前言
Python 已延伸到 ArcGIS 中,成为了一种用于进行数据分析、数据转换、数据管理和地图自动化的语言,因而有助于提高工作效率。
脚本文件点此下载。
基本词汇
| 术语 | 说明 |
|---|---|
| Python | Python 是由 Guido van Rossum 在上世纪八十年代末构想并于 1991 年推出的一种开源编程语言。它最早集成于 ArcGIS 9.0 中,从此以后便成为用户创建地理数据库工作流的首选。 Python 得到了不断壮大的多元化用户群体的支持,具备简洁易读、语法清晰、支持动态定型等特点,并且具有大量标准库和第三方库。 |
| ArcPy | ArcPy(通常称为 ArcPy 站点包)为用户提供了使用 Python 语言操作所有地理处理工具(包括扩展模块)的接口,并提供了多种有用的函数和类,以用于处理和查询 GIS 数据。使用 Python 和 ArcPy,可以开发出大量的用于处理地理数据的实用程序。 |
| ArcPy 模块 | 模块通常是一个包含函数和类的 Python 文件。ArcPy 由一系列模块支持,包括 数据访问模块 (arcpy.da)、 制图模块 (arcpy.mapping)、 ArcGIS Spatial Analyst 扩展模块 模块 (arcpy.sa) 以及 ArcGIS Network Analyst 扩展模块 模块 (arcpy.na)。 |
| ArcPy 类 | 类的作用类似于建筑设计蓝图。蓝图为如何创建事物提供了一个框架,类可用于创建对象,即通常所说的实例。ArcPy 类,如 SpatialReference 和 Extent 类,通常用作地理处理工具参数设置的快捷方式,否则的话,这些参数会使用更加复杂的字符串。 |
| ArcPy 函数 | 函数是用于执行某项特定任务并能够纳入更大的程序的已定义功能。 在 ArcPy 中,所有地理处理工具均以函数形式提供,但并非所有函数都是地理处理工具。除工具之外,ArcPy 还提供多种函数来更好地支持 Python 地理处理工作流。函数(通常称为方法)可用于列出某些数据集、检索数据集的属性、在将表添加到地理数据库之前验证表名称,或执行其他许多有用的脚本任务。 |
| 独立的 Python 脚本 | 独立 Python 脚本是一种 .py 文件,可通过两种方式执行:通过操作系统提示符(一种 Python 集成开发环境 (IDE)),或在 Windows 资源管理器中双击 .py 文件执行。 |
| Python 脚本工具 | Python 脚本工具是已添加到地理处理工具箱的 Python 脚本。添加为脚本工具后,便可以像使用其他地理处理工具一样使用此脚本工具 - 可以从工具对话框打开和执行、可以在 Python 窗口和模型构建器中使用,也可以从其他脚本和脚本工具中调用。 |
| Python 窗口 | 通过 Python 窗口,用户可以快捷地在 ArcGIS 内部使用 Python,从而以交互方式运行地理处理工具和功能以及充分利用其他 Python 模块和库。此窗口还为您学习 Python 提供了一个入口。 Python 窗口可用于执行单行 Python 代码,并会将由此生成的消息输出到窗口。借助此窗口,您可以对语法进行试验和处理短代码,并可以在大型脚本范围之外对您的想法进行检验。 |
| Python 加载项 | Python 加载项是写入到 Python 中的自定义项,它可以插入到 ArcGIS Desktop 应用程序中以便提供补充功能以完成自定义任务,例如工具条上的工具集合。要明确 Python 加载项的开发,必须下载并使用 Python 加载项向导 来声明自定义的类型。该向导将生成加载项正常工作所必需的所有文件。单击此处从 Geoprocessing Resource Center 下载 Python 加载项向导。 |
| Python 工具箱 | Python 工具箱是完全在 Python 中创建的地理处理工具箱。Python 工具箱及其所包含工具的外观、操作和运行方式与任何以其他方式创建的工具箱和工具类似。 Python 工具箱 (.pyt) 是一个基于 ASCII 的文件,该文件定义了工具箱和一个或多个工具。 |
导入 ArcPy
导入模块有多种方式
将整个模块(somemodule)导入,格式为: import somemodule
从某个模块中导入某个函数,格式为: from somemodule import somefunction
从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
将某个模块中的全部函数导入,格式为: from somemodule import *
例子:
将整个模块(somemodule)导入,格式为: import arcpy
从某个模块中导入某个函数,格式为: from arcpy import env
从某个模块中导入多个函数,格式为: from arcpy import env, os, sys
将某个模块中的全部函数导入,格式为: from arcpy import *
对模块或模块的一部分进行标识以使脚本更具可读性,格式为:from arcpy import env as ENV
上面介绍到的导入方法可根据需要选用,建议使用第一种直接将arcpy模块导入,后面引用函数时直接为arcpy.(function)(parameter)(模块名.函数名(参数)),这种更具可读性,后面示例也采用这种方式。
通过 Python 使用函数
- 在 ArcPy 中,所有地理处理工具均以函数形式提供,但并非所有函数都是地理处理工具。
- 除工具之外,ArcPy 还提供多个函数以更好地支持使用 Python 的地理处理工作流。
- 非工具函数只能从 ArcPy 获得,而不能作为 ArcGIS 应用程序中的工具,因为它们专为 Python 工作流所设计。
- 函数的一般形式与工具类似;它接受参数(可能需要也可能不需要)并返回某些结果。
- 非工具函数的返回值可以为各种类型 - 从字符串到地理处理对象。工具函数会始终返回 Result 对象,并提供地理处理消息支持。
- 函数名采用Pascal命名法,对象的方法名采用Camel命名法
常规数据函数
CreateScratchName ()
描述
为指定的数据类型创建唯一的临时路径名称。如果未给定工作空间,则使用当前工作空间。可用于脚本运行中间数据的临时存储,使用完删除即可(或者使用环境的临时路径)。
语法
CreateScratchName ({prefix}, {suffix}, {data_type}, {workspace})
{prefix}:添加到临时名称的前缀,默认为xx
{suffix}:添加到临时名称的后缀,默认为空
{data_type}:用于创建临时名称的数据类型
{workspace}:创建临时名称的工作空间。如果未指定,则使用当前工作空间
# -*- coding: cp936 -*-
import arcpy,os
# 在环境临时文件夹下创建临时文件
scratch_name = arcpy.CreateScratchName("temp",data_type="Shapefile",workspace=arcpy.env.scratchFolder)
print scratch_name
# 在环境临时GDB下创建临时文件
scratch_name = arcpy.CreateScratchName("temp",data_type="Shapefile",workspace=arcpy.env.scratchGDB)
print scratch_name
运行结果
C:UsersAdminAppDataLocalTempscratch emp0.shp
C:UsersAdminAppDataLocalTempscratch.gdb emp0
注:因电脑用户名差异,本文所示例路径非绝对(测试环境用户名为 Admin)。
CreateUniqueName ()
描述
通过在输入名称后追加数字的方式在指定工作空间中创建唯一名称。该数字会不断增大,直到名称是唯一的为止。如果未指定工作空间,则使用当前的工作空间。
语法
CreateUniqueName (base_name, {workspace})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| base_name | 用于创建唯一名称的基本名称。 | String |
| workspace | 用于创建唯一名称的工作空间。 | String |
# -*- coding: cp936 -*-
import arcpy,os
# 在环境临时文件夹下创建唯一的临时文件名
scratch_name = arcpy.CreateUniqueName("temp.shp",arcpy.env.scratchFolder)
print scratch_name
arcpy.CreateFeatureclass_management(arcpy.env.scratchFolder,"temp.shp","POLYGON")
scratch_name = arcpy.CreateUniqueName("temp.shp",arcpy.env.scratchFolder)
print scratch_name
# 在环境临时GDB下创建唯一的临时文件名
scratch_name = arcpy.CreateUniqueName("temp",arcpy.env.scratchGDB)
print scratch_name
运行结果
C:UsersAdminAppDataLocalTempscratch emp.shp
C:UsersAdminAppDataLocalTempscratch emp0.shp
C:UsersAdminAppDataLocalTempscratch.gdb emp
注:此脚本多次运行或在环境设置的临时文件夹下存在temp.shp文件会报错,原因为要创建的要素已存在。
Exists ()
确定指定数据对象是否存在。在脚本中使用到地理处理工具时可提前验证文件是否存在,arcpy的Exists函数比Python自带的os.path.exist()更加好用,可以检验地理数据库中的数据对象是否存在。
语法
Exists (dataset)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| dataset | 检查是否存在要素类、表、数据集、图层、shapefile、工作空间或文件的名称、路径或以上二者。 | String |
返回值
布尔值
import arcpy,os
scratch_name = arcpy.CreateUniqueName("temp.shp",arcpy.env.scratchFolder)
print arcpy.Exists(scratch_name)
scratch_filename = os.path.basename(scratch_name)
arcpy.CreateFeatureclass_management(arcpy.env.scratchFolder,scratch_filename,"POLYGON")
print arcpy.Exists(scratch_name)
运行结果
False
True
TestSchemaLock()
描述
测试是否可以为要素类、表或要素数据集获取方案锁。某些工具在调用时需要添加方案锁(通俗理解为获取只读状态),如添加字段。TestSchemaLock 函数不会对输入数据真正应用方案锁,但会返回布尔值。
语法
TestSchemaLock (dataset)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| dataset | 要测试是否可应用方案锁的输入数据。 | String |
返回值
| 数据类型 | 说明 |
|---|---|
| Boolean | 返回一个布尔值,指明方案锁是否可以应用到输入数据集。 可能的布尔值有: True —方案锁可以应用到数据集。 False —无法获取数据集的方案锁。 |
# -*- coding: cp936 -*-
import arcpy,os
# 创建测试要素类
arcpy.CreateFeatureclass_management(os.getcwd(),"test.shp","POLYGON")
# 如果要素在Gis中打开会得到else的结果
if arcpy.TestSchemaLock(os.getcwd()+os.sep+"test.shp"):
print "可以获取方案锁,可为要素添加字段!"
arcpy.AddField_management(os.getcwd()+os.sep+"test.shp","TESTFIELD","TEXT")
else :
print "无法获取方案锁!!!"
# 删除用于测试的要素类
#arcpy.Delete_management(os.getcwd()+os.sep+"test.shp")
运行结果
得到如下提示和在test.shp中添加了TESTFIELD字段
可以获取方案锁,可为要素添加字段!
字段
在引用字段名和添加字段时,可以使用这两个函数:AddFieldDelimiters()和ValidateFieldName()
AddFieldDelimiters()
在字段名称中添加字段分隔符,以便在 SQL 表达式中使用。分隔符类型以工作空间来判断,不论字段是否存在。
SQL 表达式中使用的字段分隔符因所查询数据的格式而异。例如,文件地理数据库(也可以不需要)和 shapefile 使用双引号 (" "),个人地理数据库使用方括号 ([ ]),企业级地理数据库不使用字段分隔符。该函数可免去为确保与 SQL 表达式一起使用的字段分隔符的正确性而进行的推测过程。
import arcpy,os
field_name="Id"
#工作空间为文件夹
workspace=os.getcwd()
print arcpy.AddFieldDelimiters(workspace,field_name)
# 实际证明添加分割方法时,只与文件的路径和后缀有关,不论是否存在。可以自行尝试。
# 工作空间为个人地理数据库,注释掉的为创建一个个人地理数据库
#arcpy.CreatePersonalGDB_management (os.getcwd(), "test.mdb")
workspace=os.getcwd()+os.sep+"test.mdb"
print arcpy.AddFieldDelimiters(workspace,field_name)
# 工作空间为文件地理数据库,注释掉的为创建一个文件地理数据库
#arcpy.CreateFileGDB_management (os.getcwd(), "test.gdb")
workspace=os.getcwd()+os.sep+"test.gdb"
print arcpy.AddFieldDelimiters(workspace,field_name)
ValidateFieldName()
获取字符串(字段名)和工作空间路径,并基于输出地理数据库中的名称限制返回一个有效字段名。输入字符串中所有的无效字符都将替换为下划线 (_)。字段名的限制取决于所使用的特定数据库(结构化查询语言 [SQL] 或 Oracle)。
# -*- coding: cp936 -*-
import arcpy,os
## 创建测试要素类
arcpy.CreateFeatureclass_management(os.getcwd(),"test.shp","POLYGON")
## 由于字段名不规范,下面语句会报错:ERROR 000310: 字段名称不能以数字开头,可自行尝试
##arcpy.AddField_management(os.getcwd()+os.sep+"test.shp","111","TEXT")
validateFieldName=arcpy.ValidateFieldName("x-45",os.getcwd()+os.sep+"test.shp")
arcpy.AddField_management(os.getcwd()+os.sep+"test.shp",validateFieldName,"TEXT")
validateFieldName=arcpy.ValidateFieldName("111",os.getcwd()+os.sep+"test.shp")
arcpy.AddField_management(os.getcwd()+os.sep+"test.shp",validateFieldName,"TEXT")
# 删除用于测试的要素类
#arcpy.Delete_management(os.getcwd()+os.sep+"test.shp")
运行结果
"Id"
[Id]
Id
描述数据
Describe 函数返回的对象包含多个属性,如数据类型、字段、索引以及许多其他属性。该对象的属性是动态的,这意味着根据所描述的数据类型,会有不同的描述属性可供使用。
注:如果试图访问 Describe 对象不具有的属性,它会抛出错误异常或返回空值(None、0 或 -1 或空字符串)。如果对特定属性不是很确定,可以使用 Python 的 hasattr() 函数进行检查。
语法
Describe (value, {datatype})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| value | 要描述的指定数据元素或地理处理对象。 | String |
| datatype | 数据的类型。仅当存在命名冲突(例如,如果地理数据库包含同名的要素数据集 (FeatureDataset) 和要素类 (FeatureClass))时需要此项。在这种情况下,数据类型将用于确定要描述的数据集。 (默认值为 None) | String |
返回值
| 数据类型 | 说明 |
|---|---|
| Describe对象 | 返回的对象属性中包含被描述对象的详细信息。某些返回的对象属性会包含文本值或对象。 |
Describe对象属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| baseName (只读) | 文件基本名称 | String |
| catalogPath (只读) | 数据路径 | String |
| children (只读) | 子元素列表 | Describe |
| childrenExpanded (只读) | 指示子元素是否已扩展 | Boolean |
| dataElementType (只读) | 元素的元素类型 | String |
| dataType (只读) | 元素类型 | String |
| extension (只读) | 文件扩展名 | String |
| file (只读) | 文件名称 | String |
| fullPropsRetrieved (只读) | 指示是否已检索完整属性 | Boolean |
| metadataRetrieved (只读) | 指示是否已检索元数据 | Boolean |
| name (只读) | 元素的用户分配名称 | String |
| path (只读) | 文件路径 | String |
# -*- coding: cp936 -*-
import arcpy,os
if arcpy.Exists(os.getcwd()+os.sep+"test.shp") :
print "文件已存在"
else :
arcpy.CreateFeatureclass_management(os.getcwd(),"test.shp","POLYGON")
desc = arcpy.Describe(os.getcwd()+os.sep+"test.shp")
# 输出文件基本名称(不含后缀,只是文件名)
print desc.baseName
# 输出数据路径(全路径+文件名+后缀)
print desc.catalogPath
# 输出文件数据类型
print desc.dataType
# 输出文件后缀
print desc.extension
# 输出文件名称(文件名+后缀)
print desc.file
# 输出文件的路径(只是路径)
print desc.path
输出结果
test
C:UsersAdminDesktopArcgis与Python�3描述数据 est.shp
ShapeFile
shp
test.shp
C:UsersAdminDesktopArcgis与Python�3描述数据
列出数据
这些函数的参数是相似的。
一些函数,例如 ListFields,需要输入数据集值,因为函数列出的项目驻留在特定的对象或数据集中。其他函数则不需要输入数据集值,因为它们在当前工作空间中列出数据,该工作空间是在环境设置中定义的。
所有函数都具有一个通配符参数,用于限制按名称列出的对象或数据集。
ListWorkspaces()
描述
列出所设置的工作空间中的所有工作空间。可以为工作空间名称和工作空间类型指定搜索条件,从而限制所返回的列表。
语法
ListWorkspaces ({wild_card}, {workspace_type})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| wild_card | wild_card 可限制返回的结果。如果未指定任何 wild_card,则会返回所有值。 | String |
| workspace_type | 限制由通配符参数返回的结果的工作空间类型。 有六个可能的工作空间类型: Access —将仅选择个人地理数据库。 Coverage —将仅选择 coverage 工作空间。 FileGDB —将仅选择文件地理数据库。 Folder —将仅选择 shapefile 工作空间。 SDE —将仅选择企业级数据库。 All —将选择所有工作空间。这是默认设置。 (默认值为 All) |
String |
返回值
该函数将返回包含工作空间名称的列表,该列表受通配符和工作空间类型参数的限制。
import arcpy, os
# 创建多种不同类型的工作空间
arcpy.CreatePersonalGDB_management(os.getcwd(), "testListWorkspaces0.mdb")
arcpy.CreatePersonalGDB_management(os.getcwd(), "testListWorkspaces1.mdb")
arcpy.CreateFolder_management(os.getcwd(), "testListWorkspaces2")
arcpy.CreateFileGDB_management(os.getcwd(), "testListWorkspaces3.gdb")
arcpy.CreateFileGDB_management(os.getcwd(), "testListWorkspaces4.gdb")
arcpy.env.workspace = os.getcwd()
# 获取所有工作空间
workSpaces = arcpy.ListWorkspaces()
print "This is all workSpaces:"
workSpaces = arcpy.ListWorkspaces()
for workSpace in workSpaces:
print workSpace
# 获取所有GDB工作空间
print "This is all gdb:"
workSpaces = arcpy.ListWorkspaces("*", "FileGDB")
for workSpace in workSpaces:
print workSpace
# 删除创建的用于测试的工作空间
workSpaces = arcpy.ListWorkspaces()
for workSpace in workSpaces:
arcpy.Delete_management(workSpace)
运行结果
This is all workSpaces:
D:BlogArcgis与Python�4列出数据 estListWorkspaces0.mdb
D:BlogArcgis与Python�4列出数据 estListWorkspaces1.mdb
D:BlogArcgis与Python�4列出数据 estListWorkspaces2
D:BlogArcgis与Python�4列出数据 estListWorkspaces3.gdb
D:BlogArcgis与Python�4列出数据 estListWorkspaces4.gdb
This is all gdb:
D:BlogArcgis与Python�4列出数据 estListWorkspaces3.gdb
D:BlogArcgis与Python�4列出数据 estListWorkspaces4.gdb
ListFiles()
描述
根据查询字符串返回当前工作空间中的文件列表。通过指定搜索条件可以限制结果。
语法
ListFiles ({wild_card})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| wild_card | wild_card 可限制返回的结果。如果未指定任何 wild_card,则会返回所有值。 | String |
返回值
文件列表
以下代码可返回文件夹下的py文件列表
import arcpy, os
arcpy.env.workspace = os.getcwd()
for py_file in arcpy.ListFiles("*.py"):
print py_file
ListDatasets()
描述
列出工作空间中的所有数据集。可针对数据集名称和数据集类型指定搜索条件,从而限制返回的列表。
语法
ListDatasets ({wild_card}, {feature_type})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| wild_card | wild_card 可限制返回的结果。如果未指定任何 wild_card,则会返回所有值。 | String |
| feature_type | 限制由通配符参数返回的结果的要素类型。有效数据集类型为: Coverage —仅 coverage。 Feature —coverage 或地理数据库数据集(取决于工作空间)。 GeometricNetwork —仅几何网络数据集。 Mosaic —仅镶嵌数据集。 Network —仅网络数据集。 ParcelFabric —仅宗地结构数据集。 Raster —仅栅格数据集。 RasterCatalog —仅栅格目录数据集。 Schematic —仅逻辑示意图数据集。 Terrain —仅 terrain 数据集。 Tin —仅 TIN 数据集。 Topology —仅拓扑数据集。 All —工作空间中的所有数据集。这是默认值。 (默认值为 All) |
String |
返回值
返回包含数据集名称的列表,该列表受通配符和要素类型参数限制。
import arcpy,os
# 创建个人地理数据库
arcpy.CreatePersonalGDB_management (os.getcwd(), "test.mdb")
# 创建MyFeatureDataset1、MyFeatureDataset2、FeatureDataset3要素数据集
arcpy.CreateFeatureDataset_management (os.getcwd()+os.sep+"test.mdb", "MyFeatureDataset1")
arcpy.CreateFeatureDataset_management (os.getcwd()+os.sep+"test.mdb", "MyFeatureDataset2")
arcpy.CreateFeatureDataset_management (os.getcwd()+os.sep+"test.mdb", "FeatureDataset3")
# 在MyFeatureDataset1要素数据集中创建拓扑
arcpy.CreateTopology_management (os.getcwd()+os.sep+"test.mdb"+os.sep+"MyFeatureDataset1", "MyTopology")
# 列举创建的个人地理数据库中的要素数据集
arcpy.env.workspace = os.getcwd()+os.sep+"test.mdb"
datasets = arcpy.ListDatasets("","Feature")
for dataset in datasets :
print(dataset)
print("")
# 列举创建的个人地理数据库中的要素数据集(使用通配符,只列举以My开头的)
datasets = arcpy.ListDatasets("My*","Feature")
for dataset in datasets :
print(dataset)
print("")
# 列举MyFeatureDataset1要素数据集中的拓扑
arcpy.env.workspace = os.getcwd()+os.sep+"test.mdb"+os.sep+"MyFeatureDataset1"
datasets = arcpy.ListDatasets("","Topology")
for dataset in datasets :
print(dataset)
arcpy.Delete_management(os.getcwd()+os.sep+"test.mdb")
运行结果
MyFeatureDataset1
MyFeatureDataset2
FeatureDataset3
MyFeatureDataset1
MyFeatureDataset2
MyTopology
ListFeatureClasses()
描述
列出工作空间中的要素类,受名称、要素类型和可选要素数据集的限制。
语法
ListFeatureClasses ({wild_card}, {feature_type}, {feature_dataset})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| wild_card | wild_card 可限制返回的结果。如果未指定任何 wild_card,则会返回所有值。 | String |
| feature_type | 限制由 wild_card 参数返回的结果的要素类型。有效要素类型为: Annotation —仅返回注记要素类。 Arc —仅返回弧(或线)要素类。 Dimension —仅返回尺寸要素类。 Edge —仅返回边要素类。 Junction —仅返回交汇点要素类。 Label — 仅返回标注要素类。 Line —仅返回线(或弧)要素类。 Multipatch —仅返回多面体要素类。 Node —仅返回节点要素类。 Point —仅返回点要素类。 Polygon —仅返回面要素类。 Polyline —仅返回线(或弧)要素类。 Region —仅返回区域要素类。 Route —仅返回路径要素类。 Tic —仅返回控制点要素类。 All — 工作空间中的所有数据集。这是默认值。 (默认值为 All) |
String |
| feature_dataset | 若已指定,则限制返回到要素数据集的要素类。若留空,则在工作空间中将仅返回独立要素类。 | String |
返回值
返回包含要素类名称的列表,该列表受可选的 wild_card、feature_type 和 feature_dataset
参数的限制。
import arcpy,os
# 创建个人地理数据库
arcpy.CreatePersonalGDB_management (os.getcwd(), "test.mdb")
# 创建MyFeatureclass1、Featureclass2、Featureclass3要素数据集
arcpy.CreateFeatureclass_management (os.getcwd()+os.sep+"test.mdb", "MyFeatureclass1","POLYGON")
arcpy.CreateFeatureclass_management (os.getcwd()+os.sep+"test.mdb", "Featureclass2","POLYGON")
arcpy.CreateFeatureclass_management (os.getcwd()+os.sep+"test.mdb", "Featureclass3","POINT")
# 列举创建的个人地理数据库中的要素类
arcpy.env.workspace = os.getcwd()+os.sep+"test.mdb"
fcs = arcpy.ListFeatureClasses()
print("All Featureclasses :")
for fc in fcs :
print(fc)
# 列举创建的个人地理数据库中的要素类(使用通配符,只列举以My开头,要素类型为面的)
fcs = arcpy.ListFeatureClasses("My*","Polygon")
print("Starts with My and Polygon :")
for fc in fcs :
print(fc)
# 列举创建的个人地理数据库中的点要素类
fcs = arcpy.ListFeatureClasses("","Point")
print("Point Featureclasses :")
for fc in fcs :
print(fc)
arcpy.Delete_management(os.getcwd()+os.sep+"test.mdb")
运行结果
All Featureclasses :
MyFeatureclass1
Featureclass2
Featureclass3
Starts with My and Polygon :
MyFeatureclass1
Point Featureclasses :
Featureclass3
ListRasters()
描述
按名称和栅格类型返回工作空间中的栅格列表。
语法
ListRasters ({wild_card}, {raster_type})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| wild_card | wild_card 可限制返回的结果。如果未指定任何 wild_card,则会返回所有值。 | String |
| raster_type | 限制由通配符参数返回的结果的栅格类型。有效栅格类型为: BMP —位图图形栅格数据集格式。 GIF —栅格数据集的图形交换格式。 IMG — ERDAS IMAGINE 栅格数据格式 JP2 —JPEG 2000 栅格数据集格式。 JPG —联合图像专家组栅格数据集格式。 PNG — 可移植网络图形栅格数据集格式。 TIF —栅格数据集的标记图像文件。 GRID — 格网数据格式。 All —返回所有支持的栅格类型。这是默认设置。 (默认值为 All) |
String |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 该函数返回的列表包含受可选通配符和栅格类型限制的工作空间中的栅格名称。 |
ListTables()
描述
按名称和表类型列出工作空间中的表。
语法
ListTables ({wild_card}, {table_type})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| wild_card | wild_card 可限制返回的结果。如果未指定任何 wild_card,则会返回所有值。 | String |
| table_type | 限制由通配符参数返回的结果的表类型。有效表类型为: dBASE —仅返回 dBASE 类型的表。 INFO —仅返回独立 INFO 表。 ALL —返回所有独立表(包括地理数据库表)。 这是默认设置。 (默认值为 All) |
String |
返回值
该函数返回的列表包含受可选通配符和表类型限制的工作空间中的表名称。
import arcpy, os
for i in range(5):
arcpy.CreateTable_management(os.getcwd(), "a" + str(i))
arcpy.CreateTable_management(os.getcwd(), "b" + str(i) + ".dbf")
arcpy.env.workspace = os.getcwd()
print "These are all tables:"
# 获取所有表
for table in arcpy.ListTables():
print table
print "These are all dbfTables:"
# 获取所有dbf表
for table in arcpy.ListTables("", "dBASE"):
print table
# 删除用于测试创建的表
for table in arcpy.ListTables():
arcpy.Delete_management(os.getcwd() + os.sep + table)
运行结果
These are all tables:
a0
a1
a2
a3
a4
b0.dbf
b1.dbf
b2.dbf
b3.dbf
b4.dbf
These are all dbfTables:
b0.dbf
b1.dbf
b2.dbf
b3.dbf
b4.dbf
ListFields()
描述
列出指定数据集中的要素类、shapefile 或表中的字段。返回的列表可用针对名称和字段类型的搜索条件进行限制,并将包含字段对象。
语法
ListFields (dataset, {wild_card}, {field_type})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| dataset | 指定的要素类或表(其字段将被返回)。 | String |
| wild_card | wild_card 可限制返回的结果。如果未指定任何 wild_card,则会返回所有值。 (默认值为 None) | String |
| field_type | 要返回的指定字段类型。有效字段类型为: All — 返回所有字段类型。这是默认设置。 BLOB —仅返回 BLOB 字段类型。 Date —仅返回日期字段类型。 Double —仅返回双精度字段类型。 Geometry —仅返回几何字段类型。 GlobalID —仅返回 GlobalID 字段类型。 GUID —仅返回 GUID 字段类型。 Integer —仅返回整型字段类型。 OID —仅返回 OID 字段类型。 Raster —仅返回栅格字段类型。 Single —仅返回单精度字段类型。 SmallInteger —仅返回短整型字段类型。 String —仅返回字符串字段类型。 (默认值为 All) |
String |
返回值
返回包含字段对象的列表。
以下代码可获取字段信息并存入CSV文件中
# -*- coding: cp936 -*-
import arcpy, os, csv
arcpy.CreateFeatureclass_management(os.getcwd(), "testListFields.shp")
in_fc = os.getcwd() + os.sep + "testListFields.shp"
# 创建不同类型的字段
arcpy.AddField_management(in_fc, "Short_T", "SHORT")
arcpy.AddField_management(in_fc, "Long_T", "LONG")
arcpy.AddField_management(in_fc, "Float_T", "FLOAT", "7", "4")
arcpy.AddField_management(in_fc, "Double_T", "DOUBLE", "18", "4")
arcpy.AddField_management(in_fc, "Text_T", "TEXT", "", "", 100)
out_csv = os.getcwd() + os.sep + "a.csv"
header = ["字段名", "类型", "长度", "精度", "小数位数"]
rows = []
try:
for field in arcpy.ListFields(in_fc):
row = [field.name, field.type, field.length, field.precision, field.scale]
# 因列举字段信息获取到的字段类型和创建字段的字段类型并不一致,存在映射关系
# 在此判断并转换后获得到的信息可以直接用于创建字段
if row[1] == "Integer":
row[1] = "LONG"
elif row[1] == "SmallInteger":
row[1] = "SHORT"
print row
rows.append(row)
with open(out_csv, "wb") as f:
f_csv = csv.writer(f)
f_csv.writerow(header)
f_csv.writerows(rows)
except arcpy.ExecuteError:
print arcpy.GetMessages()
# arcpy.Delete_management(in_fc)
# arcpy.Delete_management(out_csv)
运行结果
会在脚本目录创建testListFields.shp的要素类,并产生一个a.csv文件,存储了testListFields.shp字段信息
[u'FID', u'OID', 4, 0, 0]
[u'Shape', u'Geometry', 0, 0, 0]
[u'Id', 'LONG', 6, 6, 0]
[u'Short_T', 'LONG', 5, 5, 0]
[u'Long_T', 'LONG', 10, 10, 0]
[u'Float_T', u'Single', 8, 7, 4]
[u'Double_T', u'Double', 19, 18, 4]
[u'Text_T', u'String', 100, 0, 0]
根据获取的字段信息CSV批量创建字段代码
import arcpy, os
arcpy.CreateFeatureclass_management(os.getcwd(), "testAddFields.shp")
in_fc = os.getcwd() + os.sep + "testAddFields.shp"
in_field_csv = os.getcwd() + os.sep + "a.csv"
try:
with open(in_field_csv) as f:
f.readline()
lines = f.readlines()
for line in lines:
field = line.rstrip("
").split(",")
print field
# 根据创建的字段的类型不同,对应提供创建字段的不同参数
if field[1].upper() == "SINGLE" or field[1].upper() == "FLOAT" or field[1].upper() == "DOUBLE":
arcpy.AddField_management(in_fc, field[0], field[1], field[3], field[4])
elif field[1].upper() == "SHORT" or field[1].upper() == "LONG":
arcpy.AddField_management(in_fc, field[0], field[1], field[2])
elif field[1].upper() == "STRING" or field[1].upper() == "TEXT":
arcpy.AddField_management(in_fc, field[0], field[1], "", "", field[2])
elif field[1].upper() == "OID" or field[1].upper() == "GEOMETRY":
pass
else:
arcpy.AddField_management(in_fc, field[0], field[1])
except arcpy.ExecuteError:
arcpy.GetMessages()
消息和错误处理
GetMessages ()
在工具执行期间,系统会写入可通过地理处理函数 GetMessages 进行检索的消息。这些消息包含如下信息:
- 操作的开始及结束时间
- 所使用的参数值
- 有关操作进度的常规信息(信息性消息)
- 潜在问题的警告(警告消息)
- 导致工具停止执行的错误(错误消息)
描述
按指定的严重性级别从工具返回地理处理消息。
语法
GetMessages ({severity})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| severity | 指定要返回的消息的严重性级别。 0 —消息已返回。 1 —警告消息已返回。 2 —错误消息已返回。 如果未指定严重性级别,将返回所有类型的消息。 (默认值为 0) |
Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 多个地理处理工具消息由换行符 (' ') 分隔。 |
GetMessageCount ()
返回从上次执行命令到现在为止返回的所有消息计数。
GetMessage (index)
按地理处理工具消息的索引位置返回该消息。
GetIDMessage (message_ID)
获取错误或警告 ID 消息的字符串。GetIDMessage 允许您访问 Python 中使用的地理处理工具消息代码。这些地理处理工具消息代码可在帮助中查询到(基础工具——工具错误和警告)。
GetSeverity (index)
描述
按索引获取指定消息的严重性代码(0、1 和 2)。
语法
GetSeverity (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 堆栈中消息的数值索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| Integer | 消息的严重性代码: 0 —消息 1 —警告 2 —错误 |
SetSeverityLevel (severity_level)
描述
用于控制地理处理工具如何抛出异常。如果未使用 SetSeverityLevel,默认行为等效于将 severity_level 设置为 2;即,仅当工具出错时,才会抛出异常。
语法
SetSeverityLevel (severity_level)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| severity_level | The severity level 0 —即使工具生成错误或警告,也不会抛出异常。 1 —如果工具生成警告或错误,将抛出异常。 2 —如果工具生成错误,将抛出异常。这是默认设置。 |
Integer |
GetSeverityLevel ()
返回严重性级别。严重性级别用于控制地理处理工具抛出异常的方式。
GetMaxSeverity ()
获取从上次执行工具以来返回的最大严重性。
GetReturnCode (index)
描述
通过索引返回消息错误代码。
如果指定索引的消息是警告或信息性消息,函数将返回 0;如果消息是错误,函数将返回 0 以外的值。
语法
GetReturnCode (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 消息、警告或错误返回列表中消息的指定位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| Integer | 指定索引位置的消息的返回代码。 |
测试代码
arcpy, os
arcpy.CreateFeatureclass_management(os.getcwd(), "testMessage.shp")
fc = os.getcwd() + os.sep + "testMessage.shp"
try:
arcpy.AddField_management(fc, "TEST", "TEXT")
arcpy.AddField_management(fc, "TEST", "TEXT")
except arcpy.ExecuteError:
pass
print "Test GetMessageCount:"
messageCount = arcpy.GetMessageCount()
print messageCount
print "Test GetMessages:"
print arcpy.GetMessages()
print "Test GetMessage:"
print "GetMessage(0):",arcpy.GetMessage(0)
print "GetMessage(1):",arcpy.GetMessage(1)
print "GetMessage(2):",arcpy.GetMessage(2)
print "Test GetIDMessage:"
print "GetIDMessage(84001):",arcpy.GetIDMessage(84001)
print "GetIDMessage(999999):",arcpy.GetIDMessage(999999)
print "Test GetReturnCode:"
print "Message[1]'s ReturnCode:", arcpy.GetReturnCode(1)
print "Message[2]'s ReturnCode:", arcpy.GetReturnCode(2)
print "Test GetSeverity:"
print "Message[1]'s Severity:", arcpy.GetSeverity(1)
print "Message[2]'s Severity:", arcpy.GetSeverity(2)
print "Test GetSeverityLevel:"
print arcpy.GetSeverityLevel()
arcpy.SetSeverityLevel(1)
print arcpy.GetSeverityLevel()
print "Test GetMaxSeverity:"
print arcpy.GetMaxSeverity()
arcpy.Delete_management(fc)
运行结果
Test GetMessageCount:
4
Test GetMessages:
执行: AddField E:CodeStudy estMessage.shp TEST TEXT # # # # NULLABLE NON_REQUIRED #
开始时间: Mon Jan 27 23:12:05 2020
WARNING 000012: TEST 已存在
成功 在 Mon Jan 27 23:12:05 2020 (经历的时间: 0.00 秒)
Test GetMessage:
GetMessage(0): 执行: AddField E:CodeStudy estMessage.shp TEST TEXT # # # # NULLABLE NON_REQUIRED #
GetMessage(1): 开始时间: Mon Jan 27 23:12:05 2020
GetMessage(2): WARNING 000012: TEST 已存在
Test GetIDMessage:
GetIDMessage(84001): 正在读取数据...
GetIDMessage(999999): 执行函数时出错。
Test GetReturnCode:
Message[1]'s ReturnCode: 0
Message[2]'s ReturnCode: 0
Test GetSeverity:
Message[1]'s Severity: 0
Message[2]'s Severity: 1
Test GetSeverityLevel:
2
1
Test GetMaxSeverity:
1
AddMessage (message)
描述
向脚本工具或 Python 工具箱工具的消息中添加自定义信息性消息(严重性为 0)。
运行工具时,arcpy 完全知晓调用该工具的应用程序。其中一个主要作用是您可以在 Python 中写入消息,且您的消息会自动出现在工具对话框、历史记录和 Python 窗口中。
语法
AddMessage (message)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| message | 要添加的消息。 | String |
AddWarning (message)
描述
向脚本工具或 Python 工具箱工具的消息中添加自定义警告消息(严重性为 1)。
运行工具时,arcpy 完全知晓调用该工具的应用程序。其中一个主要作用是您可以在 Python 中写入消息,且您的消息会自动出现在工具对话框、历史记录和 Python 窗口中。
语法
AddWarning (message)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| message | 要添加的警告消息。 | String |
AddError (message)
描述
向脚本工具或 Python 工具箱工具的消息中添加自定义错误消息(严重性为 2)。
运行工具时,arcpy 完全知晓调用该工具的应用程序。其中一个主要作用是您可以在 Python 中写入消息,且您的消息会自动出现在工具对话框、历史记录和 Python 窗口中。
语法
AddError (message)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| message | 要添加的错误消息。 | String |
AddIDMessage ()
描述
可以通过脚本工具使用系统消息。这些地理处理工具消息代码可在帮助中查询到(基础工具——工具错误和警告)。
说明
-
地理处理过程中错误和警告信息由地理处理工具返回,形式为一个六位数代码和一条文本消息。
-
每个错误和警告在桌面帮助系统中都有对应的描述页面。该页面包含详细的错误描述以及针对该错误的可行解决方案。
-
工具对话框、Python 窗口以及结果窗口中的 ID 代码是一个链接,用户单击该链接后会进入描述页面。
语法
AddIDMessage (message_type, message_ID, {add_argument1}, {add_argument2})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| message_type | 消息类型定义消息为错误消息、警告消息还是信息性消息。有效消息类型如下: ERROR —向工具消息添加错误消息 INFORMATIVE —向工具消息添加信息性消息 WARNING —向工具消息添加警告消息 |
String |
| message_ID | 消息 ID 允许您参考脚本错误和警告的现有消息。 | Integer |
| add_argument1 | 根据所使用的消息 ID,可能需要使用参数来完成消息。常见的示例包括数据集或字段名称。数据类型可以是字符串类型、整型或双精度型。 | Object |
| add_argument2 | 根据所使用的消息 ID,可能需要使用参数来完成消息。常见的示例包括数据集或字段名称。数据类型可以是字符串类型、整型或双精度型。 | Object |
AddReturnMessage ()
描述
按索引将脚本工具的返回消息设置为输出消息。
说明
有时您可能想要返回所调用的工具的所有消息,而不考虑消息的严重性。通过索引参数,AddReturnMessage 将返回执行上一个工具时生成的消息。消息的严重性(警告和错误等)将会保留。
进度对话框中显示的地理处理错误编号为指向用于进一步说明错误的帮助页面的超链接。要启用脚本中的错误的超链接,请使用 AddReturnMessage 函数,而不是 AddError 函数。
语法
AddReturnMessage (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 消息索引。 | Integer |
代码
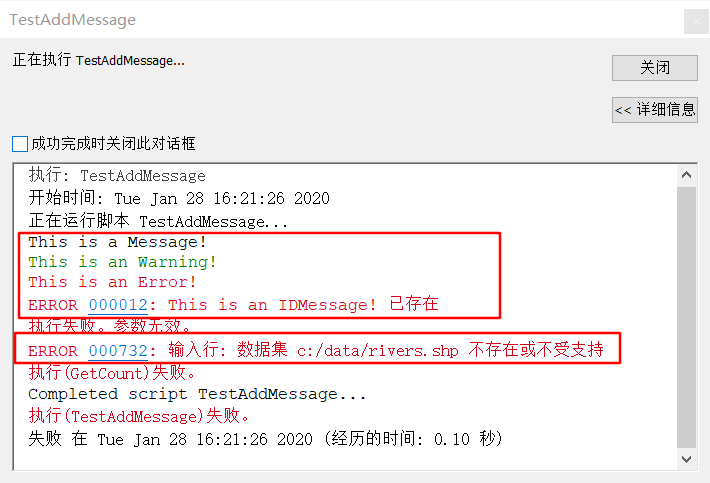
import arcpy
arcpy.AddMessage("This is a Message!")
arcpy.AddWarning("This is an Warning!")
arcpy.AddError("This is an Error!")
arcpy.AddIDMessage("ERROR", 12, "This is an IDMessage!")
try:
result = arcpy.GetCount_management("c:/data/rivers.shp")
except:
# Return Geoprocessing tool specific errors
#
for msg in range(0, arcpy.GetMessageCount()):
if arcpy.GetSeverity(msg) == 2:
arcpy.AddReturnMessage(msg)
将脚本设置为脚本工具消息框显示结果
执行: TestAddMessage
开始时间: Tue Jan 28 16:21:26 2020
正在运行脚本 TestAddMessage...
This is a Message!
This is an Warning!
This is an Error!
ERROR 000012: This is an IDMessage! 已存在
执行失败。参数无效。
ERROR 000732: 输入行: 数据集 c:/data/rivers.shp 不存在或不受支持
执行(GetCount)失败。
Completed script TestAddMessage...
执行(TestAddMessage)失败。
失败 在 Tue Jan 28 16:21:26 2020 (经历的时间: 0.10 秒)
获取和设置参数
GetParameterCount(tool_name)
描述
返回指定工具的参数值计数。如果此工具包含在自定义工具箱中,请使用 ImportToolbox 访问此自定义工具。
语法
GetParameterCount (tool_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| tool_name | 参数数量将返回的工具名称。 | String |
返回值
| 数据类型 | 说明 |
|---|---|
| Integer | 指定工具的参数数量。 |
GetParameterInfo(tool_name)
描述
返回给定工具的参数对象列表,并且通常用在脚本工具的 ToolValidator 类中。
语法
GetParameterInfo (tool_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| tool_name | 工具名称。在其中包括工具箱别名有助于解决重复工具名称之间的任何冲突。 注: GetParameterInfo 函数用作脚本工具 ToolValidator 类的一部分时,tool_name 参数为可选。 |
String |
返回值
| 数据类型 | 说明 |
|---|---|
| Parameter | 返回参数对象列表。 |
GetParameterValue(tool_name, index)
描述
为指定工具名称返回所需参数的默认值。
语法
GetParameterValue (tool_name, index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| tool_name | 参数默认值将返回的工具名称。 | String |
| index | 指定工具参数列表中参数的索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 返回工具的指定参数的默认值(无默认值则为空)。 |
代码示例
显示指定工具的某些参数对象属性。
import arcpy
print(arcpy.GetParameterCount("Buffer_analysis"))
params = arcpy.GetParameterInfo("Buffer_analysis")
i = 0
for param in params:
print("Name: {}, Type: {}, Value: {}".format(
param.name, param.parameterType, param.value))
print(arcpy.GetParameterValue("Buffer_analysis", i))
i = i + 1
运行结果
8
Name: in_features, Type: Required, Value: None
Name: out_feature_class, Type: Required, Value: None
Name: buffer_distance_or_field, Type: Required, Value: None
Name: line_side, Type: Optional, Value: FULL
FULL
Name: line_end_type, Type: Optional, Value: ROUND
ROUND
Name: dissolve_option, Type: Optional, Value: NONE
NONE
Name: dissolve_field, Type: Optional, Value: None
Name: method, Type: Optional, Value: PLANAR
PLANAR
GetParameterAsText(index)
描述
按照参数在参数列表中的索引位置以文本字符串的形式获取指定参数。
说明
无论参数的数据类型是什么,所有值都将作为字符串返回;要将参数用作 ArcPy 或 Python 对象,请参阅 GetParameter。
语法
GetParameterAsText (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 参数列表中参数的数值位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 以字符串形式返回的指定参数值。 |
GetParameter(index)
描述
在参数列表中,按所需参数的索引值选择参数。参数以对象的形式返回。
说明
要将此参数用作文本字符串,请参阅 GetParameterAsText。
语法
GetParameter (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 在参数列表中按索引选择指定参数。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| Object | 对象通过指定参数返回。 |
GetArgumentCount()
描述
返回传递至脚本的参数数量。
语法
GetArgumentCount ()
返回值
| 数据类型 | 说明 |
|---|---|
| Integer | 传递至脚本的参数数量(可选参数未设置脚本工具仍会自动传入#)。 |
示例代码
import arcpy
# Get the spatial reference from the tool dialog.
txt_param = arcpy.GetParameterAsText(1)
spatial_ref = arcpy.GetParameter(0)
option_param = arcpy.GetParameterAsText(2)
# Display ArgumentCount
arcpy.AddMessage("ArgumentCount is: {0}".format(arcpy.GetArgumentCount()))
# Display txt_param
arcpy.AddMessage("txt_param is: {0}".format(txt_param))
# Display the Spatial Reference properties
arcpy.AddMessage("Name is: {0}".format(spatial_ref.name))
arcpy.AddMessage("Type is: {0}".format(spatial_ref.type))
arcpy.AddMessage("Factory code is: {0}".format(spatial_ref.factoryCode))
使用上述代码创建脚本工具后对话框显示内容
注:脚本工具输入参数依次为:
| 显示名称 | 数据类型 | 可选类型 |
|---|---|---|
| 输入空间参考对象 | 空间参考 | 必选 |
| 输入字符串 | 字符串 | 必选 |
| 可选参数 | 字符串 | 可选 |
对话框显示内容
执行: TestGetParameter "PROJCS['CGCS2000_3_Degree_GK_CM_102E',GEOGCS['GCS_China_Geodetic_Coordinate_System_2000',DATUM['D_China_2000',SPHEROID['CGCS2000',6378137.0,298.257222101]],PRIMEM['Greenwich',0.0],UNIT['Degree',0.0174532925199433]],PROJECTION['Gauss_Kruger'],PARAMETER['False_Easting',500000.0],PARAMETER['False_Northing',0.0],PARAMETER['Central_Meridian',102.0],PARAMETER['Scale_Factor',1.0],PARAMETER['Latitude_Of_Origin',0.0],UNIT['Meter',1.0]];-5123200 -10002100 10000;-100000 10000;-100000 10000;0.001;0.001;0.001;IsHighPrecision" bighead #
开始时间: Mon Feb 10 12:40:14 2020
正在运行脚本 TestGetParameter...
ArgumentCount is: 3
txt_param is: bighead
Name is: CGCS2000_3_Degree_GK_CM_102E
Type is: Projected
Factory code is: 4543
Completed script TestGetParameter...
成功 在 Mon Feb 10 12:40:14 2020 (经历的时间: 0.01 秒)
以下代码可返回自定义工具参数
import arcpy
arcpy.ImportToolbox(r"C:UsersAdminDesktopGetParameterGetParameter.tbx")
print(arcpy.GetParameterCount("TestGetParameter"))
params = arcpy.GetParameterInfo("TestGetParameter")
i = 0
for param in params:
print("Name: {}, Type: {}, Value: {}".format(
param.name.encode('gb2312'), param.parameterType, param.value))
print(arcpy.GetParameterValue("TestGetParameter", i))
i = i + 1
运行结果
3
Name: 输入空间参考对象, Type: Required, Value: None
<geoprocessing spatial reference object object at 0x127C3C50>
Name: 输入字符串, Type: Required, Value: None
Name: 可选参数, Type: Optional, Value: None
进度对话框
SetProgressor ()
描述
建立一个进度条对象将进度信息传递至进度对话框。可通过选择默认进度条或步长进度条来控制进度对话框的外观。
说明
由于脚本工具共享了应用程序,因此您可以控制进度对话框。您可以通过选择默认进度条或步骤进度条来控制进度对话框的外观。
语法
SetProgressor (type, {message}, {min_range}, {max_range}, {step_value})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| type | 进度条类型(默认或步骤)。 default —进度条连续向后或向前移动。 step —进度条显示完成百分比。 (默认值为 default) |
String |
| message | 进度条标注。默认情况下没有标注。 | String |
| min_range | 进度条的开始值。默认值为 0。 (默认值为 0) | Integer |
| max_range | 进度条的结束值。默认值为 100。 (默认值为 100) | Integer |
| step_value | 用于更新进度条的进度条步长间隔。 (默认值为 1) | Integer |
SetProgressorLabel ()
描述
更新进度条对话框标签。
语法
SetProgressorLabel (label)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| label | 将用于进度条对话框的标签。 | String |
SetProgressorPosition ()
描述
更新进度条对话框中的状态栏。
语法
SetProgressorPosition ({position})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| position | 设置进度条对话框中状态栏的位置。 | Integer |
ResetProgressor ()
描述
将进度条重置为初始状态。
语法
ResetProgressor ()
代码示例
import arcpy, time
n = 5
p = 1
readTime = 1.5 # 停顿时间
loopTime = 0.3 # 循环迭代延时
# 首先显示的是默认的进度条显示形式
# time sleep() 函数推迟调用线程的运行,可通过参数(指秒数),表示进程挂起的时间。
arcpy.SetProgressor("default", "This is the default progressor")
time.sleep(readTime)
# 模拟显示执行多个任务时进度条及进度标签
for i in xrange(1, 5):
arcpy.SetProgressorLabel("Working on 'phase' {0}".format(i))
arcpy.AddMessage("Messages for phase {0}".format(i))
time.sleep(readTime)
# 设置进度条为步进显示形式
arcpy.SetProgressor("step",
"Step progressor: Counting from 0 to {0}".format(n),
0, n, p)
time.sleep(readTime)
# 通过循环模拟进度条步进显示
for i in range(n):
if (i % p) == 0:
arcpy.SetProgressorLabel("Iteration: {0}".format(i))
arcpy.SetProgressorPosition(i)
time.sleep(loopTime)
# 更新进度显示的最后部分(上面的range只是到4,进度不能到100%)
#
arcpy.SetProgressorLabel("Iteration: {0}".format(i + 1))
arcpy.SetProgressorPosition(i + 1)
# 信息框中添加进度向上显示完成消息
#
arcpy.AddMessage("Done counting up
")
time.sleep(readTime)
# 只是为了有趣,让进度条再倒回去
#
arcpy.SetProgressor("default", "Default progressor: Now we'll do a countdown")
time.sleep(readTime)
arcpy.AddMessage("Here comes the countdown...")
arcpy.SetProgressor("step",
"Step progressor: Counting backwards from {0}".format(n),
0, n, p)
time.sleep(readTime)
arcpy.AddMessage("Counting down now...
")
for i in range(n, 0, -1):
if (i % p) == 0:
arcpy.SetProgressorLabel("Iteration: {0}".format(i))
arcpy.SetProgressorPosition(i)
time.sleep(loopTime)
# 更新剩余进度显示
arcpy.SetProgressorLabel("Iteration: {0}".format(0))
arcpy.SetProgressorPosition(0)
time.sleep(readTime)
arcpy.AddMessage("All done")
arcpy.ResetProgressor()
使用以上脚本创建工具的运行结果
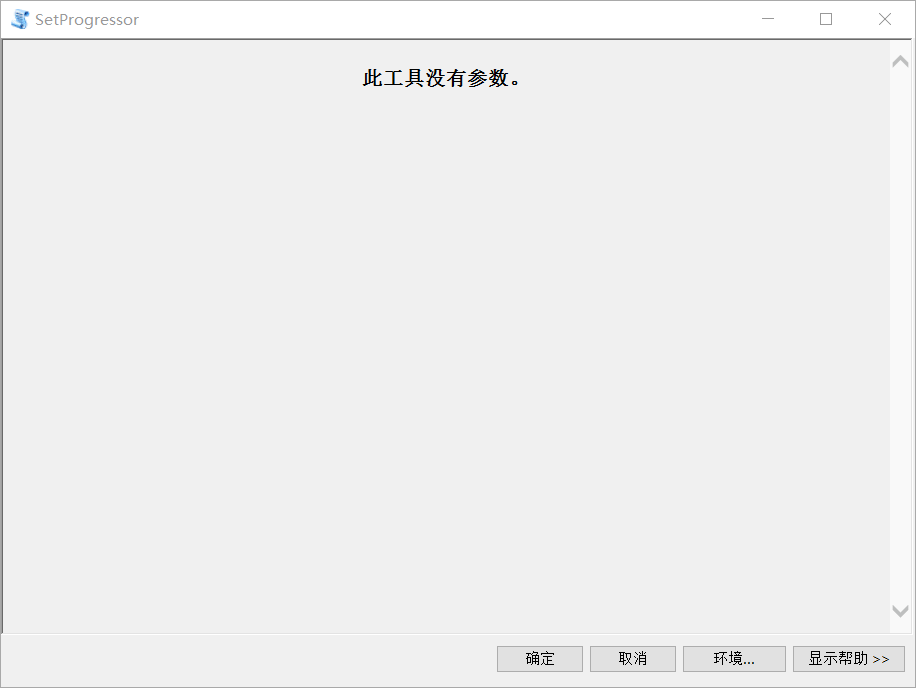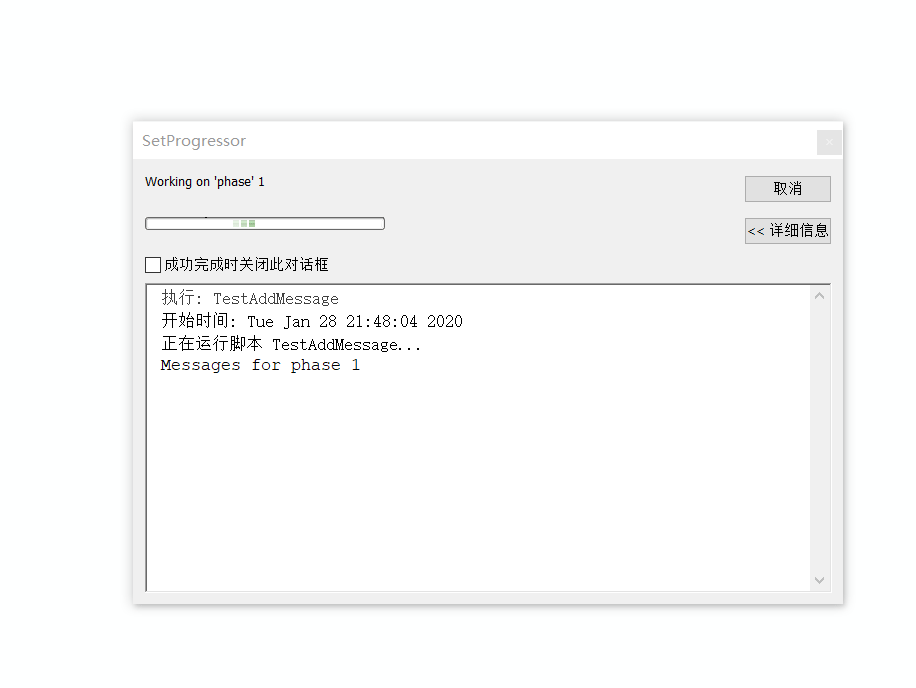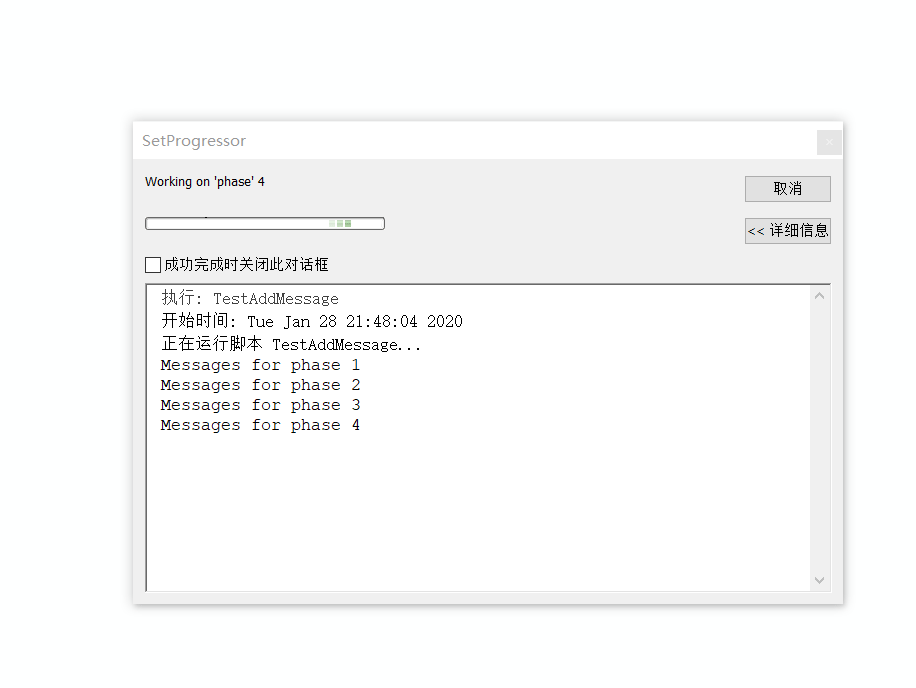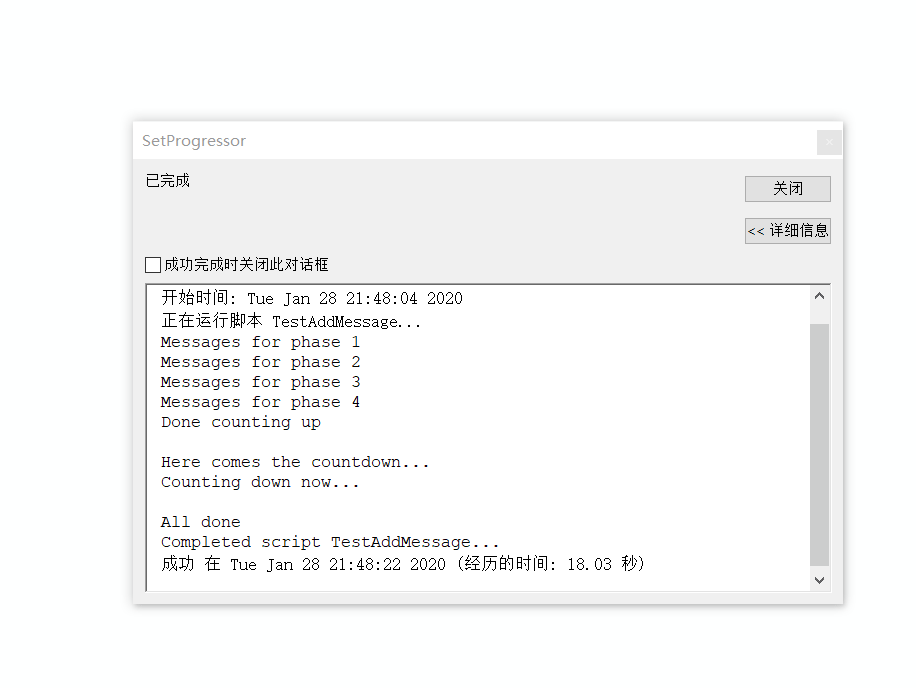
通过 Python 使用类
类(Class)是面向对象程序设计(OOP,Object-Oriented Programming)实现信息封装的基础。类是一种用户定义的引用数据类型,也称类类型(Object)。类的实例称为对象。
类一般都拥有属性和方法。类实例化之后,便可使用其属性和方法。(在此只罗列属性,方法请参考自带帮助)
类包含一个或多个方法,称为构造函数。构造函数用于初始化类的新实例。
常规
Index
描述
索引对象包含有关表索引的信息。存在两种索引类型:空间与属性。空间索引存在于要素类的 shape 字段中。
说明
无法直接创建索引对象。可通过 ListIndexes 和 Describe功能访问索引对象。
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| fields (只读) | 索引字段对象的 Python 列表。 | Field |
| isAscending (只读) | isAscending 状态:索引按升序排序时为真。 | Boolean |
| isUnique (只读) | isUnique 状态:索引唯一时为真。 | Boolean |
| name (只读) | 索引的名称。 | String |
Extent
描述
范围是在地图单位下提供左下角和右上角坐标指定的一个矩形。
语法
Extent ({XMin}, {YMin}, {XMax}, {YMax}, {ZMin}, {ZMax}, {MMin}, {MMax})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| XMin | 范围 XMin 值。 | Double |
| YMin | 范围 YMin 值。 | Double |
| XMax | 范围 XMax 值。 | Double |
| YMax | 范围 YMax 值。 | Double |
| ZMin | 范围 ZMin 值。如果无 Z 值,则为“无”。 | Double |
| ZMax | 范围 ZMax 值。如果无 Z 值,则为“无”。 | Double |
| MMin | 范围 MMin 值。如果无 M 值,则为“无”。 | Double |
| MMax | 范围 MMax 值。如果无 M 值,则为“无”。 | Double |
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| JSON (只读) | 返回一个字符串形式的范围 JSON 制图表达。 提示: 通过 Python 的 json.loads 函数,返回的字符串可转换至字典。 |
String |
| MMax (只读) | 范围 MMax 值。如果无 M 值,则为“无”。 | Double |
| MMin (只读) | 范围 MMin 值。如果无 M 值,则为“无”。 | Double |
| XMax (只读) | 范围 XMax 值。 | Double |
| XMin (只读) | 范围 XMin 值。 | Double |
| YMax (只读) | 范围 YMax 值。 | Double |
| YMin (只读) | 范围 YMin 值。 | Double |
| ZMax (只读) | 范围 ZMax 值。如果无 Z 值,则为“无”。 | Double |
| ZMin (只读) | 范围 ZMin 值。如果无 Z 值,则为“无”。 | Double |
| depth (只读) | 范围深度值。如果无深度,则为“无”。 | Double |
| height (只读) | 范围高度值。 | Double |
| lowerLeft (只读) | 左下角属性:将返回点对象。 | Point |
| lowerRight (只读) | 右下角属性:将返回点对象。 | Point |
| polygon (只读) | 以多边形对象的形式返回范围。 | Polygon |
| spatialReference (只读) | 范围的空间参考。 | SpatialReference |
| upperLeft (只读) | 左上角属性:将返回点对象。 | Point |
| upperRight (只读) | 右上角属性:将返回点对象 | Point |
| width (只读) | 范围宽度值。 | Double |
Array
描述
数组对象中可包含点和数组,它用于构造几何对象。
语法
Array ({items})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| items | 项目可以包含列表、点对象或另一个数组对象。 | Object |
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| count (只读) | 数组的元素计数。 | Integer |
方法概述
| 方法 | 说明 |
|---|---|
| add (value) | 将点或数组对象添加到数组的结尾处 |
| append (value) | 在数组中的最后一个位置追加一个对象。 |
| clone (point_object) | 克隆点对象。 |
| extend (items) | 通过追加元素扩展数组。 |
| getObject (index) | 返回数组中给定索引位置上的对象。 |
| insert (index, value) | 在数组中的指定索引处添加一个对象。 |
| next () | 返回当前索引中的下一个对象。 |
| remove (index) | 从数组中的指定索引位置移除对象。 |
| removeAll () | 移除所有值并创建一个空对象。 |
| replace (index, value) | 替换数组中指定索引位置上的对象。 |
| reset () | 将当前枚举索引(由 next 方法使用)设置回第一个元素。 |
方法
add (value)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| value | 点或数组对象均可以追加至该数组。 | Object |
append (value)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| value | 点或数组对象均可以追加至该数组。 | Object |
clone (point_object)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| point_object | 点对象。 | Point |
extend (items)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| items | 通过添加字符串、整数或列表扩展数组。 | Object |
getObject (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 数组的索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| Object | 索引位置上的数组或点对象。 |
insert (index, value)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 数组的索引位置。 | Integer |
| value | 点或数组对象均可以插入至该数组。 | Object |
next ()
返回值
| 数据类型 | 说明 |
|---|---|
| Object | 当前索引中的下一个对象。 |
remove (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 将被移除的索引位置。 | Integer |
removeAll ()
replace (index, value)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 将被替换的索引位置。 | Integer |
| value | 将被添加至该数组的新点或数组对象。 | Object |
reset ()
SpatialReference
描述
空间参考的每一部分都具有多个属性,特别是坐标系,它定义了哪些地图投影选项用于定义水平坐标。
说明
也可使用 Describe spatialReference 属性从现有数据集访问 SpatialReference 对象。
dataset = "c:/data/landbase.gdb/Wetlands"
spatial_ref = arcpy.Describe(dataset).spatialReference
语法
SpatialReference ({item}, {vcs})
item
用于创建 SpatialReference 的坐标系。可使用投影文件、名称、工厂代码或熟知文本 (WKT) 格式进行设置。
vcs
垂直坐标系 (VCS)。VCS 用于定义有关 Z 坐标的信息。可使用名称、工厂代码或熟知文本 (WKT) 格式进行设置。
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| GCS (只读) | 投影坐标系将针对其基于的地理坐标系返回 SpatialReference 对象。地理坐标系将返回相同的 SpatialReference。 | SpatialReference |
| MDomain (只读) | 测量域的范围。 | String |
| MFalseOriginAndUnits (只读) | 测量假定原点和单位。 | String |
| MResolution (可读写) | 测量分辨率。 | Double |
| MTolerance (可读写) | 测量容差。 | Double |
| VCS (只读) | 如果坐标系具有垂直坐标系,将针对其基于的垂直坐标系返回 VCS 对象。 | Object |
| XYResolution (可读写) | xy 分辨率。 | Double |
| XYTolerance (可读写) | xy 容差。 | Double |
| ZDomain (只读) | Z 值域的范围。 | String |
| ZFalseOriginAndUnits (只读) | Z 假定原点和单位。 | String |
| ZResolution (可读写) | Z 分辨率属性。 | Double |
| ZTolerance (可读写) | Z 容差属性。 | Double |
| abbreviation (可读写) | 空间参考的缩写名称。 | String |
| alias (可读写) | 空间参考的别名。 | String |
| domain (只读) | xy 属性域的范围。 | String |
| factoryCode (可读写) | 空间参考的工厂代码或熟知 ID (WKID)。 | Integer |
| falseOriginAndUnits (只读) | 假定原点和单位。 | String |
| hasMPrecision (只读) | 指示是否已定义 m 值精度信息。 | Boolean |
| hasXYPrecision (只读) | 指示是否已定义 xy 精度信息。 | Boolean |
| hasZPrecision (只读) | 指示是否已定义 z 值精度信息。 | Boolean |
| isHighPrecision (可读写) | 指示空间参考是否已设置高精度。 | Boolean |
| name (可读写) | 空间参考的名称。 | String |
| remarks (可读写) | 空间参考的注释字符串。 | String |
| type (可读写) | 空间参考的类型。 Geographic - 地理坐标系。 Projected - 投影坐标系。 | String |
| usage (只读) | 用法说明。 | String |
| PCSCode (可读写) | 投影坐标系代码。1 | Integer |
| PCSName (可读写) | 投影坐标系名称。1 | String |
| azimuth (可读写) | 投影坐标系的方位角。1 | Double |
| centralMeridian (可读写) | 投影坐标系的中央经线。1 | Double |
| centralMeridianInDegrees (可读写) | 投影坐标系的中央经线 (Lambda0)(以度为单位)。1 | Double |
| centralParallel (可读写) | 投影坐标系的中央纬线。1 | Double |
| classification (只读) | 地图投影的分类。1 | String |
| falseEasting (可读写) | 投影坐标系的东偏移量。1 | Double |
| falseNorthing (可读写) | 投影坐标系的北偏移量。1 | Double |
| latitudeOf1st (可读写) | 投影坐标系第一个点的纬度。1 | Double |
| latitudeOf2nd (可读写) | 投影坐标系第二个点的纬度。1 | Double |
| latitudeOfOrigin (可读写) | 投影坐标系原点的纬度。1 | Double |
| linearUnitCode (可读写) | 线性单位代码。1 | Integer |
| linearUnitName (可读写) | 线性单位名称。1 | String |
| longitude (可读写) | 此本初子午线的经度值。1 | Double |
| longitudeOf1st (可读写) | 投影坐标系第一个点的经度。1 | Double |
| longitudeOf2nd (可读写) | 投影坐标系第二个点的经度。1 | Double |
| longitudeOfOrigin (可读写) | 投影坐标系原点的经度。1 | Double |
| metersPerUnit (只读) | 米/线性单位。1 | Double |
| projectionCode (可读写) | 投影代码。1 | Integer |
| projectionName (可读写) | 投影名称。1 | String |
| scaleFactor (可读写) | 投影坐标系的比例因子。1 | Double |
| standardParallel1 (可读写) | 投影坐标系的第一条纬线。1 | Double |
| standardParallel2 (可读写) | 投影坐标系的第二条纬线。1 | Double |
| GCSCode (可读写) | 地理坐标系代码。2 | Integer |
| GCSName (可读写) | 地理坐标系名称。2 | String |
| angularUnitCode (可读写) | 角度单位代码。2 | Integer |
| angularUnitName (可读写) | 角度单位名称。2 | String |
| datumCode (可读写) | 基准代码。2 | Integer |
| datumName (可读写) | 基准名称。2 | String |
| flattening (可读写) | 此椭球体的扁率。2 | Double |
| longitude (可读写) | 此本初子午线的经度值。2 | Double |
| primeMeridianCode (可读写) | 本初子午线代码。2 | Integer |
| primeMeridianName (可读写) | 本初子午线名称。2 | String |
| radiansPerUnit (只读) | 每角度单位的弧度。2 | Double |
| semiMajorAxis (可读写) | 此椭球体的半长轴长度。2 | Double |
| semiMinorAxis (可读写) | 此椭球体的半短轴长度。2 | Double |
| spheroidCode (可读写) | 椭球体代码。2 | Integer |
| spheroidName (可读写) | 椭球体名称。2 | String |
Result
描述
通过地理处理工具返回 Result 对象。
说明
Result 对象的优点是可以保留工具执行的相关信息,包括消息、参数和输出。即使在运行了多个其他工具后仍可保留这些结果。
语法
Result (toolname, resultID)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| toolname | 已执行工具的名称。 | String |
| resultID | 作业 ID。 | Integer |
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| inputCount (只读) | 返回输入数目。 | Integer |
| maxSeverity (只读) | 返回消息的最大严重性。 0 —如果工具仅产生了信息性消息。 1 — 如果工具产生了警告消息,但未出现错误消息。 2 — 如果工具产生了错误消息。 | Integer |
| messageCount (只读) | 返回消息数目。 | Integer |
| outputCount (只读) | 返回输出数目。 | Integer |
| resultID (只读) | 获得作业 ID。如果工具不是地理处理服务,resultID 将为 ""。 | String |
| status (只读) | 获得作业状态。 0 —新建 1 —已提交 2 —正在等待 3 —执行中 4 —成功 5 —失败 6 —超时 7 —正在取消 8 —已取消 9 —删除中 10 —已删除 | Integer |
方法
cancel ()
getInput (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 输入的索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| Object | 记录集或者字符串形式的输入。 |
getMapImageURL ({parameter_list}, {height}, {width}, {resolution})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| parameter_list | 地图服务影像所基于的参数。 | Integer |
| height | 影像的高度。 | Double |
| width | 影像的宽度。 | Double |
| resolution | 影像的分辨率。 | Double |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 地图影像的 URL。 |
getMessage (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 消息的索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 地理处理消息。 |
getMessages ({severity})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| severity | 要返回的消息类型:0 = 消息,1 = 警告,2 = 错误。如果未指定值,则返回所有消息类型。 0 —信息性消息 1 —警告消息 2 —错误消息 (默认值为 0) | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 地理处理消息。 |
getOutput (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 输出的索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| Object | 输出为记录集或者字符串形式。 如果工具(如 MakeFeatureLayer)的输出是一个图层,则 getOutput 将返回 Layer 对象。 还可按索引访问结果输出,因此 result.getOutput(0) 和 result[0] 是等效的。 |
getSeverity (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 消息索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| Integer | 特定消息的严重性。 0 —信息性消息 1 —警告消息 2 —错误消息 |
saveToFile (rlt_file)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| rlt_file | 输出结果文件的完整路径(.rlt)。 | String |
Raster
描述
创建一个可在 Python 脚本或地图代数表达式中使用的栅格对象。栅格对象是一个引用栅格数据集的变量。
创建栅格对象有两种方法。可通过提供指向磁盘上某一现有栅格数据的路径来创建栅格对象;另外,任何可输出栅格的地图代数语句,其结果也可以作为栅格对象。
语法
Raster (inRaster)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| inRaster | 输入栅格数据集。 | Raster |
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| bandCount (只读) | 参考栅格数据集中的波段数。 | Integer |
| catalogPath (只读) | 参考栅格数据集的完整路径和名称。 | String |
| compressionType (只读) | 压缩类型。以下是可用的类型: LZ77 JPEG JPEG 2000 PACKBITS LZW RLE CCITT GROUP 3 CCITT GROUP 4 CCITT (1D) 无 | String |
| extent (只读) | 参考栅格数据集的范围。 | Extent |
| format (只读) | 栅格格式 BIL - Esri 波段按行交叉格式文件 BIP - Esri 波段按像元交叉格式文件 BMP - 位图图形栅格数据集格式 BSQ - Esri 波段顺序格式文件 DAT - ENVI DAT 文件 GIF - 栅格数据集的图形交换格式 Grid - Esri Grid 栅格数据集格式 IMAGINE 图像 - ERDAS IMAGINE 栅格数据格式 JP2000 - JPEG 2000 栅格数据集格式 JPEG - 联合图像专家组栅格数据集格式 PNG - 可移植网络图形栅格数据集格式 TIFF - 栅格数据集的标记图像文件格式 | String |
| hasRAT (可读写) | 识别是否存在相关的属性表:如果存在则为 True,如果不存在则为 False。 | Boolean |
| height (只读) | 行数。 | Integer |
| isInteger (只读) | 如果栅格数据集具有整型,则为 True。 | Boolean |
| isTemporary (只读) | 如果栅格数据集是临时的,则为 True,或者,如果是永久的,则为 False。 | Boolean |
| maximum (只读) | 参考栅格数据集中的最大值。 | Double |
| mean (只读) | 参考栅格数据集中的平均值。 | Double |
| meanCellHeight (只读) | y 方向上的像元大小。 | Double |
| meanCellWidth (只读) | x 方向上的像元大小。 | Double |
| minimum (只读) | 参考栅格数据集中的最小值。 | Double |
| name (只读) | 参考栅格数据集的名称。 | String |
| noDataValue (只读) | 参考栅格数据集中的 NoData 值。 | Double |
| path (只读) | 参考栅格数据集的完整路径和名称。 | String |
| pixelType (只读) | 参考栅格数据集的像素类型。类型如下: U1 - 1 位 U2 - 2 位 U4 - 4 位 U8 - 无符号 8 位整数 S8 - 8 位整数 U16 - 无符号 16 位整数 S16 - 16 位整数 U32 - 无符号 32 位整数 S32 - 32 位整数 F32 - 单精度浮点 F64 - 双精度浮点 | String |
| spatialReference (只读) | 参考栅格数据集的空间参考。 | SpatialReference |
| standardDeviation (只读) | 参考栅格数据集中值的标准偏差。 | Double |
| uncompressedSize (只读) | 磁盘上参考栅格数据集的大小。 | Double |
| width (只读) | 列数。 | Integer |
方法概述
| 方法 | 说明 |
|---|---|
| save ({name}) | 永久保存栅格对象引用的数据集。 |
方法
save ({name})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| name | 分配给磁盘上的栅格数据集的名称。 | String |
ValueTable
描述
值表是一种灵活的对象,可用作多值参数的输入。它仅在创建此表的地理处理对象的生存时间内存在。
说明
setRow 的值参数以空格分隔。含有空格的值参数中使用的所有值均必须用引号括起。在下例中,向包含两列的值表中分别添加了一个要素类和一个索引值:
value_table.setRow(0, "'c:/temp/land use.shp' 2")
语法
ValueTable ({columns})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| columns | 列数。 (默认值为 1) | Integer |
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| columnCount (只读) | 列数。 | Integer |
| rowCount (只读) | 行数。 | Integer |
方法概述
| 方法 | 说明 |
|---|---|
| addRow (value) | 向值表中添加一行。 addRow 的值参数是以空格分隔的。含有空格的值参数中使用的所有值均必须用引号括起。在下例中,向包含两列的值表中分别添加了一个要素类和一个索引值: vtab.addRow("'c:/temp/land use.shp' 2") |
| exportToString () | 将对象导出至其字符串表示。 |
| getRow (row) | 获取值表中的某一行。 |
| getTrueValue (row, column) | 获取给定的列和行中的值。 |
| getValue (row, column) | 获取给定的列和行中的值。 |
| loadFromString (string) | 使用对象的字符串表示来恢复对象。可以使用 exportToString 方法创建字符串表示。 |
| removeRow (row) | 从值表中删除一行。 |
| setColumns (number_of_columns) | 设置值表的列数。 |
| setRow (row, value) | 更新值表中的给定行。 setRow 的值参数以空格分隔。含有空格的值参数中使用的所有值均必须用引号括起。在下例中,向包含两列的值表中分别添加了一个要素类和一个索引值: vtab.setRow(0, "'c:/temp/land use.shp' 2") |
| setValue (row, column, value) | 更新给定行或列的值。 |
方法
addRow (value)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| value | 要添加的行。 | Object |
exportToString ()
返回值
| 数据类型 | 说明 |
|---|---|
| String | 对象的字符串表示。 |
getRow (row)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row | 行索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 值表中的某一行。 |
getTrueValue (row, column)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row | 行索引位置。 | Integer |
| column | 列索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 给定的列和行中的值。 |
getValue (row, column)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row | 行索引位置。 | Integer |
| column | 列索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 给定的列和行中的值。 |
loadFromString (string)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| string | 对象的字符串表示。 | String |
removeRow (row)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row | 待移除行的索引位置。 | Integer |
setColumns (number_of_columns)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| number_of_columns | 值表的列数。 | Integer |
setRow (row, value)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row | 待更新行的索引位置。 | Integer |
| value | 用于更新给定行的值。 | Object |
setValue (row, column, value)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row | 行索引。 | Integer |
| column | 列索引。 | Integer |
| value | 用于更新给定行和列的值。 | Object |
环境
env
描述
环境设置以 ArcPy env 类的属性的方式公开。这些属性可用于检索或设置当前值。可将地理处理环境设置视为影响工具执行结果的附加参数。
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| addOutputsToMap (可读写) | 将工具生成的输出数据集添加到应用程序显示中。从工具内部运行时该设置不起作用。 | Boolean |
| autoCancelling (可读写) | 可用于脚本工具或 Python 工具箱工具。 如果将 autoCancelling 设置为 True,则取消将结束当前行上的脚本。如果设置为 False,则取消可将 isCancelled 属性设置为 True,然后继续执行。默认名称为 True。 | Boolean |
| autoCommit (可读写) | 支持“自动提交”环境的工具将在企业级地理数据库事务中进行指定次数的更改后强制执行提交。 | Long |
| buildStatsAndRATForTempRaster (可读写) | 控制统计数据的计算,以及由 Spatial Analyst 工具所创建的临时栅格的栅格属性表 (RAT) 的构建。默认名称为 True。 如果设置为 False,则考虑到符号化栅格图层的目的,统计数据将为近似值,并且将不会构建 RAT。 | Boolean |
| cartographicCoordinateSystem (可读写) | 支持“制图坐标系”环境的工具将使用指定的坐标系来确定进行计算时要素的大小、范围和空间关系。 | String |
| cartographicPartitions (可读写) | 采用制图分区环境的工具将通过指定的分区面要素细分输入要素,以便按顺序处理,从而避免处理大型数据集时可能遇到的内存限制。 | String |
| cellSize (可读写) | 支持“像元大小”环境设置的工具可以设置在操作时使用的输出栅格像元大小或分辨率。默认输出分辨率由最粗糙的输入栅格数据集决定。 | String |
| cellSizeProjectionMethod (可读写) | 在分析期间投影数据集时,支持“像元大小投影方法”环境的工具将使用指定的方法计算输出栅格像元大小 | String |
| coincidentPoints (可读写) | 支持“重合点”环境的工具可以定义如何在 Geostatistical Analyst 中处理重合数据。 | String |
| compression (可读写) | 支持压缩环境设置的工具将在存储输出栅格数据集时设置压缩类型。 | String |
| configKeyword (可读写) | 遵循“输出配置关键字”的工具在地理数据库中创建数据集时将使用指定的关键字。 | String |
| derivedPrecision (可读写) | 遵循“派生 Coverage 的精度”环境的工具,用于根据此设置创建精度由输入 coverage 确定的输出 coverage。 | String |
| extent (可读写) | 支持“范围”环境的工具仅处理落入此设置中所指定范围内的要素或栅格。 | String |
| geographicTransformations (可读写) | 支持“地理(坐标)变换”环境的工具将在投影数据时使用变换方法。 | String |
| isCancelled (只读) | 可用于脚本工具或 Python 工具箱工具。 如果 autoCancelling 设置为 False 并且已取消工具,则 isCancelled 将设置为 True。默认情况下,isCancelled 为 False,且为只读属性。 | Boolean |
| maintainSpatialIndex (可读写) | 支持“维护空间索引”环境的工具可删除并重新创建企业级地理数据库要素类的空间索引,也可以保留空间索引但进行更新,具体情况取决于设置。 | Boolean |
| mask (可读写) | 支持“掩膜”环境的工具只会考虑运行过程中落入分析掩膜范围内的像元。 | String |
| MDomain (可读写) | 遵循“输出 M 属性域”环境的工具将生成具有指定测量 (m) 属性域的输出数据集。 | String |
| MResolution (可读写) | 支持此环境的工具可将 M 分辨率应用到输出地理数据集中。 | Double |
| MTolerance (可读写) | 遵循这一环境的工具会覆盖在地理数据库内创建的地理数据集上的默认 M 容差。 | Double |
| newPrecision (可读写) | 遵循“新 Coverage 的精度”环境的工具将创建具有指定精度的输出 Coverage。 | String |
| nodata (可读写) | 支持 NoData 环境设置的工具将仅处理其中 NoData 有效的栅格。 | String |
| outputCoordinateSystem (可读写) | 支持“输出坐标系”环境的工具将创建已指定坐标系的输出地理数据集。 | String |
| outputMFlag (可读写) | 遵循“输出包含 M 值”环境的工具将控制地理数据集是否存储 M 值。 | String |
| outputZFlag (可读写) | 遵循“输出包含 Z 值”环境的工具将控制地理数据集是否存储 Z 值。 | String |
| outputZValue (可读写) | 支持此环境的工具可为每个尚不具有 z 坐标的输出折点设置 z 坐标。 | String |
| overwriteOutput (可读写) | 管理工具在运行时是否自动覆盖任何现有输出。设置为 True 时,工具将执行并覆盖输出数据集。设置为 False 时,将不会覆盖现有输出,工具将返回错误。 | Boolean |
| packageWorkspace (只读) | 包工作空间环境设置是用于定位所共享的地理处理包或服务内容的文件夹所处的位置。 | String |
| parallelProcessingFactor (可读写) | 支持并行处理因子环境的工具将跨多个进程分隔并执行操作。 | Integer |
| processingServer (可读写) | 启用栅格处理系统服务的 ArcGIS 服务器 URL。 | String |
| processingServerPassword (可读写) | 与获得使用栅格处理服务权限的用户名关联的密码。 | String |
| processingServerUser (可读写) | 获得使用栅格处理服务权限的用户名。 | String |
| projectCompare (可读写) | 支持“投影文件之间的比较级别”环境的工具仅在输入投影与指定的相似度匹配时才执行。 | String |
| pyramid (可读写) | 支持“金字塔”环境设置的工具将仅处理金字塔有效的栅格。ERDAS IMAGINE 文件的金字塔具有可以设置的有限选项。 | String |
| qualifiedFieldNames (可读写) | 遵循“限定的字段名”环境的工具将使用此设置来区分限定的字段名和未限定的字段名。限定的字段名是要素类或表中的这样一些字段名称,在它们的字段名称后会附加原始要素类或表的名称。使用连接数据时,会涉及此设置。 | Boolean |
| randomGenerator (可读写) | 使用“随机数生成器”环境的工具将通过利用种子和分布的各种算法来生成一系列随机数。 | Object |
| rasterStatistics (可读写) | 依据“栅格统计”环境的工具控制为输出栅格数据集构建统计数据的方式。 | String |
| referenceScale (可读写) | 依据“参考比例”环境的工具根据符号化要素在参考比例的显示情况设置其图形大小和范围。 | Double |
| resamplingMethod (可读写) | 重采样是在变换栅格数据集时内插像素值的过程。在以下情况使用:输入和输出排列不对应、像素大小发生变化、数据被平移或以上原因的综合。 | String |
| scratchFolder (只读) | 临时文件夹环境设置是一个文件夹位置,可用来写入基于文件的数据(如 shapefile、文本文件和图层文件)。它是一个由 ArcGIS 管理的只读环境。 | String |
| scratchGDB (只读) | 临时 GDB 环境设置是可以用来写入临时数据的文件地理数据库的位置。 | String |
| scratchWorkspace (可读写) | 支持“临时工作空间”环境设置的工具可将指定的位置用作输出数据集的默认工作空间。 | String |
| snapRaster (可读写) | 支持“捕捉栅格”环境的工具将调整输出栅格的范围,以使它们的像元对齐方式与指定的捕捉栅格的像元对齐方式相匹配。 | String |
| spatialGrid1 (可读写) | 遵循“输出空间格网 1、2 和 3”环境的工具将创建具有指定空间索引格网的要素类(如果要素类支持空间索引格网)。 | Double |
| spatialGrid2 (可读写) | 遵循“输出空间格网 1、2 和 3”环境的工具将创建具有指定空间索引格网的要素类(如果要素类支持空间索引格网)。 | Double |
| spatialGrid3 (可读写) | 遵循“输出空间格网 1、2 和 3”环境的工具将创建具有指定空间索引格网的要素类(如果要素类支持空间索引格网)。 | Double |
| terrainMemoryUsage (可读写) | 支持 Terrain 内存使用环境的工具控制对 terrain 进行分析时的内存使用情况。 | Boolean |
| tileSize (可读写) | 支持“分块大小”环境的工具用于为存储在数据块中的栅格设置分块大小。 | String |
| tinSaveVersion (可读写) | 遵循“TIN 存储版本”设置的工具将输出指定版本的 TIN 表面。 | String |
| transferDomains (可读写) | 此地理处理环境用于控制输出 shapefile 和 dBASE (.dbf) 表除了包含域和子类型编码的字段之外,是否还需具有包含域和子类型描述的字段。仅在地理处理工具的输入参数是一个定义了域和子类型的地理数据库要素类或表时,此设置才是重要的。默认情况下,shapefile 或 dBASE (.dbf) 输出中仅包括域和子类型编码。 | Boolean |
| workspace (可读写) | 支持“当前工作空间”环境设置的工具将指定的工作空间用作地理处理工具输入和输出的默认位置。 | String |
| XYDomain (可读写) | 支持“输出 XY 范围域”环境的工具可为输出地理数据集的 x,y 范围域设置特定范围。 | String |
| XYResolution (可读写) | 支持此环境的工具可将 x,y 分辨率应用到输出地理数据集中。 | String |
| XYTolerance (可读写) | 支持此环境的工具会覆盖在地理数据库内创建的地理数据集上的默认 x,y 容差。 | String |
| ZDomain (可读写) | 支持“输出 Z 属性域”环境的工具将生成带有指定 z 属性域的输出数据集。 | String |
| ZResolution (可读写) | 支持此环境的工具可将 z 分辨率应用到输出地理数据集中。 | String |
| ZTolerance (可读写) | 支持此环境的工具会覆盖在地理数据库内创建的地理数据集上的默认 z 容差。 | String |
示例代码
import arcpy, os
print "Not defined scratchWorkspace:"
print arcpy.env.scratchWorkspace
print("Defined folder as scratchWorkspace:")
desktopFolder = os.path.join(os.path.expanduser("~"), 'Desktop')
arcpy.env.scratchWorkspace = desktopFolder
print(arcpy.env.scratchWorkspace)
运行结果
Not defined scratchWorkspace:
None
Defined folder as scratchWorkspace:
C:UsersAdminDesktop
EnvManager
描述
EnvManager 是用于管理 地理处理环境 的类。
由 EnvManager 类设置的环境设置是临时性设置,仅在 with 块的持续时间内进行设置。with 块完成后,传递到 EnvManager 类的环境会重置为 EnvManager 类之前的值(无需自行重置环境值)。
语法
EnvManager (**kwargs)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| **kwargs | 环境设置作为关键字参数传递,可使用环境名称传递一个或多个环境。 with arcpy.EnvManager(cellSize=10, extent='-16, 25, 44, 64'): # Code to be executed with the environments set |
Variant |
方法概述
| 方法 | 说明 |
|---|---|
| reset () | 将环境设置的值重置为调用 EnvManager 之前的值。 |
方法
reset ()
Geometry
注:Geometry 章节示例代码不用于测试,如需测试请参考 写入几何、读取几何。
Geometry
描述
几何对象定义空间位置和关联几何形状。
说明
在许多地理处理工作流中,您可能需要使用坐标和几何信息运行特定操作,但不一定想经历创建新(临时)要素类、使用光标填充要素类、使用要素类,然后删除临时要素类的过程。可以使用几何对象替代输入和输出,从而使地理处理变得更简单。使用 Geometry、Multipoint、PointGeometry、Polygon 或 Polyline 类可以从头开始创建几何对象。
注:点 POINT 并非几何类,但通常用于构造几何。
语法
Geometry (geometry, inputs, {spatial_reference}, {has_z}, {has_m})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| geometry | 几何类型:点、面、折线或多点。 | String |
| inputs | 用于创建对象的坐标。数据类型可以是 Point 或 Array 对象。 | Object |
| spatial_reference | 新几何的空间参考。 (默认值为 None) | SpatialReference |
| has_z | Z 状态:如果启用 Z,则为几何的 True,如果未启用,则为 False。 (默认值为 False) | Boolean |
| has_m | M 状态:如果启用 M,则为几何的 True,如果未启用,则为 False。 (默认值为 False) | Boolean |
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| JSON (只读) | 返回一个字符串形式的几何 Esri JSON 制图表达。 提示: 通过 Python 的 json.loads 函数,返回的字符串可转换至字典。 |
String |
| WKB (只读) | 返回 OGC 几何的熟知二进制 (WKB) 制图表达。该存储类型将几何值表示为不间断的字节流形式。 | Bytearray |
| WKT (只读) | 返回 OGC 几何的熟知文本 (WKT) 制图表达。其将几何值表示为文本字符串。 几何中的所有真曲线都将在 WKT 字符串的近似曲线中进行增密。 | String |
| area (只读) | 面要素的面积。其他所有要素类型为空。 | Double |
| centroid (只读) | 如果质心位于要素之内或要素之上则为真;否则返回标注点。返回点对象。 | Point |
| extent (可读写) | 几何范围。 | Extent |
| firstPoint (只读) | 第一个几何坐标点。 | Point |
| hullRectangle (只读) | 以空格分隔的凸包矩形坐标对的字符串。 | String |
| isMultipart (只读) | 如果此几何的部分数大于一,则为 True。 | Boolean |
| labelPoint (只读) | 标注位置所在的点。labelPoint 始终位于要素之内/之上。 | Point |
| lastPoint (只读) | 要素的最后一个坐标。 | Point |
| length (只读) | 线状要素的长度。点和多点要素类型为零。 | Double |
| length3D (可读写) | 线状要素的 3D 长度。点和多点要素类型为零。 | Double |
| partCount (只读) | 要素几何部分的数目。 | Integer |
| pointCount (只读) | 要素的总点数。 | Integer |
| spatialReference (只读) | 几何的空间参考。 | SpatialReference |
| trueCentroid (只读) | 要素的重心。 | Point |
| type (只读) | 几何类型:面、折线、点、多点、多面体、尺寸或注记。 | String |
Point
描述
点对象经常与光标配合使用。点要素将返回单个点对象而不是点对象数组。而其他要素类型(面、折线和多点)都将返回一个点对象数组,并且当这些要素具有多个部分时,则返回包含多个点对象数组的数组。
说明
点并非几何类,但通常用于构造几何。在以下示例中,点用于创建 PointGeometry 对象。
point = arcpy.Point(25282, 43770)
ptGeometry = arcpy.PointGeometry(point)
PointGeometry
描述
PointGeometry 为没有给定比例长度和面积的类型。
说明
在许多地理处理工作流中,您可能需要使用坐标和几何信息运行特定操作,但不一定想经历创建新(临时)要素类、使用光标填充要素类、使用要素类,然后删除临时要素类的过程。可以使用几何对象替代输入和输出,从而使地理处理变得更简单。使用 Geometry、Multipoint、PointGeometry、Polygon 或 Polyline 类可以从头开始创建几何对象。
示例代码
point = arcpy.Point(25282, 43770)
ptGeometry = arcpy.PointGeometry(point)
MultiPoint
描述
Multipoint 对象就是点的有序集合。
语法
Multipoint (inputs, {spatial_reference}, {has_z}, {has_m})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| inputs | 用于创建对象的坐标。数据类型可以是 Point 或 Array 对象。 | Object |
| spatial_reference | 新几何的空间参考。 (默认值为 None) | SpatialReference |
| has_z | Z 状态:如果启用 Z,则为几何的 True,如果未启用,则为 False。 (默认值为 False) | Boolean |
| has_m | M 状态:如果启用 M,则为几何的 True,如果未启用,则为 False。 (默认值为 False) | Boolean |
示例代码
point1 = (77.4349451, 37.5408265)
point2 = (77.4349451, 35.7780943)
multiPoint1 = (point1, point2)
Polyline
描述
折线对象是由一个或多个路径定义的形状,其中路径是指一系列相连线段。
语法
Polyline (inputs, {spatial_reference}, {has_z}, {has_m})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| inputs | 用于创建对象的坐标。数据类型可以是 Point 或 Array 对象。 | Object |
| spatial_reference | 新几何的空间参考。 (默认值为 None) | SpatialReference |
| has_z | Z 状态:如果启用 Z,则为几何的 True,如果未启用,则为 False。 (默认值为 False) | Boolean |
| has_m | M 状态:如果启用 M,则为几何的 True,如果未启用,则为 False。 (默认值为 False) | Boolean |
示例代码
point1 = arcpy.Point(77.4349451, 37.5408265)
point2 = arcpy.Point(77.4349451, 35.7780943)
polyLine1 = arcpy.Polyline(arcpy.Array([point1, point2]))
Polygon
描述
面对象是指由一系列相连的 x,y 坐标对定义的闭合形状。
语法
Polygon (inputs, {spatial_reference}, {has_z}, {has_m})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| inputs | 用于创建对象的坐标。数据类型可以是 Point 或 Array 对象。 | Object |
| spatial_reference | 新几何的空间参考。 (默认值为 None) | SpatialReference |
| has_z | Z 状态:如果启用 Z,则为几何的 True,如果未启用,则为 False。 (默认值为 False) | Boolean |
| has_m | M 状态:如果启用 M,则为几何的 True,如果未启用,则为 False。 (默认值为 False) | Boolean |
示例代码
point1 = arcpy.Point(77.4349451, 37.5408265)
point2 = arcpy.Point(77.4349451, 35.7780943)
point3 = arcpy.Point(78.6384349, 35.7780943)
point4 = arcpy.Point(78.6384349, 37.5408265)
polygon = arcpy.Polygon(arcpy.Array([point1, point2, point3, point4]))
游标
-
这里介绍的是上一代10.0版本的游标,自10.0版本之后新引入的arcpy.da 游标性能要更好,代码写起来也简单些。
-
10.1之后的arcpy.da的搜索和更新游标对象返回一组迭代元组和列表,之前的游标对象返回的是一组迭代行对象。
Cursor
描述
Cursor 是一种数据访问对象,可用于在表中迭代一组行或者向表中插入新行。游标有三种形式: 搜索、 插入或 更新。游标通常用于读取和更新属性。
方法概述
| 方法 | 说明 |
|---|---|
| deleteRow (row) | 删除数据库中的某一行。将删除与游标当前所在位置相对应的行。 |
| insertRow (row) | 向数据库中插入新行。 |
| newRow () | 创建空行对象。 |
| next () | 返回当前索引中的下一个对象。 |
| reset () | 将当前枚举索引(由 next 方法使用)设置回第一个元素。 |
| updateRow (row) | updateRow 方法可用于对更新游标当前所在的行进行更新。 |
方法
deleteRow (row)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row | 要删除的行。 | Row |
insertRow (row)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row | 要插入的行。 | Row |
newRow ()
返回值
| 数据类型 | 说明 |
|---|---|
| Row | 新的空行对象。 |
next ()
返回值
| 数据类型 | 说明 |
|---|---|
| Object | 当前索引中的下一个对象。 |
reset ()
updateRow (row)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row | 用于更新游标当前所在位置的行。 | Row |
Row
描述
行对象表示表中的某一行。行对象会从 InsertCursor、SearchCursor 和 UpdateCursor 中返回。
说明
行对象动态支持数据源的字段名称作为读/写属性。不能直接支持作为属性的字段名称(如包含期间的限定字段名称),可使用 setValue 和 getValue 方法进行访问。
方法概述
| 方法 | 说明 |
|---|---|
| getValue (field_name) | 获取字段值。 |
| isNull (field_name) | 字段值是否为空。 |
| setNull (field_name) | 将字段值设置为空。 |
| setValue (field_name, object) | 设置字段值。 |
方法
getValue (field_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| field_name | 将从中访问值的字段。 | String |
返回值
| 数据类型 | 说明 |
|---|---|
| Object | 字段值。 |
isNull (field_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| field_name | 要查询的字段。 | None |
返回值
| 数据类型 | 说明 |
|---|---|
| Boolean | 如果字段值为空,则为 True。 |
setNull (field_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| field_name | 将设置为空的字段。 | String |
setValue (field_name, object)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| field_name | 将设置为新值的字段。 | String |
| object | 用于设置字段值的值。 | Object |
测试代码
import arcpy, os
arcpy.CreateTable_management(os.getcwd(), "TestCursor.dbf")
in_table = os.getcwd() + os.sep + "TestCursor.dbf"
arcpy.AddField_management(in_table, "REMARKS", "TEXT", field_length=20)
# Test InsertCursor
rows = arcpy.InsertCursor(in_table)
for i in range(1, 16):
row = rows.newRow()
row.setValue("Field1", i)
rows.insertRow(row)
del row
del rows
# Test SearchCursor
field_addDelimiters = arcpy.AddFieldDelimiters(os.getcwd(), "Field1")
sql_clause = field_addDelimiters + " < 7"
print sql_clause
sum_number = 0
rows = arcpy.SearchCursor(in_table, sql_clause)
for row in rows:
sum_number += row.getValue("Field1")
print "The sum of 1 to 7 is " + str(sum_number)
del row
del rows
# Test UpdateCursor
print sql_clause
rows = arcpy.UpdateCursor(in_table, sql_clause)
for row in rows:
print row.getValue("Field1")
row.setValue("REMARKS", str(row.getValue("Field1")) + " is smaller than 7")
rows.updateRow(row)
del row
del rows
sql_clause = field_addDelimiters + " > 7"
print sql_clause
rows = arcpy.UpdateCursor(in_table, sql_clause, ["Field1", "REMARKS"])
row = rows.next()
while row:
print row.getValue("Field1")
row.setValue("REMARKS", str(row.getValue("Field1")) + " is bigger than 7")
rows.updateRow(row)
row = rows.next()
del row
del rows
运行结果
"Field1" < 7
The sum of 1 to 7 is 21
"Field1" < 7
1
2
3
4
5
6
"Field1" > 7
8
9
10
11
12
13
14
15
例外情况
ExecuteError
描述
每当地理处理工具遇到错误时,都将触发 ExecuteError 异常类。
ExecuteWarning
描述
地理处理工具遇到警告时,将触发 ExecuteWarning 异常类,并且 SetSeverityLevel 函数将严重性级别更新为 1。将严重性级别设置为 1 后,将在遇到警告时指示 arcpy 抛出 ExecuteWarning 异常。
测试代码
import arcpy, os
arcpy.SetSeverityLevel(1)
# Test ExecuteError
try:
arcpy.GetCount_management("")
except arcpy.ExecuteError:
print(arcpy.GetMessages(2))
# Test ExecuteWarning
try:
arcpy.CreateFeatureclass_management(os.getcwd(), "TestExecuteShp.shp")
arcpy.DeleteFeatures_management(os.getcwd() + os.sep + "TestExecuteShp.shp")
except arcpy.ExecuteWarning:
print(arcpy.GetMessages(1))
arcpy.Delete_management(os.getcwd() + os.sep + "TestExecuteShp.shp")
运行结果
执行失败。参数无效。
ERROR 000735: 输入行: 值是必需的
执行(GetCount)失败。
WARNING 000117: 警告: 生成的输出为空。
注:运行 DeleteFeatures 工具总会引发 ExecuteWarning 警告。
通过 Python 使用环境设置
每个工具都含有一组用于执行操作的参数。其中一些参数在所有工具中通用,如容差或输出位置。这些参数可从所有工具在运行期间使用的地理处理环境中获得默认值。
获取和设置环境设置
环境设置以env类的属性的方式公开。这些属性可用于检索或设置当前值。环境可作为环境类中的读/写属性进行访问(读写时要了解对应属性是否为可读或可写,可在帮助——基础工具——环境中查看),方法为 arcpy.env.<环境名称>。
GetSystemEnvironment ()
描述
获取指定的系统环境变量值,例如“TEMP”、“TMP”和“MW_TMPDIR”。
语法
GetSystemEnvironment (environment)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| environment | 系统环境变量的名称。 | String |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 以字符串形式返回指定系统环境变量值。 |
SaveSettings ()
描述
将环境设置保存到环境设置文件中(以可扩展标记语言 [XML] 形式存储文本)。另请参阅 LoadSettings,了解从 XML 文件加载环境设置的方法。
语法
SaveSettings (file_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| file_name | 将存储当前环境设置的要创建的 XML 文件。 | String |
LoadSettings ()
描述
从环境设置文件加载环境设置(以可扩展标记语言 [XML] 形式存储文本)。另请参阅SaveSettings,了解保存环境设置的方法。
语法
LoadSettings (file_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| file_name | 包含环境设置的现有 XML 文件。 | String |
代码示例
# -*- coding: cp936 -*-
import arcpy, os
# 获取到的结果可能为空
print arcpy.GetSystemEnvironment("TEMP")
print arcpy.GetSystemEnvironment("TMP")
print arcpy.GetSystemEnvironment("MW_TMPDIR")
# 获取默认的overwriteOutput环境值,并将overwriteOutput设为True
print arcpy.env.overwriteOutput
arcpy.env.overwriteOutput = True
print arcpy.env.overwriteOutput
# 保存当前环境设置,并将overwriteOutput设为False
arcpy.SaveSettings(os.path.join(os.path.expanduser("~"), "Desktop", "MyCustomSettings.xml"))
arcpy.env.overwriteOutput = False
print arcpy.env.overwriteOutput
# 重新读取导出的环境设置文件
arcpy.LoadSettings(os.path.join(os.path.expanduser("~"), "Desktop", "MyCustomSettings.xml"))
print arcpy.env.overwriteOutput
运行结果
C:UsersAdminAppDataLocalTemp
C:UsersAdminAppDataLocalTemp
False
True
False
True
使用环境设置处理临时数据
scratchGDB 和 scratchFolder 环境是提供保证存在的地理数据库和文件夹位置的只读环境。这意味着,您可以随时可靠地使用地理数据库或文件夹,而不必进行创建或管理。
scratchFolder 环境的设置如下:
- 如果未设置 scratchWorkspace,则 scratchFolder 会默认为当前用户的临时文件目录。
- 如果 scratchWorkspace 引用一个地理数据库,则 scratchFolder 将是包含该地理数据库的文件夹。
- 如果 scratchWorkspace 被设置为文件夹,则 scratchFolder 将与 scratchWorkspace 相同。
scratchGDB 环境的设置如下:
- 如果未设置 scratchWorkspace,则 scratchGDB 将默认为当前用户临时文件目录中名为 scratch.gdb 的地理数据库。
- 如果 scratchWorkspace 引用一个地理数据库,则 scratchGDB 将与 scratchWorkspace 相同。
- 如果 scratchWorkspace 被设置为文件夹,则 scratchGDB 将被设置为 scratchWorkspace 文件夹中名为 scratch.gdb 的地理数据。
import arcpy, os
print "Not defined scratchWorkspace:"
print arcpy.env.scratchWorkspace
print arcpy.env.scratchFolder
print arcpy.env.scratchGDB
print "Defined folder as scratchWorkspace:"
desktopFolder = os.path.join(os.path.expanduser("~"), 'Desktop')
arcpy.env.scratchWorkspace = desktopFolder
print arcpy.env.scratchWorkspace
print arcpy.env.scratchFolder
print arcpy.env.scratchGDB
print "Defined GDB as scratchWorkspace:"
arcpy.CreateFileGDB_management(desktopFolder, "TestScratchWorkspace.gdb")
arcpy.env.scratchWorkspace = desktopFolder + os.sep + "TestScratchWorkspace.gdb"
print arcpy.env.scratchWorkspace
print arcpy.env.scratchFolder
print arcpy.env.scratchGDB
arcpy.Delete_management(desktopFolder + os.sep + "TestScratchWorkspace.gdb")
运行结果
当桌面不存在scratch和scratch.gdb时会自动创建(手动删除即可)
Not defined scratchWorkspace:
None
C:UsersAdminAppDataLocalTempscratch
C:UsersAdminAppDataLocalTempscratch.gdb
Defined folder as scratchWorkspace:
C:UsersAdminDesktop
C:UsersAdminDesktopscratch
C:UsersAdminDesktopscratch.gdb
Defined GDB as scratchWorkspace:
C:UsersAdminDesktopTestScratchWorkspace.gdb
C:UsersAdminDesktopscratch
C:UsersAdminDesktopscratch.gdb
重新设置环境
由于地理处理环境对工具操作和输出有着很大的影响,因此需要保证能够追踪环境设置并在必要时将其重置为默认状态。
可使用 ResetEnvironments 函数恢复默认环境值,或者使用 ClearEnvironment 函数重置特定环境。
示例代码
import arcpy
# Reset geoprocessing environment settings 重置地理处理环境设置
arcpy.ResetEnvironments()
# Reset a specific environment setting 重置指定的地理处理设置
arcpy.ClearEnvironment("workspace")
使用 Python 处理错误
错误总是在所难免。编写可预见和处理错误的脚本可让您节省大量时间,同时避免很多令人头疼的问题。
当工具发出错误消息时,ArcPy 会生成 arcpy.ExecuteError 异常。如果脚本没有错误处理例程,则会立即失败,这就会降低它的稳定性。Python 允许您编写可在生成系统错误时立即自动运行的例程。在此错误处理例程中,可从 ArcPy 检索错误消息并作出相应的反应。可使用错误处理例程来管理错误并提高脚本的可用性。
try-except 语句
try-except 语句可用于封装整个程序或只封装代码的特定部分来捕捉和标识错误。如果 try 语句中发生错误,则会引发异常,然后会执行 except 语句下的代码。使用基本的 except 语句是最基本的错误处理方式。
raise 语句
在某些情况下,可能需要创建自定义的异常。此时,可使用 raise 语句。
ExecuteError 类
地理处理工具失败时会抛出 arcpy.ExecuteError 异常类,这说明您可以将错误分成不同的组,即将地理处理错误(抛出 arcpy.ExecuteError 异常的错误)归为一组,而将所有其他异常类型归为一组。
traceback
在较大较复杂的脚本中,可能很难确定错误的确切位置。可以将 Python 的 sys 和 traceback 模块结合使用来找出错误的准确位置和原因,这种方法可以较为准确地标识出错误的原因,从而节省您宝贵的调试时间。
sys.exc_info()返回的值是一个元组,其中第一个元素,exc_type是异常的对象类型,exc_value是异常的值,exc_tb是一个traceback对象,对象中包含出错的行数、位置等数据。
traceback模块提供了一个标准接口,用于提取,格式化和打印Python程序的堆栈跟踪。它在打印堆栈跟踪时完全模仿了Python解释器的行为。
traceback.format_tb(tb) 返回堆栈跟踪条目的列表,tb:要跟踪的traceback对象。
class NoFeatures(Exception):
pass
import arcpy
import os
import sys
import traceback
try:
## part1 Test ExecuteError
#arcpy.GetCount_management("")
## part2 Test raise
# arcpy.CreateFeatureclass_management(os.getcwd(), "testError.shp")
# result = arcpy.GetCount_management(os.getcwd() + os.sep + "testError.shp")
# if result[0] == "0":
# raise NoFeatures()
# arcpy.Delete_management(os.getcwd() + os.sep + "testError.shp")
## part3 Test traceback
x = "a" + 1
except arcpy.ExecuteError:
msgs = arcpy.GetMessages(2)
print(msgs)
except NoFeatures:
print "There is no features!"
except:
tb = sys.exc_info()[2]
tbinfo = traceback.format_tb(tb)[0]
pymsg = "PYTHON ERRORS:
Traceback info:
" + tbinfo + "
Error Info:
" + str(sys.exc_info()[1])
print(pymsg)
运行part1运行结果
执行失败。参数无效。
ERROR 000735: 输入行: 值是必需的
执行(GetCount)失败。
运行part2运行结果
There is no features!
运行part3运行结果
PYTHON ERRORS:
Traceback info:
File "E:/Code/Study/traceback1.py", line 22, in <module>
x = "a" + 1
Error Info:
cannot concatenate 'str' and 'int' objects
在Python中处理数据集
创建数据列表
批处理脚本的首要任务之一是为可用数据编写目录,以便在处理过程中可以遍历数据。ArcPy 具有多个专为创建此类列表而构建的函数。
| 函数 | 说明 |
|---|---|
| ListFields(dataset, wild_card, field_type) | 返回在输入值中找到的字段的列表 |
| ListIndexes(dataset, wild_card) | 返回在输入值中找到的属性索引的列表 |
| ListDatasets(wild_card, feature_type) | 返回当前工作空间中的数据集 |
| ListFeatureClasses(wild_card, feature_type, feature_dataset) | 返回当前工作空间中的要素类 |
| ListFiles(wild_card) | 返回当前工作空间中的文件 |
| ListRasters(wild_card, raster_type) | 返回在当前工作空间中找到的栅格数据的列表 |
| ListTables(wild_card, table_type) | 返回在当前工作空间中找到的表的列表 |
| ListWorkspaces(wild_card, workspace_type) | 返回在当前工作空间中找到的工作空间的列表 |
- 这些函数中每个函数的结果都是一个列表,该列表为值列表。
- 列表可以包含任何类型的数据,如字符串(例如,可以是数据集的路径、字段或表中的行)。
- 创建具有所需值的列表后,可在脚本中遍历该列表以处理各个值。
以下代码会在脚本路径下创建TestTableBatch文件夹——创建多个dbf表——添加TableName字段——将文件名写入
import arcpy, os
arcpy.CreateFolder_management(os.getcwd(), "TestTableBatch")
in_folder = os.getcwd() + os.sep + "TestTableBatch"
for i in range(20):
arcpy.CreateTable_management(in_folder, "tt" + str(i) + ".dbf")
arcpy.env.workspace = in_folder
table_list = arcpy.ListTables()
for table in table_list:
print table
arcpy.AddField_management(table, "TableName", "TEXT")
rows = arcpy.InsertCursor(table)
for i in range(1, 26):
row = rows.newRow()
row.setValue('TableName', table)
rows.insertRow(row)
del row
del rows
# arcpy.Delete_management(in_folder)
使用多值输入
很多地理处理工具的输入参数可接受多个值。
在 Python 窗口中查看工具引用页面或工具用法时,用括号 [ ] 括起来的参数表示其可接受值列表。
例如,删除字段工具可接受要删除的字段列表,参数用法为 [drop_field, ...]。某些参数(如联合工具的 input_features 参数)接受列表的列表。其用法显示为 [[in_features, {Rank}], ...]。
任何可接受值列表(或值列表的列表)的参数即为多值参数;可接受一个或多个值。可通过三种方式来指定多值参数:
- 列表形式,每个值都是列表的元素
- 字符串形式,各个值用分号进行分隔
- ValueTable 形式,各个值存储在一个由行和列组成的虚拟表中
使用列表形式删除字段
import arcpy, os
arcpy.CreateFeatureclass_management(os.getcwd(), "TestDeleteFields1.shp")
in_fc = os.getcwd() + os.sep + "TestDeleteFields1.shp"
for i in range(1, 10):
arcpy.AddField_management(in_fc, "Field" + str(i), "TEXT")
field_list = arcpy.ListFields(in_fc)
field_name_list = []
for field in field_list:
print field.name
if field.name != "Shape" and field.name != "FID" and field.name != "Id":
field_name_list.append(field.name)
arcpy.DeleteField_management(in_fc, field_name_list)
使用字符串形式删除字段
import arcpy, os
arcpy.CreateFeatureclass_management(os.getcwd(), "TestDeleteFields2.shp")
in_fc = os.getcwd() + os.sep + "TestDeleteFields2.shp"
for i in range(1, 10):
arcpy.AddField_management(in_fc, "Field" + str(i), "TEXT")
field_list = arcpy.ListFields(in_fc)
field_name_list = []
for field in field_list:
print field.name
if field.name != "Shape" and field.name != "FID" and field.name != "Id":
field_name_list.append(field.name)
field_name_str = ";".join(field_name_list)
arcpy.DeleteField_management(in_fc, field_name_str)
使用ValueTable 形式删除字段
import arcpy, os
arcpy.CreateFeatureclass_management(os.getcwd(), "TestDeleteFields3.shp")
in_fc = os.getcwd() + os.sep + "TestDeleteFields3.shp"
for i in range(1, 10):
arcpy.AddField_management(in_fc, "Field" + str(i), "TEXT")
field_list = arcpy.ListFields(in_fc)
vt = arcpy.ValueTable()
for field in field_list:
print field.name
if field.name != "Shape" and field.name != "FID" and field.name != "Id":
vt.addRow(field.name)
arcpy.DeleteField_management(in_fc, vt)
将输入字段映射到输出字段
常见的地理处理任务是将多个数据集合并到一个新的或现有的数据集中,以创建单个覆盖较大区域的数据集或包含大量记录的表。
通常,合并或追加操作中使用的所有输入项的属性或字段都是相同的;
但有时它们并不一致,因而必须对名称和类型不相同的字段之间的关系进行映射。
FieldMap
FieldMap 对象提供一个字段定义和一个输入字段列表,该输入字段列表来自一组为该字段定义提供值的表或要素类。
语法
FieldMap ()
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| inputFieldCount (只读) | 所定义的输入字段的数量。 | Integer |
| joinDelimiter (可读写) | 字符串值,用于在输出字段类型为字符串而 mergeRule 的值为 Join 时分隔同一个表中的输入值。 | String |
| mergeRule (可读写) | 定义如何将同一输入表中的两个或多个字段值合并成单个输出值。以下为有效选项: First —使用第一个输入值。 Last —使用最后一个输入值。 Join —将多个值合并到一起,可使用分隔符将多个值分开(仅当输出字段类型是文本时才有效)。 Min —使用最小的输入值(仅当输出字段类型是数值时才有效)。 Max —使用最大的输入值(仅当输出字段类型是数值时才有效)。 Mean —使用输入值的平均值(仅当输出字段类型是数值时才有效)。 Median —使用输入值的中值(仅当输出字段类型是数值时才有效)。 Sum —使用输入值的总和(仅当输出字段类型是数值时才有效)。 StDev —使用输入值的标准差(仅当输出字段类型是数值时才有效)。 Count —统计计算中包括的值的数目。这将计数除空值外的所有值。 |
String |
| outputField (可读写) | 输出字段的属性在 Field 对象中进行设置或返回。 | Field |
方法概述
| 方法 | 说明 |
|---|---|
| addInputField (table_dataset, field_name, {start_position}, {end_position}) | 将输入字段添加到字段映射。 |
| findInputFieldIndex (table_dataset, field_name) | 从字段映射查找输入字段。 |
| getEndTextPosition (index) | 获取字段映射的文本结束位置。 |
| getInputFieldName (index) | 根据字段索引,获取字段映射中输入字段的名称。 |
| getInputTableName (index) | 根据表索引,获取字段映射中输入表的名称。 |
| getStartTextPosition (index) | 获取字段映射的文本起始位置。 |
| removeAll () | 移除所有值并创建一个空对象。 |
| removeInputField (index) | 从字段映射中移除输入字段。 |
| setEndTextPosition (index, end_position) | 设置字段映射的文本结束位置。 |
| setStartTextPosition (index, start_position) | 设置字段映射的文本起始位置。 |
方法
addInputField (table_dataset, field_name, {start_position}, {end_position})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| table_dataset | 要添加到字段映射中的表。 | String |
| field_name | 输入字段名称。 | String |
| start_position | 输入文本值的起始位置。 (默认值为 -1) | Integer |
| end_position | 输入文本值的结束位置。 (默认值为 -1) | Integer |
findInputFieldIndex (table_dataset, field_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| table_dataset | 要添加到字段映射中的表。 | String |
| field_name | 字段名称。 | String |
返回值
| 数据类型 | 说明 |
|---|---|
| Integer | 字段名的索引位置。 |
getEndTextPosition (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| Integer | 文本结束位置。 |
getInputFieldName (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 输入字段名称。 |
getInputTableName (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| String | 输入表名称。 |
getStartTextPosition (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| Integer | 文本起始位置。 |
removeAll ()
removeInputField (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 索引位置。 | Integer |
setEndTextPosition (index, end_position)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 索引位置。 | Integer |
| end_position | 输入文本值的结束位置。 | Integer |
setStartTextPosition (index, start_position)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 索引位置。 | Integer |
| start_position | 输入文本值的起始位置。 | Integer |
FieldMappings
FieldMappings 对象是一组 FieldMap 对象,它用作执行字段映射的工具的参数值,如 Merge。
语法
FieldMappings ()
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| fieldCount (只读) | 输出字段的数目。 | Integer |
| fieldMappings (可读写) | 组成 FieldMappings 对象的 FieldMap 对象列表。 | FieldMap |
| fieldValidationWorkspace (可读写) | 定义属性字段命名规则的工作空间类型。确定输出字段名称时将使用这些规则,输出字段名称基于输入字段的名称。例如,将 fieldValidationWorkspace 属性设置为包含输入 shapefile 的磁盘上的文件夹路径时,会使输出字段名称截断为 10 个字符。将 fieldValidationWorkspace 属性设置为文件地理数据库路径时,可以使用更长的字段名称。设置 fieldValidationWorkspace 属性时,要注意输出格式。 | String |
| fields (只读) | 字段对象列表。每个字段对象分别表示一个输出字段的属性。 | Field |
方法概述
| 方法 | 说明 |
|---|---|
| addFieldMap (field_map) | 向字段映射中添加一个字段映射。 |
| addTable (table_dataset) | 将表添加到字段映射对象。 |
| exportToString () | 将对象导出至其字符串表示。 |
| findFieldMapIndex (field_map_name) | 按名称查找字段映射内的字段映射。 |
| getFieldMap (index) | 获取多个字段映射中的一个字段映射。 |
| loadFromString (string) | 使用对象的字符串表示来恢复对象。可以使用 exportToString 方法创建字符串表示。 |
| removeAll () | 移除所有值并创建一个空对象。 |
| removeFieldMap (index) | 从字段映射中移除一个字段映射。 |
| replaceFieldMap (index, value) | 在字段映射内替换一个字段映射。 |
方法
addFieldMap (field_map)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| field_map | 要添加到字段映射中的字段映射 | FieldMap |
addTable (table_dataset)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| table_dataset | 要添加到字段映射对象中的表。 | String |
exportToString ()
返回值
| 数据类型 | 说明 |
|---|---|
| String | 对象的字符串表示。 |
findFieldMapIndex (field_map_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| field_map_name | 按名称查找字段映射。 | String |
返回值
| 数据类型 | 说明 |
|---|---|
| Integer | 字段映射的索引位置。 |
getFieldMap (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 字段映射的索引位置。 | Integer |
返回值
| 数据类型 | 说明 |
|---|---|
| FieldMap | 多个字段映射中的一个字段映射。 |
loadFromString (string)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| string | 对象的字符串表示。 | String |
removeAll ()
removeFieldMap (index)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 字段映射的索引位置。 | Integer |
replaceFieldMap (index, value)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| index | 待替换的字段映射的索引位置。 | Integer |
| value | 替换字段映射。 | Field |
以下代码可在不更改现有表的情况下,查找各路的平均事故数量。
# -*- coding: cp936 -*-
import arcpy, os, random
# 创建输入表
arcpy.CreateTable_management(os.getcwd(), "TestFieldMap.dbf")
in_table = os.getcwd() + os.sep + "TestFieldMap.dbf"
# 添加RoadID和年度字段
arcpy.AddField_management(in_table, "RoadID", "TEXT", field_length=20)
for i in range(2009, 2020):
arcpy.AddField_management(in_table, "Y" + str(i), "SHORT")
# 向表中插入行
rows = arcpy.InsertCursor(in_table)
field_list = arcpy.ListFields(in_table, "Y*")
for i in range(1, 100):
row = rows.newRow()
row.setValue("RoadID", "Road" + str(i))
for field in field_list:
row.setValue(field.name, random.choice(range(30, 1000)))
rows.insertRow(row)
del row
del rows
# 创建FieldMap对象,并设置输入字段、合并规则、输出字段
fm1 = arcpy.FieldMap()
fm1.mergeRule = "Mean"
for field in field_list:
fm1.addInputField(in_table, field.name)
f_name = fm1.outputField
f_name.name = "MeanCount"
fm1.outputField = f_name
# 将fm1和fm1添加到创建的FieldMap对象fms中
fms = arcpy.FieldMappings()
fm2 = arcpy.FieldMap()
fm2.addInputField(in_table, "RoadID")
fms.addFieldMap(fm2)
fms.addFieldMap(fm1)
# 使用表至表工具并利用设置的字段映射将表转出
arcpy.TableToTable_conversion(in_table, os.getcwd(), "TestFieldMapOut.dbf", "", fms)
将 Python 脚本计划为在预定时间运行
计划 Python 脚本的方法取决于您的操作系统。以下为 Windows 操作系统的一般步骤。
- 打开“任务计划程序”向导。
- 双击添加计划任务(或创建基本任务)。
- 在向导中完成各个选项。这些选项包括要运行计划任务的时间、要运行脚本的路径以及脚本的所有参数。
在Python中访问地理数据
描述数据
地理处理工具可处理所有类型的数据,如地理数据库要素类、shapefile、栅格、表、拓扑和网络。
每种数据都具有可访问的特定属性,以进一步用于控制脚本流或用作工具参数。
例如,相交工具的输出要素类型取决于要相交的数据的形状类型,即点、线或面。在脚本中对输入数据集列表运行相交工具时,必须能够确定输入数据集的形状类型,以便设置正确的输出形状类型。
可以使用 Describe 函数确定所有输入数据集的形状类型。
import arcpy, os
arcpy.CreateFeatureclass_management(os.getcwd(), "TestGetShpPoint.shp", "POINT")
arcpy.CreateFeatureclass_management(os.getcwd(), "TestGetShpPolygon.shp", "POLYGON")
descPoint = arcpy.Describe(os.getcwd() + os.sep + "TestGetShpPoint.shp")
print descPoint.shapeType
descPolygon = arcpy.Describe(os.getcwd() + os.sep + "TestGetShpPolygon.shp")
print descPolygon.shapeType
运行结果
Point
Polygon
使用空间参考类
地理数据集(如要素类、coverage 和栅格)具有一个空间参考,用于定义数据集的坐标系、x,y 属性域、m 属性域和 z 属性域。
空间参考的每一部分都具有多个属性,特别是坐标系,它定义了哪些地图投影选项用于定义水平坐标。所有这些信息都可以通过描述数据集并访问其空间参考属性获取,该属性实际上是另一个包含多个属性的对象。
创建空间参考
将一个空间参考的所有详细信息都保存在一个 Python 脚本中通常不太现实。通过将投影文件、工厂代码或空间参考名称用作 SpatialReference 类的参数,您可以快速完成空间参考属性的设置并将对象作为地理处理工具的输入。在下面的示例中,将使用提供的工厂代码(也称之为权限代码)作为输入参数来构造空间参考。
# -*- coding:cp936 -*-
import arcpy, os
# 测试地理坐标系
print u"测试地理坐标系"
spatialReference = arcpy.SpatialReference(4326)
arcpy.CreateFeatureclass_management(os.getcwd(), "TestGeographicSpatialReference.shp",
spatial_reference=spatialReference)
desc = arcpy.Describe(os.getcwd() + os.sep + "TestGeographicSpatialReference.shp")
desc_spatialReference = desc.spatialReference
print u"空间参考名称:{0}
空间参考类型:{1}
工厂代码:{2}".format(desc_spatialReference.name, desc_spatialReference.type,desc_spatialReference.factoryCode)
# 测试投影坐标系
print u"测试投影坐标系"
spatialReference = arcpy.SpatialReference(4545)
arcpy.CreateFeatureclass_management(os.getcwd(), "TestProjectedSpatialReference.shp",
spatial_reference=spatialReference)
desc = arcpy.Describe(os.getcwd() + os.sep + "TestProjectedSpatialReference.shp")
desc_spatialReference = desc.spatialReference
print u"空间参考名称:", desc_spatialReference.name
print u"空间参考类型:", desc_spatialReference.type
print u"工厂代码:", desc_spatialReference.factoryCode
print u"地理坐标系代码:", desc_spatialReference.GCSCode
print u"地理坐标系名称:", desc_spatialReference.GCSName
print u"投影坐标系代码:", desc_spatialReference.PCSCode
print u"投影坐标系名称:", desc_spatialReference.PCSName
print u"投影坐标系中央经线:", desc_spatialReference.centralMeridian
print u"投影代码:", desc_spatialReference.projectionCode
print u"投影名称:", desc_spatialReference.projectionName
运行结果
测试地理坐标系
空间参考名称:GCS_WGS_1984
空间参考类型:Geographic
工厂代码:4326
测试投影坐标系
空间参考名称: CGCS2000_3_Degree_GK_CM_108E
空间参考类型: Projected
工厂代码: 4545
地理坐标系代码: 0
地理坐标系名称:
投影坐标系代码: 4545
投影坐标系名称: CGCS2000_3_Degree_GK_CM_108E
投影坐标系中央经线: 108.0
投影代码: 43005
投影名称: Gauss_Kruger
factoryCode:空间参考的工厂代码或熟知 ID (WKID)。
提示:有关坐标系名称和工厂代码的详细信息,请参阅 ArcGIS 文档文件夹中的 geographic_coordinate_systems.pdf 和 projected_coordinate_systems.pdf 文件。
注:要获取属性和方法的完整列表,请参阅 SpatialReference 类。
处理要素集和记录集
FeatureSet 对象是要素类的轻量化表示。它们是一种既包含方案(几何类型、字段和空间参考)也包含数据(包括几何)的特殊数据元素。RecordSet 对象与上述对象类似,但其功能可与表相媲美。在脚本工具中使用时,要素集和记录集可用于以交互方式定义要素和记录。
FeatureSet 和 RecordSet 类包含两个相同的方法。
FeatureSet
| 属性 | 说明 |
|---|---|
| load | 将要素类导入到 FeatureSet 对象中。 |
| save | 导出到地理数据库要素类或 shapefile。 |
RecordSet
| 属性 | 说明 |
|---|---|
| load | 将表导入到 RecordSet 对象中。 |
| save | 导出到地理数据库表或 dBASE 文件。 |
创建和使用 FeatureSet 和 RecordSet 对象
根据需求和应用,可以通过多种方法创建 FeatureSet 和 RecordSet 对象。load 方法可用于将新要素或行添加到对象,而 save 方法可用于将要素或行保留在磁盘中。此外,还可将输入要素类或表作为参数提供给类。FeatureSet 和 RecordSet 对象还可以直接作为地理处理工具的输入来使用。
创建空要素集。
import arcpy
# Create an empty FeatureSet object
feature_set = arcpy.FeatureSet()
根据输入要素类构造要素集。
import arcpy
# Construct a FeatureSet from a feature class
feature_set = arcpy.FeatureSet("c:/base/roads.shp")
示例:使用光标和内存中的要素类将数据加载到要素集并保存为shp文件
# -*- coding: cp936 -*-
import arcpy,os
arcpy.env.overwriteOutput = True
# 坐标列表
coordinates = [[-117.196717216, 34.046944853],
[-117.186226483, 34.046498438],
[-117.179530271, 34.038016569],
[-117.187454122, 34.039132605],
[-117.177744614, 34.056765964],
[-117.156205131, 34.064466609],
[-117.145491191, 34.068261129],
[-117.170825195, 34.073618099],
[-117.186784501, 34.068149525],
[-117.158325598, 34.03489167]]
# 在内存中创建要素类
feature_class = arcpy.CreateFeatureclass_management(
"in_memory", "tempfc", "POINT")[0]
# 使用插入游标
with arcpy.da.InsertCursor(feature_class, ["SHAPE@XY"]) as cursor:
# 遍历坐标列表并添加到游标
for (x, y) in coordinates:
cursor.insertRow([(x, y)])
# Create a FeatureSet object and load in_memory feature class
feature_set = arcpy.FeatureSet()
feature_set.load(feature_class)
feature_set.save(os.getcwd()+os.sep+"TestFeatureset.shp")
检查数据是否存在
要检查脚本中是否存在数据,请使用 Exists 函数。
测试在执行期间当前工作空间中是否存在要素类、表、数据集、shapefile、工作空间、图层和其他文件。函数返回指示元素是否存在的布尔值。
在脚本中,所有工具的默认行为是不覆盖任何已存在的输出。可通过将 overwriteOutput 属性设置为 True (arcpy.env.overwriteOutput = True) 来更改此行为。在 overwriteOutput 为 False 时,试图进行覆盖将会导致工具无法使用。
使用Python指定查询
结构化查询语言 (SQL) 是一种功能强大的语言,可定义一个或多个由属性、运算符和运算组成的判定条件。例如,假设有一份客户数据表,要在其中查找去年花费超过 $50,000 且业务类型是餐馆的客户。则可以使用以下表达式选择客户:“Sales > 50000 AND Business_type = 'Restaurant'”。
当为更新或搜索游标指定查询时,仅返回满足该查询的记录。一个 SQL 查询代表了一个可使用 SQL SELECT 语句对 SQL 数据库中的表进行的单个表查询子集。用于指定 WHERE 子句的语法与保存数据的基础数据库的语法相同。
在 SQL 表达式中使用 AddFieldDelimiters
SQL 表达式中使用的字段分隔符因所查询数据的格式而异。例如,文件地理数据库和 shapefile 使用双引号 (" "),个人地理数据库使用方括号 ([ ]),而 ArcSDE 地理数据库不使用字段分隔符。 AddFieldDelimiters 函数可免去一些为确保与 SQL 表达式一起使用的字段分隔符的正确性而进行的推测过程。
以下代码标记了低纬度的点
import arcpy, os, random
point_list = []
for i in range(0, 100):
point_list.append(arcpy.Point(random.randint(73, 135), random.randint(0, 90)))
out_fc = os.getcwd() + os.sep + "TestSQLPoint.shp"
pointGeometryList = []
for point in point_list:
pointGeometryList.append(arcpy.PointGeometry(point))
arcpy.CopyFeatures_management(pointGeometryList, out_fc)
spatialReference = arcpy.SpatialReference(4326)
arcpy.DefineProjection_management(out_fc, spatialReference)
arcpy.AddField_management(out_fc, "Y", "SHORT")
arcpy.CalculateField_management(out_fc, "Y", "!shape.centroid.Y!", "PYTHON_9.3")
field_delimiters = arcpy.AddFieldDelimiters(os.getcwd(), "Y")
arcpy.AddField_management(out_fc, "CLASS", "TEXT", field_length=50)
where_clause = field_delimiters + "<=30"
with arcpy.da.UpdateCursor(out_fc, ["CLASS"], where_clause) as cursor:
for row in cursor:
row[0] = "Low latitude"
cursor.updateRow(row)
使用Python进行地理处理
导入模块
ArcPy 提供了一种用于开发 Python 脚本的功能丰富的动态环境,同时提供每个函数、模块和类的代码实现和集成文档。
在导入 ArcPy 之后,可以运行随 ArcGIS 安装的标准工具箱中的所有地理处理工具。
模块为通常包含函数和类的 Python 文件。ArcPy 由一系列模块支持,包括数据访问模块 (arcpy.da)、制图模块 (arcpy.mapping)、ArcGIS Spatial Analyst 扩展模块 模块 (arcpy.sa) 以及 ArcGIS Network Analyst 扩展模块 模块 (arcpy.na)。
可以使用相似的导入方式:
# Import arcpy, os and sys
#
import arcpy
import os
import sys
参数介绍
每个地理处理工具都具有一组固定的参数,包括必选参数和可选参数,这些参数为工具提供执行所需的信息。工具通常包含多个输入参数以定义一个或多个数据集,这些数据集一般用于生成新的输出数据。参数具有几个重要属性:
- 每个参数具有一种或多种特定的数据类型,如要素类、整型、字符串或栅格。
- 参数为输入值或输出值。
- 参数需有值,或为可选。
- 各个工具参数都具有唯一的名称。
可选参数的处理方式:
-
一种方法是保持所有可选参数有序,然后将您不需要的参数引用为空字符串 ""、井号 "#" 或类型为 None 的参数。
-
另一种方法是使用关键字参数,并使用参数名称来分配值。使用关键字参数可以跳过未使用的可选参数或以不同的顺序指定它们。
以下三种调用工具方法等效
arcpy.AddField_management(in_table, "RoadID", "TEXT", "", "", 20)
arcpy.AddField_management(in_table, "RoadID", "TEXT", "#", "#", 20)
arcpy.AddField_management(in_table, "RoadID", "TEXT", field_length=20)
调用工具方法
有两种方式调用工具,一种是通过调用函数的方式,一种是通过通过匹配工具箱别名的形式。这里只介绍第一种。
arcpy.<toolname_toolboxalias>(<Required parameters>{,<Option parameters>})
语法特点
使用地理处理工具的语法大多遵循下列规则:
-
工具函数由两部分组成,工具名称和工具箱别名,工具名称中间没有空格,工具名称采用Pascal命名法,工具箱别名为英文小写字母。
-
先输入必选参数,再输入可选参数
-
通常第一个参数为输入数据集,随后是输出数据集,接下来是必选参数,最后是可选参数
-
输入数据集的参数名一般以”in“为前缀(如in_data、in_features、in_table、in_workspace),输出数据集的参数名一般以”out“为前缀(如out_data、out_features、out_table)
注意:
Python区分大小写,Clip和clip是不同的。
使用的引号为英文引号(""),不是中文引号(”“)。
使用Python游标
使用游标访问数据
使用列表函数可以遍历列表中的一系列数据,这些数据可以是要素类、属性表和字段。同样地,使用游标可以遍历属性表中的每一行数据。游标是一个数据库术语,它主要用于访问表格的每一行记录或者向表中插入新的记录。在表格中,一条记录也称为一行。
游标有三种形式:搜索(SearchCursor)、插入(InsertCursor)和更新(UpdateCursor)。功能如下:
- 搜索游标可用于检索行。
- 插入游标可用于向表或要素类中插入行。
- 更新游标可用于根据位置更新和删除行。
在 ArcGIS 10.1 中引入了 arcpy.da 游标(arcpy.da.SearchCursor、arcpy.da.UpdateCursor 和 arcpy.da.InsertCursor),与先前已存在的游标功能(arcpy.SearchCursor、arcpy.UpdateCursor 和 arcpy.InsertCursor)组相比性能要快得多。仍然会提供原始游标,不过仅仅是为了能够继续向后兼容。这里主要介绍新的游标。
这三种游标都有两个必选参数,输入表和字段名称列表(或组)。搜索和更新游标还有其他几个可选参数。
arcpy.da.InsertCursor (in_table, field_names)
arcpy.da.SearchCursor (in_table, field_names, {where_clause}, {spatial_reference}, {explode_to_points}, {sql_clause})
arcpy.da.UpdateCursor (in_table, field_names, {where_clause}, {spatial_reference}, {explode_to_points}, {sql_clause})
各游标类型支持的方法
| 游标类型 | 方法 | 功能 |
|---|---|---|
| 插入 | InsertRow | 向表中插入行对象 |
| 插入 | next | 检索下一个行对象 |
| 搜索 | next | 检索下一个行对象 |
| 搜索 | reset | 将游标还原到初始位置 |
| 更新 | deleteRow | 从表中删除行 |
| 更新 | next | 检索下一个行对象 |
| 更新 | reset | 将游标还原到初始位置 |
| 更新 | updateRow | 更新当前行对象 |
注意:
- 游标只能向前导航。如果脚本需要多轮次遍历数据,应用程序必须重新执行游标函数。
- 搜索和更新游标可以通过for循环或while循环,并使用游标的next方法遍历每一行记录。
- 如果要在游标上使用next方法来检索行数为n的表中的所有记录,脚本必须反复调用next方法n次。
- 当游标遍历到最后一行时,再次调用next方法时会出现一个StopIteration异常。
- 搜索和更新游标还支持with语句。使用with语句后,无论游标成功运行还是出现异常,都可以保证数据库锁的关闭和释放(而不用删除Cursor对象),并重置迭代。
- 10.1之后的arcpy.da的搜索和更新游标对象返回一组迭代元组和列表,之前的游标对象返回的是一组迭代行对象。
Row
描述
行对象表示表中的某一行。行对象会从 InsertCursor、 SearchCursor 和 UpdateCursor 中返回。
说明
行对象动态支持数据源的字段名称作为读/写属性。不能直接支持作为属性的字段名称(如包含期间的限定字段名称),可使用 setValue 和 getValue 方法进行访问。
方法概述
| 方法 | 说明 |
|---|---|
| getValue (field_name) | 获取字段值。 |
| isNull (field_name) | 字段值是否为空。 |
| setNull (field_name) | 将字段值设置为空。 |
| setValue (field_name, object) | 设置字段值。 |
方法
getValue (field_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| field_name | 将从中访问值的字段。 | String |
返回值
| 数据类型 | 说明 |
|---|---|
| Object | 字段值。 |
isNull (field_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| field_name | 要查询的字段。 | None |
返回值
| 数据类型 | 说明 |
|---|---|
| Boolean | 如果字段值为空,则为 True。 |
setNull (field_name)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| field_name | 将设置为空的字段。 | String |
setValue (field_name, object)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| field_name | 将设置为新值的字段。 | String |
| object | 用于设置字段值的值。 | Object |
InsertCursor
描述
InsertCursor 可在要素类或表上建立写入游标。可以使用 InsertCursor 来添加新行。
说明
对点要素类使用 InsertCursor 时,创建 PointGeometry 并将其设置为 SHAPE@ 令牌操作的代价相对较高。此时,使用诸如 SHAPE@XY、SHAPE@Z 和 SHAPE@M 等令牌定义的点要素访问反而更为快速有效。
语法
InsertCursor (in_table, field_names)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| in_table | 要素类、图层、表或表视图。 | String |
| field_names [field_names,...] | 字段名称列表(或组)。对于单个字段,可以使用一个字符串,而不使用字符串列表。 如果要访问输入表中的所有字段(栅格和 BLOB 字段除外),可以使用星号 (*) 代替字段列表。但是,为了获得较快的性能和可靠的字段顺序,建议您将字段列表限制在实际需要的字段。 不支持栅格字段。 以令牌(如 OID@)取代字段名称可访问更多的信息: SHAPE@XY —一组要素的质心 x,y 坐标。 SHAPE@XYZ —一组要素的质心 x,y,z 坐标。仅当几何启用了 z 值时,才支持此令牌。 SHAPE@TRUECENTROID —一组要素的质心 x,y 坐标。这会返回与 SHAPE@XY 相同的值。 SHAPE@X —要素的双精度 x 坐标。 SHAPE@Y —要素的双精度 y 坐标。 SHAPE@Z —要素的双精度 z 坐标。 SHAPE@M —要素的双精度 m 值。 SHAPE@JSON — 表示几何的 Esri JSON 字符串。 SHAPE@WKB —OGC 几何的熟知二进制 (WKB) 制图表达。该存储类型将几何值表示为不间断的字节流形式。 SHAPE@WKT —OGC 几何的熟知文本 (WKT) 制图表达。其将几何值表示为文本字符串。 SHAPE@ —要素的几何对象。 面、折线或多点要素仅可使用 SHAPE@ 令牌创建。 |
String |
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| fields (只读) | 游标使用的一组字段名称。 该组将包括由 field_names 参数指定的所有字段(和令牌)。如果 field_names 参数设置为 *,则字段属性将包括游标使用的全部字段。使用 * 时,几何值将以 x,y 坐标组返回(相当于 SHAPE@XY 令牌)。 fields 属性中字段名称的排序顺序将与 field_names 参数的传递顺序一致。 |
tuple |
方法概述
| 方法 | 说明 |
|---|---|
| insertRow (row) | 向表中插入一行。 |
方法
insertRow (row)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row [row,...] | 值列表或组。值的顺序必须与创建光标时所指定的顺序相同。 更新字段时,如果传入的值与字段类型匹配,则将根据需要对这些值进行转换。例如,将值 1.0 添加到字符串字段将添加为 "1.0";将值 "25" 添加到浮点型字段将添加为 25.0。 |
tuple |
返回值
| 数据类型 | 说明 |
|---|---|
| Integer | insertRow 将返回新行的 objectid。 |
SearchCursor
描述
SearchCursor 用于建立从要素类或表中返回的记录的只读访问权限。
将返回一组迭代元组。元组中值的顺序与 field_names 参数指定的字段顺序相符。
说明
Geometry 属性可通过在字段列表中指定令牌 SHAPE@ 进行访问。
使用 for 循环可迭代搜索游标。搜索游标也支持 with 语句以重置迭代并帮助移除锁。但是,为了防止锁定所有内容,应考虑使用 del 语句来删除对象或将游标包含在函数中以使游标对象位于作用范围之外。
利用属性条件或空间条件,可以限制 SearchCursor 返回的记录。
使用 SHAPE@ 访问整个几何是一种代价较高的操作。如果只需几何信息(如点的 x,y 坐标),请使用 SHAPE@XY、SHAPE@Z 和 SHAPE@M 等令牌进行更快速、更高效的访问。
在 Python 2 中,SearchCursor 支持迭代器 .next() 方法,在循环外检索下一行。在 Python 3 中,可使用 Python 内置 next() 函数执行等效操作。
语法
SearchCursor (in_table, field_names, {where_clause}, {spatial_reference}, {explode_to_points}, {sql_clause})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| in_table | 要素类、图层、表或表视图。 | String |
| field_names [field_names,...] | 字段名称列表(或组)。对于单个字段,可以使用一个字符串,而不使用字符串列表。 如果要访问输入表中的所有字段(栅格和 BLOB 字段除外),可以使用星号 (*) 代替字段列表。但是,为了获得较快的性能和可靠的字段顺序,建议您将字段列表限制在实际需要的字段。 不支持栅格字段。 以令牌(如 OID@)取代字段名称可访问更多的信息: SHAPE@XY —一组要素的质心 x,y 坐标。 @XYZ —一组要素的质心 x,y,z 坐标。仅当几何启用了 z 值时,才支持此令牌。 SHAPE@TRUECENTROID —一组要素的质心 x,y 坐标。这会返回与 SHAPE@XY 相同的值。 SHAPE@X —要素的双精度 x 坐标。 SHAPE@Y —要素的双精度 y 坐标。 SHAPE@Z —要素的双精度 z 坐标。 SHAPE@M —要素的双精度 m 值。 SHAPE@JSON — 表示几何的 Esri JSON 字符串。 SHAPE@WKB —OGC 几何的熟知二进制 (WKB) 制图表达。该存储类型将几何值表示为不间断的字节流形式。 SHAPE@WKT —OGC 几何的熟知文本 (WKT) 制图表达。其将几何值表示为文本字符串。 SHAPE@ —要素的几何对象。 SHAPE@AREA —要素的双精度面积。 SHAPE@LENGTH —要素的双精度长度。 OID@ —ObjectID 字段的值。 |
String |
| where_clause | 用于限制所返回的记录的可选表达式。有关 WHERE 子句和 SQL 语句的详细信息,请参阅 构建查询表达式。 (默认值为 None) | String |
| spatial_reference | 要素类的空间参考。可以使用 SpatialReference对象或等效字符串来指定。 (默认值为 None) | SpatialReference |
| explode_to_points | 将要素解构为单个点或折点。如果将 explode_to_points 设置为 True,则一个包含五个点的多点要素将表示为五行。 (默认值为 False) | Boolean |
| sql_clause | 以列表或组的形式列出的可选 SQL 前缀和后缀子句对。 SQL 前缀子句支持 None、DISTINCT 和 TOP。SQL 前缀子句支持 None、ORDER BY 和 GROUP BY。 SQL 前缀子句位于第一个位置,将被插入到 SELECT 关键字和 SELECT COLUMN LIST 之间。SQL 前缀子句最常用于 DISTINCT 或 ALL 等子句。 SQL 后缀子句位于第二个位置,将追加到 SELECT 语句的 where 子句之后。SQL 后缀子句最常用于 ORDER BY 等子句。 注: 仅在使用数据库时支持使用 DISTINCT、ORDER BY 和 ALL。它们不受其他数据源(如 dBASE 或 INFO 表)的支持。 TOP 仅受 SQL Server 和 MS Access 数据库的支持。 (默认值为 (None, None)) |
tuple |
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| fields (只读) | 游标使用的一组字段名称。 该组将包括由 field_names 参数指定的所有字段(和令牌)。如果 field_names 参数设置为 *,则字段属性将包括游标使用的全部字段。使用 * 时,几何值将以 x,y 坐标组返回(相当于 SHAPE@XY 令牌)。 fields 属性中字段名称的排序顺序将与 field_names 参数的传递顺序一致。 |
tuple |
方法概述
| 方法 | 说明 |
|---|---|
| next () | 将下一行作为元组返回。字段将按照创建光标时所指定的顺序返回。 |
| reset () | 将光标重置回第一行。 |
方法
next ()
返回值
| 数据类型 | 说明 |
|---|---|
| tuple | 将下一行作为元组。 |
UpdateCursor
描述
UpdateCursor 用于建立对从要素类或表返回的记录的读写访问权限。
返回一组迭代列表。列表中值的顺序与 field_names 参数指定的字段顺序相符。
说明
使用 for 循环可迭代更新游标。更新游标也支持 with 语句以重置迭代并帮助移除锁。但是,为了防止锁定所有内容,应考虑使用 del 语句来删除对象或将游标包含在函数中以使游标对象位于作用范围之外。
在 Python 2 中,UpdateCursor 支持迭代器 .next() 方法,在循环外检索下一行。在 Python 3 中,可使用 Python 的内置 next() 函数执行等效操作。
语法
UpdateCursor (in_table, field_names, {where_clause}, {spatial_reference}, {explode_to_points}, {sql_clause})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| in_table | 要素类、图层、表或表视图。 | String |
| field_names [field_names,...] | 字段名称列表(或组)。对于单个字段,可以使用一个字符串,而不使用字符串列表。 如果要访问输入表中的所有字段(栅格和 BLOB 字段除外),可以使用星号 (*) 代替字段列表。但是,为了获得较快的性能和可靠的字段顺序,建议您将字段列表限制在实际需要的字段。 不支持栅格字段。 以令牌(如 OID@)取代字段名称可访问更多的信息: SHAPE@XY —一组要素的质心 x,y 坐标。 @XYZ —一组要素的质心 x,y,z 坐标。仅当几何启用了 z 值时,才支持此令牌。 SHAPE@TRUECENTROID —一组要素的质心 x,y 坐标。这会返回与 SHAPE@XY 相同的值。 SHAPE@X —要素的双精度 x 坐标。 SHAPE@Y —要素的双精度 y 坐标。 SHAPE@Z —要素的双精度 z 坐标。 SHAPE@M —要素的双精度 m 值。 SHAPE@JSON — 表示几何的 Esri JSON 字符串。 SHAPE@WKB —OGC 几何的熟知二进制 (WKB) 制图表达。该存储类型将几何值表示为不间断的字节流形式。 SHAPE@WKT —OGC 几何的熟知文本 (WKT) 制图表达。其将几何值表示为文本字符串。 SHAPE@ —要素的几何对象 SHAPE@AREA —要素的双精度面积。 SHAPE@LENGTH —要素的双精度长度。 OID@ —ObjectID 字段的值。 |
String |
| where_clause | 用于限制所返回的记录的可选表达式。有关 WHERE 子句和 SQL 语句的详细信息,请参阅 构建查询表达式。 (默认值为 None) | String |
| spatial_reference | 要素类的空间参考。可以使用 SpatialReference对象或等效字符串来指定。 (默认值为 None) | SpatialReference |
| explode_to_points | 将要素解构为单个点或折点。如果将 explode_to_points 设置为 True,则一个包含五个点的多点要素将表示为五行。 (默认值为 False) | Boolean |
| sql_clause | 以列表或组的形式列出的可选 SQL 前缀和后缀子句对。 SQL 前缀子句支持 None、DISTINCT 和 TOP。SQL 前缀子句支持 None、ORDER BY 和 GROUP BY。 SQL 前缀子句位于第一个位置,将被插入到 SELECT 关键字和 SELECT COLUMN LIST 之间。SQL 前缀子句最常用于 DISTINCT 或 ALL 等子句。 SQL 后缀子句位于第二个位置,将追加到 SELECT 语句的 where 子句之后。SQL 后缀子句最常用于 ORDER BY 等子句。 注: 仅在使用数据库时支持使用 DISTINCT、ORDER BY 和 ALL。它们不受其他数据源(如 dBASE 或 INFO 表)的支持。 TOP 仅受 SQL Server 和 MS Access 数据库的支持。 (默认值为 (None, None)) |
tuple |
属性
| 属性 | 说明 | 数据类型 |
|---|---|---|
| fields (只读) | 游标使用的一组字段名称。 该组将包括由 field_names 参数指定的所有字段(和令牌)。如果 field_names 参数设置为 *,则字段属性将包括游标使用的全部字段。使用 * 时,几何值将以 x,y 坐标组返回(相当于 SHAPE@XY 令牌)。 fields 属性中字段名称的排序顺序将与 field_names 参数的传递顺序一致。 |
tuple |
方法概述
| 方法 | 说明 |
|---|---|
| deleteRow () | 删除当前行。 |
| next () | 将下一行作为元组返回。字段将按照创建光标时所指定的顺序返回。 |
| reset () | 将光标重置回第一行。 |
| updateRow (row) | 更新表中的当前行。 |
方法
deleteRow ()
next ()
返回值
| 数据类型 | 说明 |
|---|---|
| tuple | 将下一行作为元组。 |
reset ()
updateRow (row)
| 参数 | 说明 | 数据类型 |
|---|---|---|
| row | 值列表或组。值的顺序应与字段的顺序相同。 更新字段时,如果传入的值与字段类型匹配,则将根据需要对这些值进行转换。例如,将值 1.0 添加到字符串字段将添加为 "1.0";将值 "25" 添加到浮点型字段将添加为 25.0。 |
tuple |
游标测试代码
import arcpy, os
arcpy.CreateTable_management(os.getcwd(), "TestCursor.dbf")
in_table = os.getcwd() + os.sep + "TestCursor.dbf"
arcpy.AddField_management(in_table, "REMARKS", "TEXT", field_length=20)
# Test InsertCursor
cursor = arcpy.da.InsertCursor(in_table, "Field1")
for i in range(1, 16):
cursor.insertRow([i])
del cursor
# Test SearchCursor
field_addDelimiters = arcpy.AddFieldDelimiters(os.getcwd(), "Field1")
sql_clause = field_addDelimiters + " < 7"
print sql_clause
sum_number = 0
with arcpy.da.SearchCursor(in_table, "*", sql_clause) as cursor:
for row in cursor:
sum_number += row[1]
print "The sum of 1 to 7 is " + str(sum_number)
# Test UpdateCursor
print sql_clause
with arcpy.da.UpdateCursor(in_table, "*", sql_clause) as cursor:
for row in cursor:
print row[1]
row[2] = str(row[1]) + " is smaller than 7"
cursor.updateRow(row)
sql_clause = field_addDelimiters + " > 7"
print sql_clause
with arcpy.da.UpdateCursor(in_table, ["Field1", "REMARKS"], sql_clause) as cursor:
for row in cursor:
print row[0]
row[1] = str(row[1]) + " is bigger than 7"
cursor.updateRow(row)
运行结果
"Field1" < 7
The sum of 1 to 7 is 21
"Field1" < 7
1
2
3
4
5
6
"Field1" > 7
8
9
10
11
12
13
14
15
写入几何
使用插入和更新游标,脚本可以在要素类中创建新要素或更新现有要素。脚本可以通过创建 Point 对象、填充要素属性和将要素放入 Array 中来定义要素。然后,即可通过 Polygon、Polyline、PointGeometry 或 Multipoint 几何类使用该数组来设置要素几何。
创建点
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
arcpy.CreateFeatureclass_management(os.getcwd(), "TestCreatePoint1.shp", "POINT", spatial_reference=spatialReference)
in_fc = os.getcwd() + os.sep + "TestCreatePoint1.shp"
cursor = arcpy.da.InsertCursor(in_fc, ["SHAPE@"])
point1 = [(77.4349451, 37.5408265)]
point2 = [(77.4349451, 35.7780943)]
point3 = [(78.6384349, 35.7780943)]
point4 = [(78.6384349, 37.5408265)]
cursor.insertRow(point1)
cursor.insertRow(point2)
cursor.insertRow(point3)
cursor.insertRow(point4)
del cursor
创建多点
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
arcpy.CreateFeatureclass_management(os.getcwd(), "TestCreateMultiPoint1.shp", "MULTIPOINT",
spatial_reference=spatialReference)
in_fc = os.getcwd() + os.sep + "TestCreateMultiPoint1.shp"
cursor = arcpy.da.InsertCursor(in_fc, ["SHAPE@"])
point1 = (77.4349451, 37.5408265)
point2 = (77.4349451, 35.7780943)
point3 = (78.6384349, 35.7780943)
point4 = (78.6384349, 37.5408265)
multiPoint1 = (point1, point2)
multiPoint2 = (point3, point4)
cursor.insertRow([multiPoint1])
cursor.insertRow([multiPoint2])
del cursor
创建折线
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
arcpy.CreateFeatureclass_management(os.getcwd(), "TestCreatePolyline1.shp", "POLYLINE",
spatial_reference=spatialReference)
in_fc = os.getcwd() + os.sep + "TestCreatePolyline1.shp"
cursor = arcpy.da.InsertCursor(in_fc, ["SHAPE@"])
point1 = arcpy.Point(77.4349451, 37.5408265)
point2 = arcpy.Point(77.4349451, 35.7780943)
point3 = arcpy.Point(78.6384349, 35.7780943)
point4 = arcpy.Point(78.6384349, 37.5408265)
polyLine1 = arcpy.Polyline(arcpy.Array([point1, point2]))
polyLine2 = arcpy.Polyline(arcpy.Array([point2, point3]))
polyLine3 = arcpy.Polyline(arcpy.Array([point3, point4]))
polyLine4 = arcpy.Polyline(arcpy.Array([point4, point1]))
cursor.insertRow([polyLine1])
cursor.insertRow([polyLine2])
cursor.insertRow([polyLine3])
cursor.insertRow([polyLine4])
del cursor
创建面
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
arcpy.CreateFeatureclass_management(os.getcwd(), "TestCreatePolygon1.shp", "POLYGON",
spatial_reference=spatialReference)
in_fc = os.getcwd() + os.sep + "TestCreatePolygon1.shp"
cursor = arcpy.da.InsertCursor(in_fc, ["SHAPE@"])
point1 = arcpy.Point(77.4349451, 37.5408265)
point2 = arcpy.Point(77.4349451, 35.7780943)
point3 = arcpy.Point(78.6384349, 35.7780943)
point4 = arcpy.Point(78.6384349, 37.5408265)
polygon = arcpy.Polygon(arcpy.Array([point1, point2, point3, point4]))
cursor.insertRow([polygon])
del cursor
创建孔洞面
# -*- coding: cp936 -*-
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
arcpy.CreateFeatureclass_management(os.getcwd(), "TestCreateHollowPolygon1.shp", "POLYGON",
spatial_reference=spatialReference)
in_fc = os.getcwd() + os.sep + "TestCreateHollowPolygon1.shp"
cursor = arcpy.da.InsertCursor(in_fc, ["SHAPE@"])
point1 = arcpy.Point(77.4349451, 37.5408265)
point2 = arcpy.Point(77.4349451, 35.7780943)
point3 = arcpy.Point(78.6384349, 35.7780943)
point4 = arcpy.Point(78.6384349, 37.5408265)
point5 = arcpy.Point(77.8349451, 36.6408265)
point6 = arcpy.Point(77.8349451, 36.0780943)
point7 = arcpy.Point(78.2384349, 36.0780943)
point8 = arcpy.Point(78.2384349, 36.6408265)
# 经测试创建孔洞多边形,只需将多个闭合环组合到一起即可,而不必刻意强调内外环点顺序和内外环顺序
# 环必须闭合
hollowPolygon = arcpy.Polygon(
arcpy.Array([point1, point4, point3, point2, point1, point5, point6, point7, point8, point5]))
# polygon = arcpy.Polygon(
# arcpy.Array([point1, point2, point3, point4, point1, point5, point6, point7, point8, point5]))
# polygon = arcpy.Polygon(
# arcpy.Array([point5, point6, point7, point8, point5, point1, point4, point3, point2, point1]))
cursor.insertRow([hollowPolygon])
del cursor
创建多部件
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
arcpy.CreateFeatureclass_management(os.getcwd(), "TestCreateMultiPart1.shp", "POLYGON",
spatial_reference=spatialReference)
in_fc = os.getcwd() + os.sep + "TestCreateMultiPart1.shp"
cursor = arcpy.da.InsertCursor(in_fc, ["SHAPE@"])
point1 = arcpy.Point(77.4349451, 37.5408265)
point2 = arcpy.Point(77.4349451, 35.7780943)
point3 = arcpy.Point(78.6384349, 35.7780943)
point4 = arcpy.Point(78.6384349, 37.5408265)
point5 = arcpy.Point(78.8349451, 36.6408265)
point6 = arcpy.Point(78.8349451, 36.0780943)
point7 = arcpy.Point(79.2384349, 36.0780943)
point8 = arcpy.Point(79.2384349, 36.6408265)
polygon1 = arcpy.Array([point1, point2, point3, point4])
polygon2 = arcpy.Array([point5, point6, point7, point8])
multiPart = arcpy.Polygon(arcpy.Array([polygon1, polygon2]))
cursor.insertRow([multiPart])
del cursor
读取几何
要素类中的每个要素都包含一组用于定义面或线折点的点要素,或者包含单个用于定义一个点要素的坐标。可以使用几何对象(Polygon、Polyline、PointGeometry 或 MultiPoint)访问这些点,几何对象将以 Point 对象的数组形式返回这些点。
要素可具有多个部件。几何对象的 partCount 属性将返回要素的部分数目。如果指定了索引,则 getPart 方法将返回特定几何部分的点对象数组。如果未指定索引,则返回的数组将包含每个几何部件的点对象数组。
PointGeometry 要素将返回单个 Point 对象而不是点对象数组。所有其他要素类型(面、折线和多点)都将返回一个点对象数组,或者,如果要素具有多个部件,则返回包含多个点对象数组的数组。
如果一个面包含多个洞,它将由多个环组成。针对面返回的点对象数组将包含外部环及所有内部环的点。外部环总是先返回,接着是内部环,其中以空点对象作为环之间的分隔符。当脚本在地理数据库或 shapefile 中读取面的坐标时,它应包含用于处理内部环的逻辑(如果脚本需要此信息);否则,将只读取外部环。
多部件要素是由多个物理部分组成的,但是只引用数据库中的一组属性。例如,在州行政区图层中,可将夏威夷州看作是一个多部件要素。虽然它是由许多岛屿组成的,但在数据库中仍将其记录为一个要素。
环是一个用于定义二维区域的闭合路径。有效的环是由有效路径组成的,因而环的起点和终点具有相同的 x,y 坐标。顺时针环是外部环,逆时针环则定义内部环。
使用几何令牌
几何令牌同样可以作为快捷方式来替代访问完整几何对象。附加几何令牌可用于访问特定几何信息。访问完整几何更加耗时。如果只需要几何的某些特定属性,可使用令牌来提供快捷方式从而访问几何属性。例如,SHAPE@XY 会返回一组代表要素质心的 x,y 坐标。
| 令牌 | 说明 |
|---|---|
| SHAPE@ | 要素的几何对象。 |
| SHAPE@XY | 一组要素的质心 x,y 坐标。 |
| SHAPE@TRUECENTROID | 一组要素的质心 x,y 坐标。这会返回与 SHAPE@XY 相同的值。 |
| SHAPE@X | 要素的双精度 x 坐标。 |
| SHAPE@Y | 要素的双精度 y 坐标。 |
| SHAPE@Z | 要素的双精度 z 坐标。 |
| SHAPE@M | 要素的双精度 m 值。 |
| SHAPE@JSON | 表示几何的 Esri JSON 字符串。 |
| SHAPE@WKB | OGC 几何的熟知二进制 (WKB) 制图表达。该存储类型将几何值表示为不间断的字节流形式。 |
| SHAPE@WKT | OGC 几何的熟知文本 (WKT) 制图表达。其将几何值表示为文本字符串。 |
| SHAPE@AREA | 要素的双精度面积。 |
| SHAPE@LENGTH | 要素的双精度长度。 |
读取点
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
out_fc = os.getcwd() + os.sep + "TestReadPoint.shp"
point1 = arcpy.Point(77.434, 37.540)
point2 = arcpy.Point(77.434, 35.778)
point3 = arcpy.Point(78.638, 35.778)
point4 = arcpy.Point(78.638, 37.540)
point_list = [point1, point2, point3, point4]
pointGeometryList = []
for point in point_list:
pointGeometryList.append(arcpy.PointGeometry(point))
arcpy.CopyFeatures_management(pointGeometryList, out_fc)
arcpy.DefineProjection_management(out_fc, spatialReference)
with arcpy.da.SearchCursor(out_fc, ["SHAPE@XY"]) as cursor:
for row in cursor:
print row[0]
运行结果
(77.43408203125, 37.54010009765625)
(77.43408203125, 35.778076171875)
(78.63812255859375, 35.778076171875)
(78.63812255859375, 37.54010009765625)
读取多点
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
out_fc = os.getcwd() + os.sep + "TestReadMultiPoint.shp"
point1 = arcpy.Point(77.434, 37.540)
point2 = arcpy.Point(77.434, 35.778)
point3 = arcpy.Point(78.638, 35.778)
point4 = arcpy.Point(78.638, 37.540)
multiPoint1 = arcpy.Multipoint(arcpy.Array([point1, point2]))
multiPoint2 = arcpy.Multipoint(arcpy.Array([point3, point4]))
features = [multiPoint1, multiPoint2]
arcpy.CopyFeatures_management(features, out_fc)
arcpy.DefineProjection_management(out_fc, spatialReference)
with arcpy.da.SearchCursor(out_fc, ["OID@", "SHAPE@"]) as cursor:
for row in cursor:
print "Feature {0}".format(row[0])
for pnt in row[1]:
print pnt.X, pnt.Y
运行结果
Feature 0
77.4340820312 35.7780761719
77.4340820312 37.5401000977
Feature 1
78.6381225586 35.7780761719
78.6381225586 37.5401000977
读取折线
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
out_fc = os.getcwd() + os.sep + "TestReadPolyline.shp"
point1 = arcpy.Point(77.4349451, 37.5408265)
point2 = arcpy.Point(77.4349451, 35.7780943)
point3 = arcpy.Point(78.6384349, 35.7780943)
point4 = arcpy.Point(78.6384349, 37.5408265)
polyLine1 = arcpy.Polyline(arcpy.Array([point1, point2]))
polyLine2 = arcpy.Polyline(arcpy.Array([point2, point3]))
polyLine3 = arcpy.Polyline(arcpy.Array([point3, point4]))
polyLine4 = arcpy.Polyline(arcpy.Array([point4, point1]))
features = [polyLine1, polyLine2, polyLine3, polyLine4]
arcpy.CopyFeatures_management(features, out_fc)
arcpy.DefineProjection_management(out_fc, spatialReference)
with arcpy.da.SearchCursor(out_fc, ["OID@", "SHAPE@"]) as cursor:
for row in cursor:
print "Feature {0}".format(row[0])
for array in row[1]:
for pnt in array:
print pnt.X, pnt.Y
运行结果
Feature 0
77.4348754883 37.5408935547
77.4348754883 35.7780761719
Feature 1
77.4348754883 35.7780761719
78.6384887695 35.7780761719
Feature 2
78.6384887695 35.7780761719
78.6384887695 37.5408935547
Feature 3
78.6384887695 37.5408935547
77.4348754883 37.5408935547
读取面
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
out_fc = os.getcwd() + os.sep + "TestReadPolygon.shp"
point1 = arcpy.Point(77.4349451, 37.5408265)
point2 = arcpy.Point(77.4349451, 35.7780943)
point3 = arcpy.Point(78.6384349, 35.7780943)
point4 = arcpy.Point(78.6384349, 37.5408265)
polygon = arcpy.Polygon(arcpy.Array([point1, point2, point3, point4]))
arcpy.CopyFeatures_management(polygon, out_fc)
arcpy.DefineProjection_management(out_fc, spatialReference)
with arcpy.da.SearchCursor(out_fc, ["OID@", "SHAPE@"]) as cursor:
for row in cursor:
print "Feature {0}".format(row[0])
for array in row[1]:
for pnt in array:
print pnt.X, pnt.Y
运行结果
Feature 0
77.4348754883 37.5408935547
78.6384887695 37.5408935547
78.6384887695 35.7780761719
77.4348754883 35.7780761719
77.4348754883 37.5408935547
读取孔洞面
# -*- coding: cp936 -*-
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
out_fc = os.getcwd() + os.sep + "TestReadHollowPolygon.shp"
point1 = arcpy.Point(77.4349451, 37.5408265)
point2 = arcpy.Point(77.4349451, 35.7780943)
point3 = arcpy.Point(78.6384349, 35.7780943)
point4 = arcpy.Point(78.6384349, 37.5408265)
point5 = arcpy.Point(77.8349451, 36.6408265)
point6 = arcpy.Point(77.8349451, 36.0780943)
point7 = arcpy.Point(78.2384349, 36.0780943)
point8 = arcpy.Point(78.2384349, 36.6408265)
# 经测试创建孔洞多边形,只需将多个闭合环组合到一起即可,而不必刻意强调内外环点顺序和内外环顺序
# 环必须闭合
hollowPolygon = arcpy.Polygon(
arcpy.Array([point1, point4, point3, point2, point1, point5, point6, point7, point8, point5]))
# polygon = arcpy.Polygon(
# arcpy.Array([point1, point2, point3, point4, point1, point5, point6, point7, point8, point5]))
# polygon = arcpy.Polygon(
# arcpy.Array([point5, point6, point7, point8, point5, point1, point4, point3, point2, point1]))
arcpy.CopyFeatures_management(hollowPolygon, out_fc)
arcpy.DefineProjection_management(out_fc, spatialReference)
with arcpy.da.SearchCursor(out_fc, ["OID@", "SHAPE@"]) as cursor:
for row in cursor:
print "Feature {0}".format(row[0])
for array in row[1]:
for pnt in array:
# 因孔洞多边形会返回外环、空点对象、内环,这里采判断对象是否为空
if pnt:
print pnt.X, pnt.Y
else:
print "Empty point object!"
print "Interior Ring:"
运行结果
Feature 0
77.4348754883 37.5408935547
78.6384887695 37.5408935547
78.6384887695 35.7780761719
77.4348754883 35.7780761719
77.4348754883 37.5408935547
Empty point object!
Interior Ring:
77.8350830078 36.6409301758
77.8350830078 36.078125
78.2385253906 36.078125
78.2385253906 36.6409301758
77.8350830078 36.6409301758
读取多部件
import arcpy, os
spatialReference = arcpy.SpatialReference(4326)
out_fc = os.getcwd() + os.sep + "TestReadMultiPart.shp"
point1 = arcpy.Point(77.4349451, 37.5408265)
point2 = arcpy.Point(77.4349451, 35.7780943)
point3 = arcpy.Point(78.6384349, 35.7780943)
point4 = arcpy.Point(78.6384349, 37.5408265)
point5 = arcpy.Point(78.8349451, 36.6408265)
point6 = arcpy.Point(78.8349451, 36.0780943)
point7 = arcpy.Point(79.2384349, 36.0780943)
point8 = arcpy.Point(79.2384349, 36.6408265)
polygon1 = arcpy.Array([point1, point2, point3, point4])
polygon2 = arcpy.Array([point5, point6, point7, point8])
multiPart = arcpy.Polygon(arcpy.Array([polygon1, polygon2]))
arcpy.CopyFeatures_management(multiPart, out_fc)
arcpy.DefineProjection_management(out_fc, spatialReference)
with arcpy.da.SearchCursor(out_fc, ["OID@", "SHAPE@"]) as cursor:
for row in cursor:
print "Feature {0}".format(row[0])
partnum = 0
for part in row[1]:
partnum += 1
print "Part{0}:".format(partnum)
for pnt in part:
print pnt.X, pnt.Y
运行结果
Feature 0
Part1:
78.8350830078 36.6409301758
79.2385253906 36.6409301758
79.2385253906 36.078125
78.8350830078 36.078125
78.8350830078 36.6409301758
Part2:
77.4348754883 37.5408935547
78.6384887695 37.5408935547
78.6384887695 35.7780761719
77.4348754883 35.7780761719
77.4348754883 37.5408935547
将Python脚本改成工具
脚本编写
在脚本中声明参数变量,使用arcpy.GetParameterAsText()或者arcpy.GetParameter()函数
-
参数索引从0开始
-
无论参数的数据类型是什么,所有值都将作为字符串返回
import arcpy
in_table=arcpy.GetParameterAsText(0)
field_name=arcpy.GetParameterAsText(1)
field_type=arcpy.GetParameterAsText(2)
arcpy.AddField_management(in_table,field_name,field_type)
创建工具
1)新建工具箱(也可以使用已存在的工具箱)
在目录窗口下选择路径,新建工具箱,右键添加脚本,设置名称、标签(也可以默认),勾选相对路径名(脚本和工具箱放在同一路径下),选择脚本文件
2)设置参数
按照脚本里的参数顺序设置参数和数据类型
设置参数:
必须设置的内容:显示名称,数据类型
属性:
类型:必选&可选&派生(设置参数为必选、可选或者派生)
方向:输入&输出(输入则要求参数必须为存在的各种对象,输出则不需要)
多值:是&否(是否允许多值,如参数为字段,为多值就可选择多个字段)
默认:默认的值
环境:默认的环境
过滤器:可设置为范围&值列表
获取自:要从哪个输入获取此参数的值(如参数为字段,获取自选择输入要素)
符号系统很少用
3)编写帮助
在脚本工具上右键——项目描述——编辑——保存。
4)设置版本
在工具箱上右键——另存为,可选择Toolbox版本(注意各版本对函数和工具的支持情况)。