一、搭建Zookeeper集群
我这里用的是三台服务器,分别为第一台118.xx.xx.101,第二台 49.xx.xx.125, 第三台110.xx.xx.67
二、配置ClickHouse集群
用的也是三台服务器,分别为第一台118.xx.xx.101,第二台 49.xx.xx.125, 第三台110.xx.xx.67
1、集群配置
vi /etc/clickhouse-server/config.xml
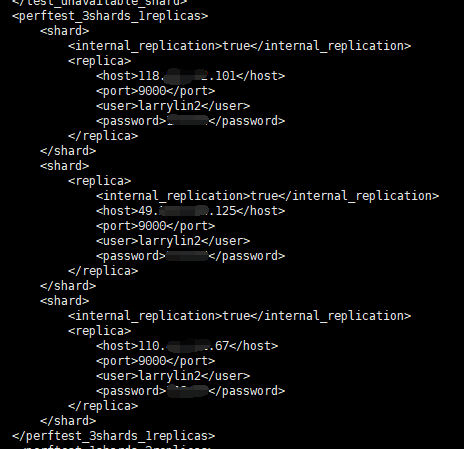
<perftest_3shards_1replicas>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>118.xx.xx.101</host>
<port>9000</port>
<user>larrylin2</user>
<password>xxxx</password>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>49.xx.xx.125</host>
<port>9000</port>
<user>larrylin2</user>
<password>xxxx</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>110.xx.xx.67</host>
<port>9000</port>
<user>larrylin2</user>
<password>xxxx</password>
</replica>
</shard>
</perftest_3shards_1replicas>
perftest_3shards_1replicas 为集群名称
2、zookeeper配置
vi /etc/clickhouse-server/config.xml

127.0.0.1是当前这台服务器。49和110是另外两台
3、配置macros
vi /etc/clickhouse-server/config.xml
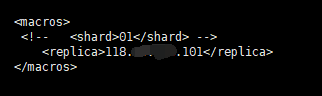
118是这台服务器的IP
三、没有副本的分布式集群
1、在第一台服务器118.xx.xx.101中
1) 在每个服务端创建一个普通表
create table tb_distribute(id UInt16, name String) ENGINE=TinyLog;
2) 在任意一个客户端创建一个分布式引擎表
create table dis_table(id UInt16, name String) ENGINE=Distributed(perftest_3shards_1replicas, db_test, tb_distribute, id);
perftest_3shards_1replicas: 集群名称
db_test: 数据库名称
tb_distribute: 普通表
id: 分片id
3)插入数据
insert into tb_distribute values(1,'zhangsan');
查询数据,可以发现tb_distribute和dis_table两张表都又这条数据

在第三台服务110.xx.xx.67中插入测试数据
insert into tb_distribute values(2,'lisi');
然后在第一台服务器118.xx.xx.101中查询,可以发现了在第三台服务110.xx.xx.67服务器中插入的数据。

在第一台服务器中增加数据,使用分布式表
insert into dis_table values(11,'宋江');
然后在第二台查询到了这条数据
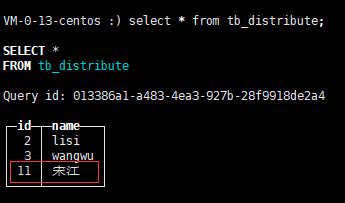
所有数据机器分布
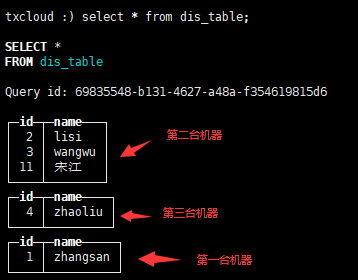
总结: 向任何一台集群的 tb_distribute中插入数据,在分布式表中dis_table 能查到。
向分布式表中dis_table中插入数据,数据会被分到某个机器的tb_distribute表中。
四、有副本的分布式集群
1、配置
vi /etc/clickhouse-server/config.xml,三台机器配置是一样的。
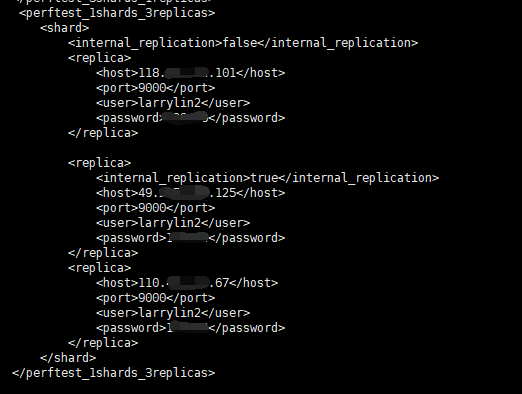
<perftest_1shards_3replicas>
<shard>
<internal_replication>false</internal_replication>
<replica>
<host>118.xx.xx.101</host>
<port>9000</port>
<user>larrylin2</user>
<password>xxxx</password>
</replica>
<replica>
<internal_replication>true</internal_replication>
<host>49.xx.xx.125</host>
<port>9000</port>
<user>larrylin2</user>
<password>xxxx</password>
</replica>
<replica>
<host>110.xx.xx.67</host>
<port>9000</port>
<user>larrylin2</user>
<password>xxxx</password>
</replica>
</shard>
</perftest_1shards_3replicas>
2、重启
三台机器分别重启,然后查看集群

3、在3台机器上分别创建普通表
create table tb_d_test(
id String,
date Date
) ENGINE = MergeTree(date,(id,date), 8192);
4、创建分布式表
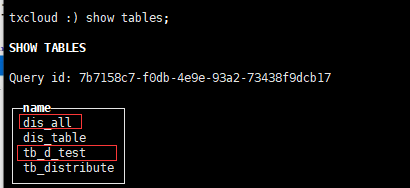
在任一机器上
create table dis_all AS tb_d_test ENGINE= Distributed(perftest_1shards_3replicas, db_test, tb_d_test, rand());
查看创建的表
5、往分布式表中插入数据
insert into dis_all values ('1','2021-07-14');
然后在三台机器上查询普通表 tb_d_test;
select * from tb_d_test;

可以发现,这三台数据都有数据。
perftest_3shards_1replicas