xml四种解析方式:
DOM 平台无关的官方解析方式
优点:形成了树结构,直观好理解,代码更易编写
解析过程中树结构保留在内存中,方便修改
缺点:当xml文件较大时,对内存耗费比较大,容易影响解析性能并造成内存溢出
SAX 基于事件驱动的解析方式
优点:采用事件驱动模式,对内存耗费比较小
适用于只需要处理xml中数据时
缺点:不易编码
DOM4J JDOM的一种智能分支,它合并了许多超出基本XML文档表示的功能
DOM4J使用接口和抽象基本类方法,是一个优秀的Java XML API
具有性能优异、灵活性好、功能强大和极端易用使用的特点
是一个开放源代码的软件
JDOM 仅使用具体类而不使用接口,API大量使用了Collections类
DOM和SAX是java提供的,不需要额外jar包
DOM4J和JDOM需要额外jar包
DOM
解析:
1、创建一个DocumentBuilderFactory对象
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
创建一个DocumentBuilder对象
2、创建一个DocumentBuilder对象
DocumentBuilder db = dbf.newDocumentBuilder();
3、通过DocumentBuilder的parse方法加载xml文件
Document document = db.parse("/Users/linjian/Documents/workspace/ImmocXml/books.xml");
生成:
1、创建TransformerFactory对象
TransformerFactory tff = new TransformerFactory();
2、创建Transformer对象
Transformer tf = ttf.newTransformer(); tf.transform(new DOMSource(document),new StreamResult(new File("book1.xml")));
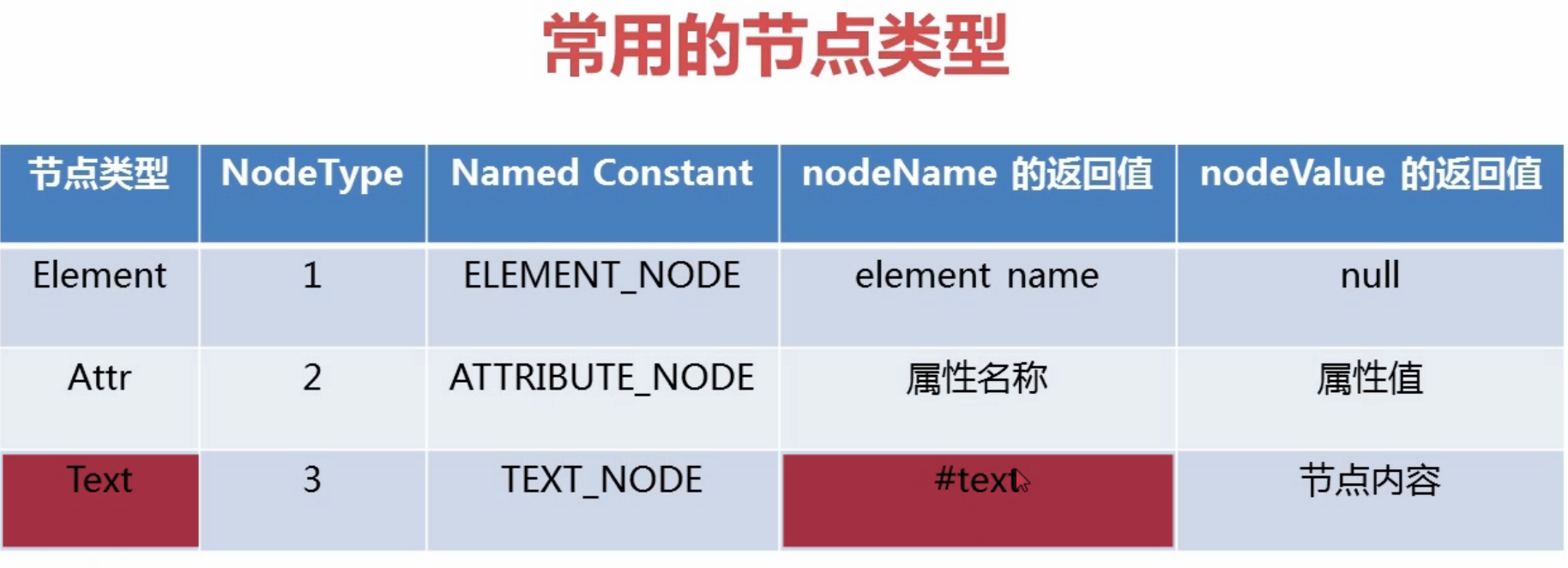
dom中父节点和字节点之间的空格属于TEXT_NODE,所以getChildNodes得到的NodeList中包含很多节点名为#text的节点,去除此类节点可以通过NodeType过滤。
节点的值是一个Text的字节点,所以获取节点值需要通过node.getFirstChild().getNodeValue()方法获取节点值;另一种方式是node.getTextContext(),但是这种方式会把字节点的值也获取到
解析book.xml
<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book id="1"> <name>冰与火之歌</name> <author>乔治马丁</author> <year>2014</year> <price>89</price> </book> <book id="2"> <name>安徒生童话</name> <year>2004</year> <price>77</price> <language>English</language> </book> </bookstore>
解析代码DomTest.java:
package com.immoc.xml; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.NamedNodeMap; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class DomTest { public static void main(String[] args) { // 创建一个DocumentBuilderFactory对象 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); try { // 创建一个DocumentBuilder对象 DocumentBuilder db = dbf.newDocumentBuilder(); try { // 通过DocumentBuilder的parse方法加载book.xml文件到当前项目下 Document document = db.parse("/Users/linjian/Documents/workspace/ImmocXml/books.xml"); // 获取book节点的集合 NodeList booklist = document.getElementsByTagName("book"); // 遍历每一个book节点,通过NodeList的getLength()方法获取booklist长度 for (int i = 0; i < booklist.getLength(); i++) { // 通过item(i)方法获取一个book节点,nodelist的索引值从0开始 System.out.println(booklist.item(i).getNodeName()); Node book = booklist.item(i); // 获取book节点的所有属性 /* NamedNodeMap attrs = book.getAttributes(); for (int j = 0; j < attrs.getLength(); j++) { System.out.println(" " + attrs.item(j).getNodeName() + ":" + attrs.item(j).getNodeValue()); } */ //获取指定属性 Element element = (Element) booklist.item(i); System.out.println(" id:"+ element.getAttribute("id")); NodeList childnNodeList = book.getChildNodes(); for (int k = 0; k < childnNodeList.getLength(); k++) { Node childNode = childnNodeList.item(k); if (childNode.getNodeType() == Node.ELEMENT_NODE) { // System.out.println(" " + childNode.getNodeName() + ":" + childNode.getTextContent()); System.out.println(" " + childNode.getNodeName() + ":" + childNode.getFirstChild().getNodeValue()); } } System.out.println(); } } catch (SAXException | IOException e) { e.printStackTrace(); } } catch (ParserConfigurationException e) { e.printStackTrace(); } } }