模块的引用: import re (py文件的命名不能与模块名字相同,错误命名如:re.py os.py abc.py)
import re
ret= re.findall('d+','周一1周二2周三3周四')
print(ret) #结果 ['1', '2', '3']
模块中的查找:
1 findall('正则表达式',文件内容):按正则表达式条件匹配所有,每一项都是列表中的元素,可直接打印.

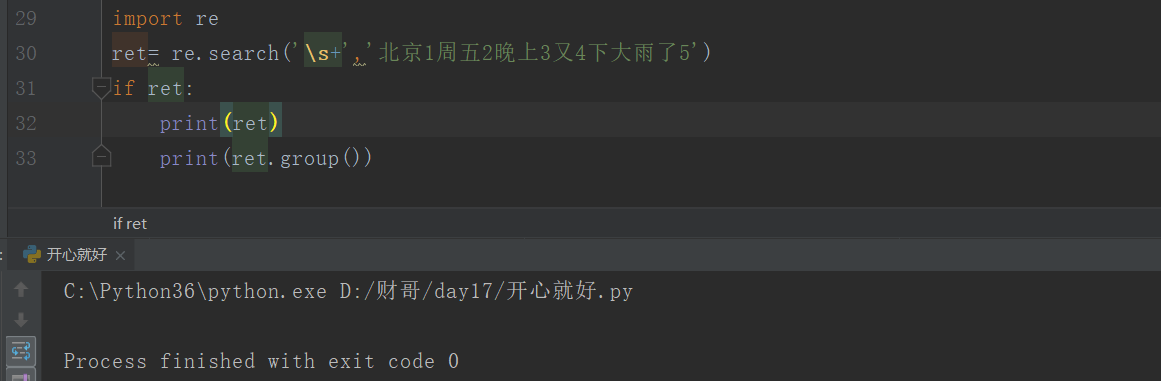
2 search(' 正则表达式',内容):按照条件匹配从左到右的第一个,得到的是一个变量,通过group()取值,,需要特别注意的是如果取不到变量返回None,通过group()取值时会报错.
正常:

特别注意:取不到变量返回None,通过group()取值时会报错.常用if条件做判断

3 match,从头开始匹配,相当于search的正则表达式中加^

模块中的切割.替换
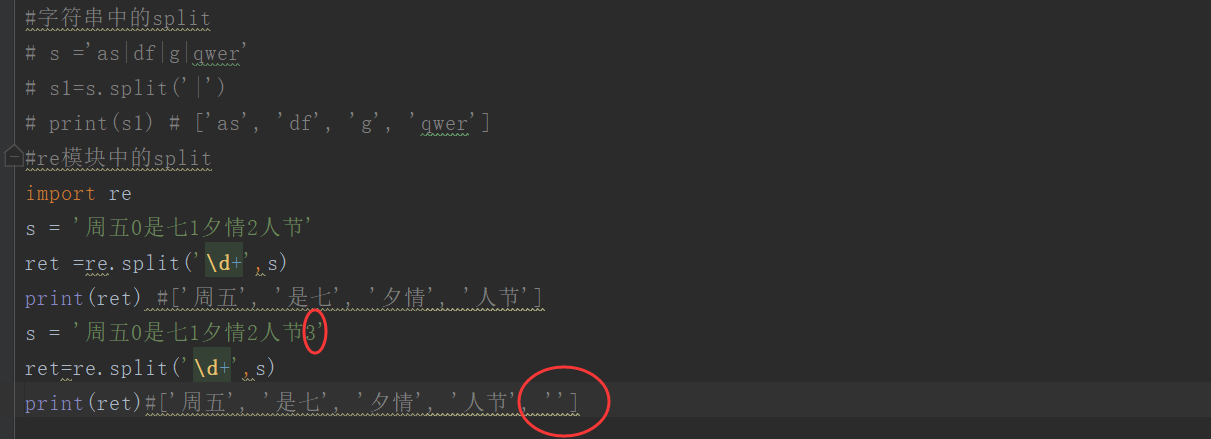
1 split:与字符串的切割相似,只不过切割条件变成了正则表达式,特别注意:如果切割条件在结尾,会出现一个空字符,
2 sub: sub('正则条件',''new",内容) 使用时 在'内容'里面按照正则条件匹配到的内容被替换成'new'
import re
ret = re.sub('d+','H','alex000是老男孩1创始人2')
print(ret) #结果为 alexH是老男孩H创始人H
3 subn:sub('正则条件',''new",内容,n) 与sub使用条件一致,只是最后会打印出替换掉的次数.
import re
ret = re.subn('d+','H','alex000是老男孩1创始人2')
print(ret)#结果为 ('alexH是老男孩H创始人H', 3)
模块的进阶:
1 compile:节省使用正则表达式解决问题的时间,先编译好直接使用(编译 正则表达式 编译成 字节码,在多次使用的过程中 不会多次编译)
import re rs=re.compile('d+') print(rs.findall('1sd212dssad212asd12')) #['1', '212', '212', '12'] print(rs.search('生活0不易1且行2且3珍惜').group()) # 0 print(rs.split('1s2sd3sdf45sd6789')) # ['', 's', 'sd', 'sdf', 'sd', ''] print(rs.sub('A','2哈哈1开心12出去浪')) # A哈哈A开心A出去浪
2 finditer:节省使用正则表达式解决问题的空间/内存
import re ret=re.finditer('d+','fi1ni2ter1') print(ret) # <callable_iterator object at 0x0000017335348978> for i in ret: print(i.group()) #结果 1 2 1
分组:即()在模块中的应用:
关于分组
# 对于正则表达式来说 有些时候我们需要进行分组,来整体约束某一组字符出现的次数
# (.[w]+)?
# 对于python语言来说 分组可以帮助你更好更精准的找到你真正需要的内容
# <(w+)>(w+)</(w+)>
findall分组:
1 为了findall可以顺利取到分组中的内容,有一个特殊语法,优先显示分组中的内容
# s = '<a>wahaha</a>'
# ret = re.findall('(w+)',s)
# print(ret)# 结果['a', 'wahaha', 'a']
# ret = re.findall('>(w+)<',s)
# print(ret) #结果 ['wahaha']
2 取消优先分组:?:正则表达式
ret = re.findall(r"d(.d+)?", "1.23*4") print(ret) ret = re.findall(r"d(?:.d+)?", "1.23*4") print(ret) 运行结果: ['.23', ''] ['1.23', '4']
search分组: group(1/2/3/...)中数字参数代表的是取对应分组中的内容,不加参数默认为0代表的是全部匹配的内容
import re
s = '<a>wahaha</a>'
set =re.search('<(w+)>''(w+)''</(w+>)',s)
print(set.group(1)) # a
print(set.group(2)) # wahaha
print(set.group(3)) # a>
print(set.group()) #<a>wahaha</a>
split分组:split应用分组时会保留切割条件
import re ret = re.split('d+','alex83taibai40egon25') print(ret) #['alex', 'taibai', 'egon', ''] ret = re.split('(d+)','alex83taibai40egon25aa') print(ret) # ['alex', '83', 'taibai', '40', 'egon', '25', 'aa']切割条件数字保留下来了
分组命名:(?P,这组的名字>正则表达式)
# s = '<a>wahaha</a>' # ret = re.search('>(?P<con>w+)<',s) # print(ret.group(1)) # wahaha # print(ret.group('con')) # wahaha # #
判断标签头尾是否一致:
s = '<a>wahaha</a>' pattern = '<(w+)>(w+)</(w+)>' ret = re.search(pattern,s) print(ret.group(1) == ret.group(3)) # True 标签开头与结尾须一致 # 使用前面的分组 要求使用这个名字的分组和前面同名分组中的内容匹配的必须一致 pattern = '<(?P<tab>w+)>(w+)</(?P=tab)>' ret = re.search(pattern,s) print(ret) #<_sre.SRE_Match object; span=(0, 13), match='<a>wahaha</a>'> 若不满足pattern条件返回None
当所取的内容没有太大的区分特点时容易和你不想匹配的内容混在一起,可以使用分组的优先取值:
import re 1 ret = re.findall(r"d+", "1-2*(60+(-40.35/5)-(-4*3))") print(ret)
2 ret =re.findall(r'd+.d+|d+','1-2*(60+(-40.35/5)-(-4*3))') print(ret)
3 ret = re.findall(r"d+.d+|(d+)", "1-2*(60+(-40.35/5)-(-4*3))") print(ret)
4 ret = re.findall(r"d+.d+|(?:d+)", "1-2*(60+(-40.35/5)-(-4*3))") print(ret)
5 ret = re.findall(r"d+.d+|(d+)", "1-2*(60+(-40.35/5)-(-4*3))") ret.remove('') print(ret) # 运行结果: 1# ['1', '2', '60', '40', '35', '5', '4', '3'] 2# ['1', '2', '60', '40.35', '5', '4', '3'] 3# ['1', '2', '60', '', '5', '4', '3'] 4# ['1', '2', '60', '40.35', '5', '4', '3'] 5# ['1', '2', '60', '5', '4', '3']