参考博客:https://www.cnblogs.com/chaosimple/archive/2013/07/31/3227271.html
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的 量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是两 种常用的归一化方法:
1、min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:

其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
2、Z-score标准化方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
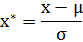
其中![]() 为所有样本数据的均值,
为所有样本数据的均值,![]() 为所有样本数据的标准差,其在取值就在(-1,1)之间.
为所有样本数据的标准差,其在取值就在(-1,1)之间.
为什么取值会在(-1,1)之间呢?
设样本为X1,X2,X3...平均值是X0 那么方差=(X1-X0)^2+(X2-X0)^2+.,因为平方是大于或等于0的数,所以每一项减去平均值的平方都要小于或者等于方差.而方差等于1 ,平均值是0,所以可以知道X1^2,X2^2,X3^3.都要小于等于1,所以取值在(-1,1)之间