现在不敢说懂了,纯给自己科普。
wordcount
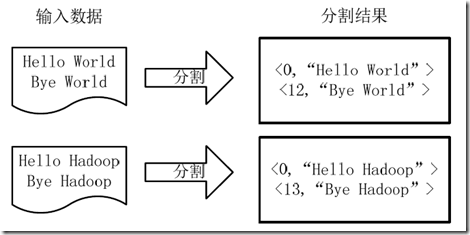
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,如图所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。
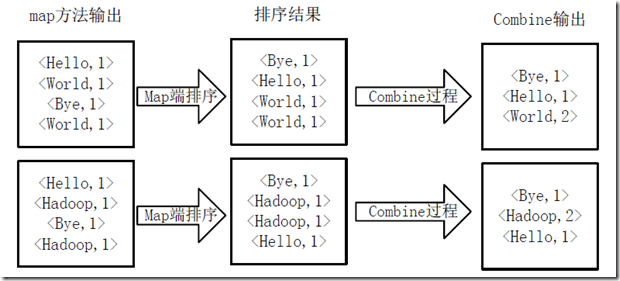
2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如图所示。

3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如图所示。
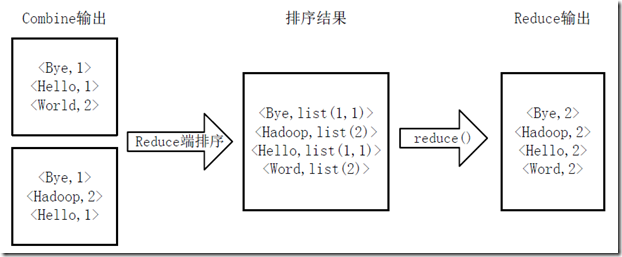
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如图所示。
转自:http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html