Navigation-by-Preference: A New Conversational Recommender with Preference-Based Feedback

论文来源:ACM IUI 2020
(Intelligent User Interfaces)--人机交互
CCF分类: B类 网址:https://iui.acm.org
前言
本文提出的模型算法是基于偏好反馈的对话式推荐。给定一个种子item,推荐系统给用户推荐一个项目(即满足用户长期偏好又满足用户短期诉求)。不同于以前的工作在个性化的反馈,n-by-p不承担结构化项目描述(如套属性-值对)而是工作在非结构化的项目描述(如套关键词或标签),因此个性化反馈扩展到新的领域没有结构化的项目描述。
模型介绍
本文提出了一个新的模型,用于对话推荐系统——Navigation-by-Preference (n-by-p)。它结合了短期首选项(来自用户在对话框中提供的反馈)和长期首选项(来自用户配置文件)。
贡献:①n-by-p处理非结构化的项目描述,例如关键字或标记集。因此,本文将基于偏好的反馈扩展到结构化项目描述不可用或不太适用的领域。这些领域包括电影、音乐、艺术和新闻。②n-by-p考虑用户长期偏好以及对话系统早期的反馈。
模型:
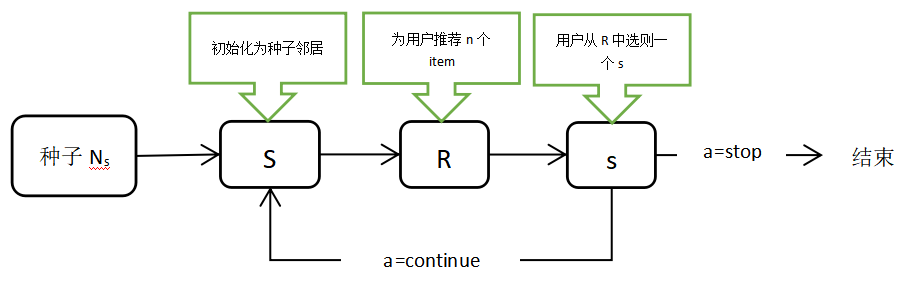
从用户配置文件中选择一个种子item,系统向用户推荐n个候选项——一系列item R。用户从R 中选择最想要的item s。一般s是最接近用户想要的item,下一轮的循环选择s作为查询项,直到用户选择到他最满意的item,或用户离开系统。
论文提出了两个版本的 n-by-p:Navigation-by-Immediate-Preference (n-by-i-p) and Navigation-by-Cumulative-Preference(n-by-c-p)。两者都利用了用户的长期偏好;但处理短期偏好的方式不同。在n-by-i-p中,只有最近周期的反馈影响下一个周期;在n-by-c-p中,我们允许早期周期的反馈也影响下一个周期。
(1)Navigation-by-Immediate-Preference (n-by-i-p)


将n个item按分数从高到底推荐给用户。item i的分数计算:score(i, S, L, R)。其中S为 selection-consistent candidates (获取短期偏好),L为用户配置文件的邻居(捕捉长期偏好),R为推荐序列。
也就是说,将候选人i插入到(部分)推荐列表R(给定S和L)的分数是短期和长期分数的线性组合:
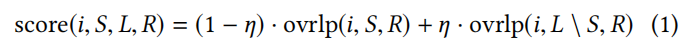
η在[0,1]控制短期和长期分数之间的平衡,我们传入L S而不是L,以确保S的成员在得分时不会被重复计算。
更新策略有五种(每一轮更新S):s为所选项目;拒收物品的集合写成R '=R\{s}。

strict:确保在下一个周期中不会推荐被拒绝的项目
relaxed:丢弃R’中每一个成员的neighbour
open:忽略R'
mean:丢弃哪些与s的相似度小于R’的item
max:丢弃与s的相似度小于与R'最大相似度的item
(2)Navigation-by-Cumulative-Preference(n-by-c-p)
每个item都有一个权重wi,wi最初为0,基于用户反馈重新更新权重。
与n-by-i-p不同的是,在更新策略选择open,也就是说没有item会被抛弃。
推荐过程与n-by-i-p基本相同,权重分数计算为:

权重更新:

共有七种策略ρ计算∆wi:

我们使用一个二进制指示符Cij,它的值指示i和j是否相关。具体来说,如果i是j的邻居候选项之一,则它们是相关的:如果i∈Nj,则Cij = 1,否则为0。
实验:
设计了一个离线实验,使用模拟用户来评估不同的n-by-p方法。 数据集:the hetrec2011-movielens-2k dataset https://grouplens.org/datasets/hetrec-2011/
该数据集包括2113名用户、5992部电影、80639个关键词和超过50万的评分。
从用户中随机选择500个用户进行实验。
为了进行用户试验,作者又构建了一个基于web的系统。在这个试验中,想要揭示使用长期偏好和短期偏好的影响,因此选择了一个η不等于0.0的系统。
结论:
根据偏好导航(n-by-p)是一个对话式推荐系统,它处理非结构化的条目描述,帮助用户构建和表达她的短期偏好,同时以最小化effort来推荐给用户最感兴趣的item。
它不要求用户清楚地说出她喜欢或不喜欢物品的哪些特征,或者她希望如何改变它们。对于用户来说,这种简单性意味着系统的模糊性:对于特性没有明确的反馈。系统给出了多个更新策略,允许我们选择如何以最适合应用程序领域的方式组合用户的偏好。