重(在线性回归中) users_featuers = np.random.rand(n_users, n_features) users_featuers[:, 0] = 1. # 第0列是截距项,这里设置为全1 flag=True # 迭代误差求解,得到所有用户的特征 while flag: for user in range(n_users): for feature in range(n_features): if feature == 0: # 这里是截距项,不需要正则化 for item in range(n_items): if self.ratingMatrix[user, item] > 0: # 训练评过分的数据 # 预测值与真实值的差 difference = self.predict(users_featuers[user], items_features[item]) - self.ratingMatrix[user, item] users_featuers[user, feature] -= self.alpha * difference * items_features[ item, feature] # items_features[item,feature]一项代表这个项目是否有此特征,有则是1,无则是0 else: for item in range(n_items): if self.ratingMatrix[user, item] > 0: # 训练评过分的数据 difference = self.predict(users_featuers[user], items_features[item]) - self.ratingMatrix[user, item] users_featuers[user, feature] -= self.alpha * ( difference * items_features[item, feature] + self.λ * users_featuers[user, feature]) cost=0 for user in range(n_users): for item in range(n_items): if self.ratingMatrix[user,item]>0: cost+=(1/2)*math.pow(self.ratingMatrix[user,item]-self.predict(users_featuers[user],items_features[item]),2) for feature in range(1,n_features): cost+=(1/2)*math.pow(users_featuers[user,feature],2) if cost<convergence: break self.users_features = users_featuers self.items_features = items_features