一.什么是Shuffle
yarn-site.xml文件配置的时候有这个参数:yarn.nodemanage.aux-services:mapreduce_shuffle
因为mapreduce程序运行在nodemanager上,nodemanager运行mapreduce程序的方式就是shuffle。
1.首先,数据在HDFS上是以数据块的形式保存,默认大小128M。
2.数据块对应成数据切片送到Mapper。默认一个数据块对应一个数据切块。
3.Mapper阶段
4.Mapper处理完,写到内存中作缓冲(环形缓冲区,默认100M)
5.内存满80%就发生溢写,进行一次IO操作,写到HDFS的文件系统上。
6.作一个处理,将小文件合成一个大文件
7.Combiner:在Mapper端先做一次Reducer,做一个合并操作
8.将Combiner的数据放到Reducer
9.输出到HDFS
图解:
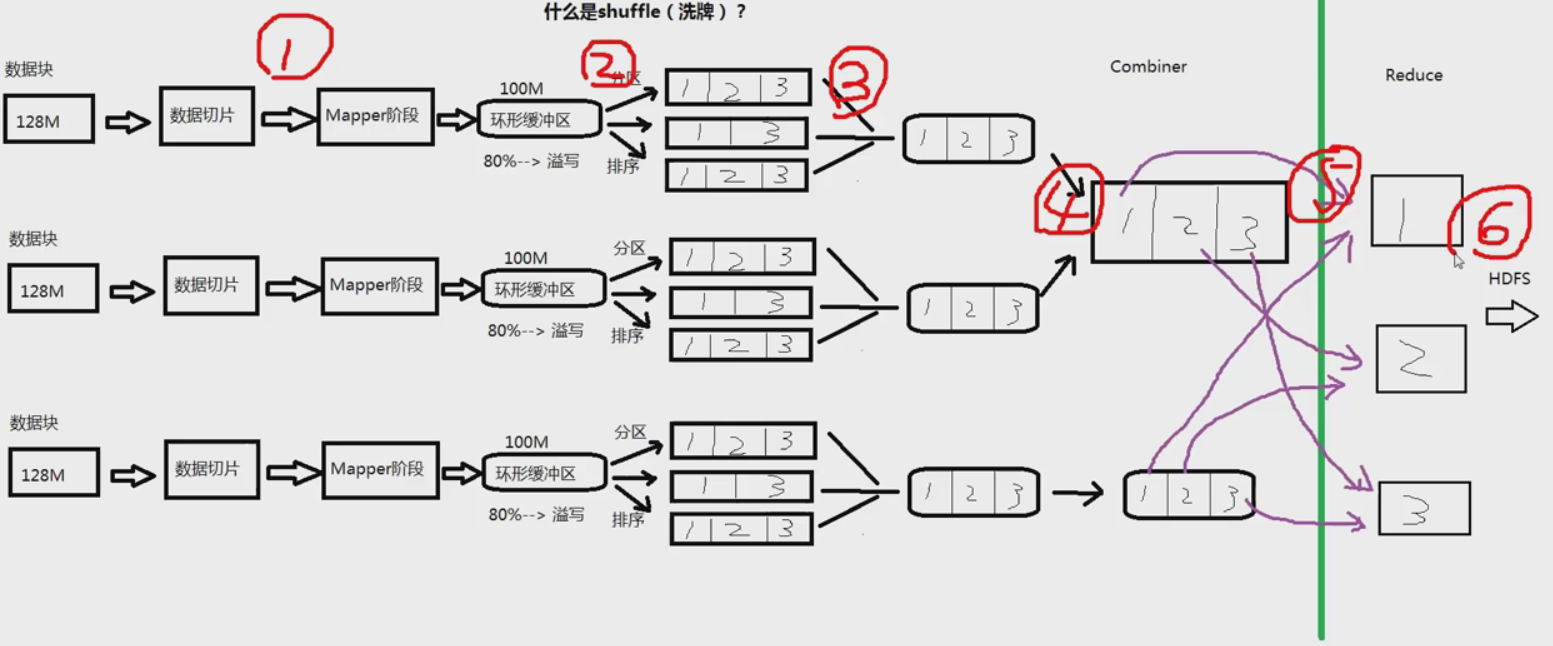
Maprecue的缺点:发生的IO次数太多(图示标号),严重影响性能。
解决方式:Spark(基于内存)
二.MapReduce编程案例
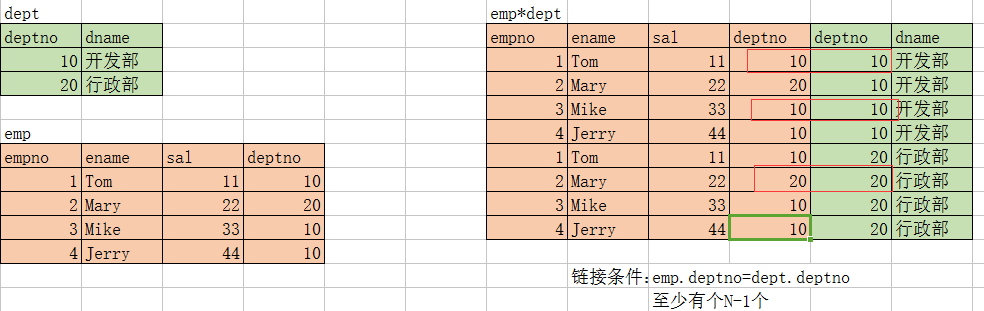
1.多表查询:等值连接
查询员工信息:部门名称、员工姓名
实现SQL语句:在emp表,dept表联合查询,查询每个部门下面的员工
select d.dname,e.ename from emp e,dept d where e.deptno=d.deptno;
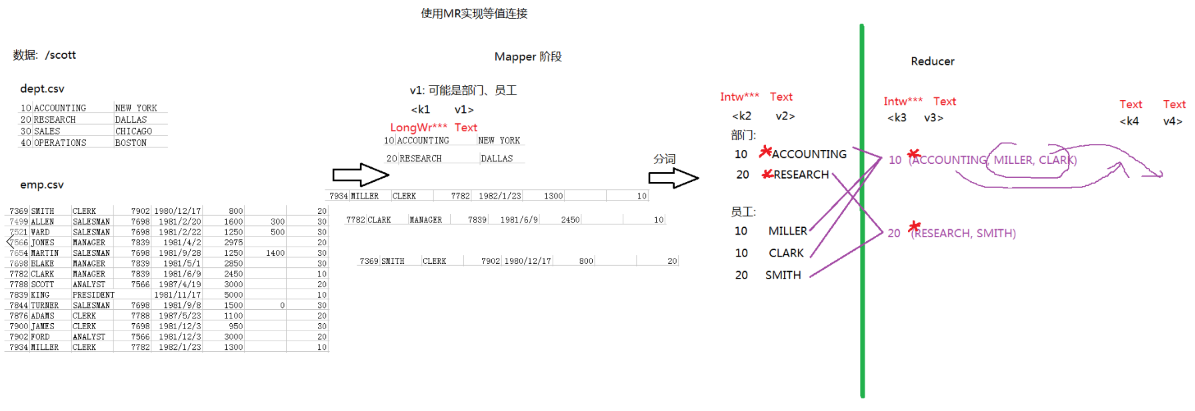
分析:
使用MR实现等值连接的分析流程:
程序:
MultiTableQueryMapper.java
package demo.multiTable; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; //k2 部门号 v2 部门名称 public class MultiTableQueryMapper extends Mapper<LongWritable, Text, LongWritable, Text> { @Override protected void map(LongWritable key1, Text value1, Context context) throws IOException, InterruptedException { //数据:可能是部门,也可能是员工 String data = value1.toString(); //分词 String[] words = data.split(","); //判断数组的长度 if (words.length == 3) { //部门表:部门号 部门名称 context.write(new LongWritable(Long.parseLong(words[0])), new Text("*"+words[1])); }else { //员工表:部门号 员工名称 context.write(new LongWritable(Long.parseLong(words[7])), new Text(words[1])); } } }
MultiTableQueryReducer.java
package demo.multiTable; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MultiTableQueryReducer extends Reducer<LongWritable, Text, Text, Text> { @Override protected void reduce(LongWritable k3, Iterable<Text> v3, Context context) throws IOException, InterruptedException { //定义变量:保存 部门名称和员工姓名 String dname = ""; String empNameList = ""; for (Text text : v3) { String string = text.toString(); //找到* 号的位置 int index = string.indexOf("*"); if (index >= 0) { //代表的是部门名称 dname = string.substring(1); }else { //代表的是员工姓名 empNameList = string + ";" + empNameList; } } //输出 部门名字 员工姓名字符串 context.write(new Text(dname), new Text(empNameList)); } }
MultiTableQueryMain.java
package demo.multiTable; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MultiTableQueryMain { public static void main(String[] args) throws Exception { Job job = Job.getInstance(new Configuration()); job.setJarByClass(MultiTableQueryMain.class); job.setMapperClass(MultiTableQueryMapper.class); job.setMapOutputKeyClass(LongWritable.class); job.setMapOutputValueClass(Text.class); job.setReducerClass(MultiTableQueryReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
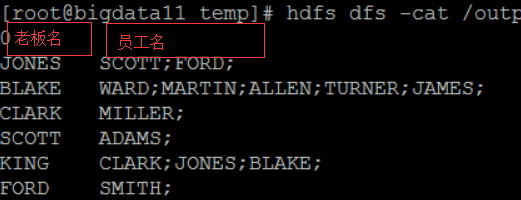
结果:

2.多表查询:自连接
自连接:通过表的别名,将同一张表看成多张表
需求:查询一个表内老板姓名和对应的员工姓名
实现SQL语句:
select b.ename,e.ename from emp b,emp e where b.empno=e.mgr;
分析:
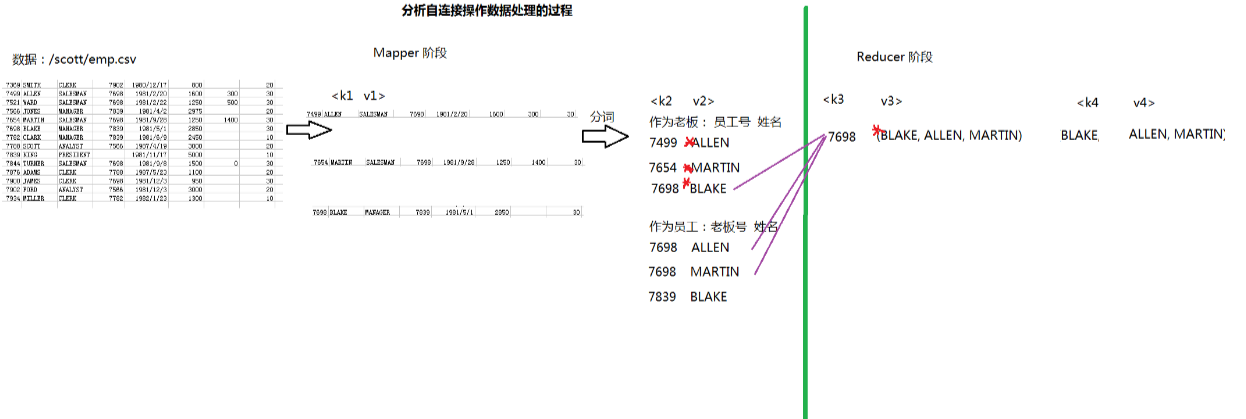
实现:
SelfJoinMapper.java
package demo.selfJoin; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class SelfJoinMapper extends Mapper<LongWritable, Text, LongWritable, Text> { @Override protected void map(LongWritable key1, Text value1, Context context) throws IOException, InterruptedException { //7698,BLAKE,MANAGER,7839,1981/5/1,2850,30 String data = value1.toString(); //分词 String[] words = data.split(","); //输出 //1.作为老板表 context.write(new LongWritable(Long.parseLong(words[0])), new Text("*"+words[1])); //2.作为员工表 try{ context.write(new LongWritable(Long.parseLong(words[3])), new Text(words[1])); }catch(Exception e){ //老板号为空值 context.write(new LongWritable(-1), new Text(words[1])); } } }
SelfJoinReducer.java
package demo.selfJoin; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class SelfJoinReducer extends Reducer<LongWritable, Text, Text, Text> { @Override protected void reduce(LongWritable k3, Iterable<Text> v3, Context context) throws IOException, InterruptedException { //定义变量:保存老板姓名 员工姓名 String bossName = ""; String empNameList = ""; for (Text text : v3) { String string = text.toString(); //判断是否存在*号 //*号的作用为了区分是哪张表 int index = string.indexOf("*"); if (index >= 0) { //老板姓名 去掉*号 bossName = string.substring(1); }else { //员工姓名 empNameList = string + ";" + empNameList; } } //输出 //如果存在老板和员工 才输出 if (bossName.length() > 0 && empNameList.length() > 0) { context.write(new Text(bossName), new Text(empNameList)); } } }
SelfJoinMain.java
package demo.selfJoin; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import demo.multiTable.MultiTableQueryMain; import demo.multiTable.MultiTableQueryMapper; import demo.multiTable.MultiTableQueryReducer; public class SelfJoinMain { public static void main(String[] args) throws Exception { Job job = Job.getInstance(new Configuration()); job.setJarByClass(SelfJoinMain.class); job.setMapperClass(SelfJoinMapper.class); job.setMapOutputKeyClass(LongWritable.class); job.setMapOutputValueClass(Text.class); job.setReducerClass(SelfJoinReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
结果: