Suricata
- Suricata
- 一、什么是suricata
- 二、安装
- 三、规则分析
- 四、meta关键字
- 五、IP关键字
- 六、TCP关键字
- 七、UDP关键字
- 八、Payload关键字
- 九、Prefiltering关键字
- 十、flow关键字
- 十一、Bypass关键字
- 十二、http关键字
- uri与url
- 1、http_method
- 2、http_uri/http_raw_uri
- 3、uricontent
- 4、urilen
- 5、http.protocol
- 6、http.request_line
- 7、http.header / http.header.raw
- 8、http.cookie
- 9、http.user_agent
- 10、http.accept
- 11、http.accent_enc
- 12、http.accept_lang
- 13、http.connection
- 14、http.content_type
- 15、http.content_len
- 16、http_referer
- 17、http.start
- 18、http.header_names
- 19、http.request_body
- 20、http.stat_code
- 21、http.stat_msg
- 22、http.response_line
- 23、http.response_body
- 24、http.server
- 25、http.location
- 26、http.host and http.host.raw
- 27、file_data
一、什么是suricata
Suricata是一个高性能的检测系统(IDS)、预防系统(IPS)和网络安全监控(NSM)的引擎。它是开源的,由一个社区经营的非营利基金会开放信息安全基金会(OISF)拥有。Suricata由OISF开发。
IDS/IPS
IDS:检测系统(Intrusion detection system,简称“IDS”)是一种对网络传输进行即时监视,根据预设的策略,在发现可疑传输时发出警报
IPS:预防系统(Intrusion prevention system,简称“IPS”)是一部能够监视网络或网络设备的网络资料传输行为的计算机网络安全设备,一般位于防火墙和网络的设备之间,能够即时的中断、调整或隔离一些不正常或是具有伤害性的网络资料传输行为。
IPS相对于IDS主能提供了中断防御功能。
二、安装
Ubuntu下:
sudo add-apt-repository ppa:oisf/suricata-stable
sudo apt-get update
sudo apt-get install suricata
三、规则分析
案例:
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)"; flow:established,to_server; flowbits:isset,is_proto_irc; content:"NICK "; pcre:"/NICK .*USA.*[0-9]{{3,}}/i"; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
1、action(动作)
drop为action(动作)
- pass
Suricata将停止扫描数据包并跳到所有规则的末尾(仅针对当前数据包)
- drop
这只涉及IPS/inline模式。如果程序找到匹配的包含drop的签名,它将立即停止。数据包将不再发送。缺点:接收器没有接收到正在发生的事情的消息,从而导致超时(当然是TCP)。Suricata为此数据包生成警报。
- reject
这是对数据包的主动拒绝。接收端和发送端都接收到拒绝数据包。有两种类型的拒绝数据包将被自动选择。如果有问题的数据包与TCP有关,它将是一个重置数据包。对于所有其他协议,它将是一个ICMP错误包。Suricata也会生成警报。当处于inline/ips模式时,违规数据包也将像“drop”操作一样被删除
- alert
如果签名匹配并包含alert,则该数据包将被视为任何其他非威胁性数据包,但此数据包除外,Suricata将生成警报。只有系统管理员才能注意到此警报。
2、Protocol(协议)
tcp为Protocol(协议)
TCP(用于TCP通信)
UDP协议
ICMP
ip(ip代表“all”或“any”)
应用层协议:
http
ftp
tls (this includes ssl)
smb
dns
dcerpc
ssh
smtp
imap
modbus (disabled by default)
dnp3 (disabled by default)
enip (disabled by default)
nfs (depends on rust availability)
ikev2 (depends on rust availability)
krb5 (depends on rust availability)
ntp (depends on rust availability)
dhcp (depends on rust availability)
3、源/目的地
$HOME_NET 来源地
$EXTERNAL_NET 目的地
可选参数:
../.. IP ranges (CIDR notation)
! exception/negation
[.., ..] grouping
例子:
$HOME_NET yaml配置文件中的 HOME_NET
[$EXTERNAL_NET, !$HOME_NET] 配置文件中的EXTERNAL_NET 以及非HOME_NET
! 1.1.1.1 除了1.1.1.1外的任意IP
4、port(端口)
any 为port(端口),第一个为源地址的端口,第二个为目标地址的端口
可选参数:
: 端口系列
! 除...外
[.., ..] 组内所有端口
例子:
[80, 81, 82] 端口 80, 81和 82
[80: 82] 80到82端口
[1024: ] 1024以后的端口
!80 除 80端口外
[80:100,!99] 80到100中除了99外的端口
[1:80,![2,4]] 1到80端口中除2到4的其他端口
5、direction(方向)
-> 为direction(方向)
只有方向与签名中相同的数据报才能匹配
可选参数:
source -> destination 源到目标,单向匹配
source <> destination 双向都匹配
6、其它规则参数
其他规则参数
规则的其余部分由选项组成。它们用括号括起来,用分号分隔。有些选项具有设置(例如 msg ,由选项的关键字、冒号和设置指定。其他的没有设置,只是关键字(例如 nocase )
<k>:<settings>; 有设置的规则
<k>; 无设置的规则
注意:
在suricata中,`;`和`"`都有特殊的含义,所以在规则setting中使用必须转义,使用`\`对其进行转义
例如: msg:"hhhhh;"
四、meta关键字
drop tcp $HOME_NET any -> $EXTERNAL_NET any (msg:”ET TROJAN Likely Bot Nick in IRC (USA +..)”; flow:established,to_server; flowbits:isset,is_proto_irc; content:”NICK “; pcre:”/NICK .*USA.*[0-9]{3,}/i”; reference:url,doc.emergingthreats.net/2008124; classtype:trojan-activity; sid:2008124; rev:2;)
1、msg(message)
一般,签名的第一部分都大写,并且显示签名的类型。
一般,msg都放在签名的第一部分
msg:"ET TROJAN Likely Bot Nick in IRC (USA +..)";
2、sid(signature ID)
sid给每一个签名一个id,一般放在签名的末尾处
3、rev(revision)
rev表示签名的版本。如果修改了签名,则签名编写器将增加Rev的数量。sid通常与rev一起使用
一般而言,sid在rev之前,它们是签名的最后两个
4、 gid (group ID)
gid关键字可用于为不同的签名组提供另一个ID值(如在sid中)。Suricata默认使用gid 1。可以修改这个。它将被改变是不常见的,改变它没有技术上的影响。您只能在警报中注意到它。
下面例子中,[1:2008124:2],其中1表示gid,2008124表示sid,2表示rev
10/15/09-03:30:10.219671 [**] [1:2008124:2] ET TROJAN Likely Bot Nick in IRC (USA +..) [**] [Classification: A Network Trojan was Detected] [Priority: 3] {TCP} 192.168.1.42:1028 -> 72.184.196.31:6667
5、classtype
classtype给出规则和警告的类型信息。它由一个短名称、一个长名称和一个优先级组成。对于每个类类型,classification.config都有一个优先级,该优先级将在规则中使用。
通常classtype在sid和rev之前,在其他关键字之后
drop tcp $HOME_NET any -> $EXTERNAL_NET any (......; classtype:trojan-activity; sid:2008124; rev:2;)
6、reference
引用关键字直接指向可以找到有关签名和签名试图解决的问题的信息的位置。引用关键字可以在签名中多次出现。这个关键字是为那些调查签名匹配原因的签名作者和分析人员准备的。格式如下:
reference:type,reference
e.g.
reference: url, www.info.com
reference: cve, CVE-2014-1234
7、priority(优先级)
priority关键字带有一个强制数字值,该值的范围为1到255数字1到4最常用。优先权更高的签名将首先被检查。最高优先级是1。通常签名已经通过ClassType具有优先级。这可以通过关键字优先级来克服。优先级格式为
priority:1;
8、metadata
metadata关键字允许在签名中添加其他非功能性信息。尽管没有格式要求,建议使用key value方式
metadata:key value;
metadata:key value, key value;
9、target
target关键字允许规则编写器指定警报的哪一侧是攻击的目标。如果指定,则会增强警报事件以包含有关源和目标的信息
target:src_ip;
五、IP关键字
alert ip $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL MISC 0 ttl”; ttl:0; reference:url,support.microsoft.com/default.aspx?scid=kb#-#-EN-US#-#-q138268; reference:url,www.isi.edu/in-notes/rfc1122.txt; classtype:misc-activity; sid:2101321; rev:9;)
1、ttl
TTL关键字用于检查数据包头中的特定IP生存时间值。生存时间值决定了包在Internet系统中的最大时间量。如果此字段设置为0,则必须销毁数据包。格式为:
ttl:<number>
2、ipopts
使用ipopts关键字,您可以检查是否设置了特定的IP选项。ipopts必须在规则的开头使用。每个规则只能匹配一个选项。
| IP Option | Description |
|---|---|
| rr | Record Route |
| eol | End of List |
| nop | No Op |
| ts | Time Stamp |
| sec | IP Security |
| esec | IP Extended Security |
| lsrr | Loose Source Routing |
| ssrr | Strict Source Routing |
| satid | Stream Identifier |
| any | any IP options are set |
ipopts: <IP Option>
e.g.
alert ip $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL MISC source route ssrr”; ipopts:ssrr; reference:arachnids,422; classtype:bad-unknown; sid:2100502; rev:3;)
3、sameip
每个包都有一个源IP地址和一个目标IP地址,源IP和目标IP可以相同,sameip可以检查源的IP地址是否与目标的IP地址相同
sameip
4、ipopts
https://www.osgeo.cn/suricata/rules/header-keywords.html#ip-proto
使用ip_proto关键字,您可以在包头的ip协议上进行匹配。您可以使用协议的名称或编号。
5、id
ID标识由主机发送的每个数据包,并且通常随发送的每个数据包一起递增。
IP ID用作片段标识号。每个数据包都有一个IP ID,当数据包碎片化时,该数据包的所有碎片都有相同的ID。这样,数据包的接收者就知道哪些碎片属于同一个数据包。
id:<number>;
alert tcp $EXTERNAL_NET any -> $HOME_NET any (msg:”ET DELETED F5 BIG-IP 3DNS TCP Probe 1”; id: 1; dsize: 24;......;)
6、geoip
https://suricata.readthedocs.io/en/suricata-5.0.2/rules/header-keywords.html#geoip
geoip关键字使(您)能够匹配网络流量的源、目标或源和目标IPv4地址,并查看它属于哪个国家。
geoip: src, RU;
geoip: both, CN, RU;
geoip: dst, CN, RU, IR;
geoip: both, US, CA, UK;
geoip: any, CN, IR;
7、fragbits (IP fragmentation)
使用fragbits关键字,可以检查IP头中是否设置了碎片和保留位。fragbits关键字应放在规则的开头。fragbits用于修改碎片机制。在将消息从一个Internet模块路由到另一个模块的过程中,可能会出现数据包大于网络可以处理的最大数据包大小的情况。在这种情况下,包可以以片段形式发送。
M - More Fragments
D - Do not Fragment
R - Reserved Bit
e.g.
alert tcp$external_net any->$home_net any(msg:“et exploit invalid non-fragmented packet with fragment offset>0”; fragbits: M; ......;)
8、fragoffset
使用fragoffset关键字,可以匹配IP片段偏移字段的特定十进制值。如果要检查会话的第一个片段,则必须将fragoffset 0与more fragment选项组合在一起。碎片偏移场便于重新组装。
ID用于确定哪些片段属于哪个包,碎片偏移字段澄清片段的顺序。
9、tos
TOS关键字可以匹配IP头TOS字段的特定十进制值。TOS关键字的值可以是0-255
tos:[!]<number>;
六、TCP关键字
1、seq
seq关键字可以在签名中用于检查特定的TCP序列号。序列号实际上是由TCP连接的两个端点随机生成的数字。客户机和服务器都创建了一个序列号,序列号随着发送的每个字节的增加而增加。所以两边的序列号是不同的。连接两侧必须确认此序列号。TCP通过序列号处理确认、排序和重传。它的数目随着发送方发送的每个数据字节的增加而增加。seq帮助跟踪字节所属的数据流中的位置。如果syn标志设置为1,那么数据第一个字节的序列号就是这个数字加1
2、ack
ACK是对接收到TCP连接另一端发送的所有以前(数据)字节的确认。在大多数情况下,TCP连接的每个包在第一个SYN之后都有一个ACK标志,ACK号随着每个新数据字节的接收而增加。ACK关键字可用于签名中,以检查特定的TCP确认号。
3、window
TCP窗口大小是一种控制数据流的机制。该窗口由接收器(接收器公布的窗口大小)设置,并指示可以接收的字节数。在发送方可以发送相同数量的新数据之前,接收方必须先确认此数据的大小。此机制用于防止接收器被数据溢出。
window:[!]<number>;
alert tcp $EXTERNAL_NET any -> $HOME_NET any (msg:”GPL DELETED typot trojan traffic”; flow:stateless; flags:S,12; window:55808; reference:mcafee,100406; classtype:trojan-activity; sid:2182; rev:8;)
4、tcp.mss
匹配tcp mss选项值。如果选项不存在,将不匹配
tcp.mss:<min>-<max>;
tcp.mss:[<|>]<number>;
tcp.mss:<value>;
e.g.
alert tcp $EXTERNAL_NET any -> $HOME_NET any (flow:stateless; flags:S,12; tcp.mss:<536; sid:1234; rev:5;)
5、tcp.hdr
在整个TCP头上匹配的粘性缓冲区。
alert tcp $EXTERNAL_NET any -> $HOME_NET any (flags:S,12; tcp.hdr; content:”|02 04|”; offset:20; byte_test:2,<,536,0,big,relative; sid:1234; rev:5;)
七、UDP关键字
1、udp.hdr
在整个UDP头上匹配的粘性缓冲区。
alert udp any any -> any any (udp.hdr; content:”|00 08|”; offset:4; depth:2; sid:1234; rev:5;)
八、Payload关键字
1、content
在引号之间,你可以写上你希望签名匹配的内容。
content:"......"
alert http $HOME_NET any -> $EXTERNAL_NET any (msg:"Outdated Firefox on
Windows"; content:"User-Agent|3A| Mozilla/5.0 |28|Windows|3B| ";
content:"Firefox/3."; distance:0; content:!"Firefox/3.6.13";
distance:-10; sid:9000000; rev:1;)
如果Firefox的版本不是3.6.13就会生成警告
2、nocase
不区分大小写,nocase为content的修饰符,不需要跟参数
content: "abc"; nocase; 修饰前面最近的一个content,不区分大小写
3、depth
绝对内容修饰符。它在content之后,深度内容修饰符带有一个强制的数字值
depth:3

如图,深度为3,content就无法匹配到def,只能匹配到abc
4、startswith
content的修饰符,不需要跟参数,匹配content 以...开头
startswith 不能与 depth , offset , within 或 distance 混合使用
content:"GET|20|"; startswith; 匹配内容以`GET|20|`开头
等价于
content:"GET|20|"; depth:4;offset:0;
5、endswith
content的修饰符,不需要跟参数,匹配content 以...结尾
endswith 不能和 offset, within 或 distance混合使用
content:".php"; endswith;
等价于
content:".php";isdatat:!1,relative
6、offset
offset关键字指定从哪个字节检查有效负载以查找匹配。例如,偏移量:3;检查第四个字节并进一步检查。
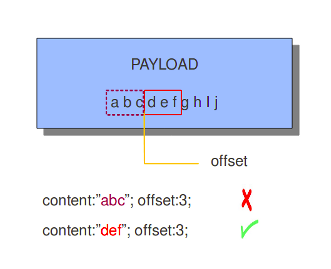
content:"def";offset:3;depth:3;
7、distance
从上一次匹配之后的任意位置开始n个字节出匹配
1)第一次匹配abc,下一次匹配起始点为c后任意个数字符

2)distance起始匹配位置c后任意个数字符,然后匹配def
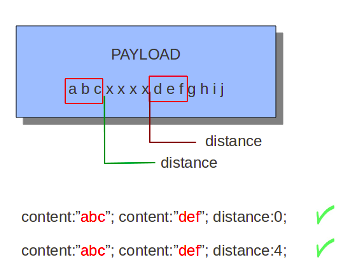
3)distance可以为负数,能够用来匹配之前的内容是否匹配

8、within
检查第二个content是否在第一个content的n距离范围内
within和distance联合使用,判断第二个content是否在第一个content+within个字节范围内
如下图所示
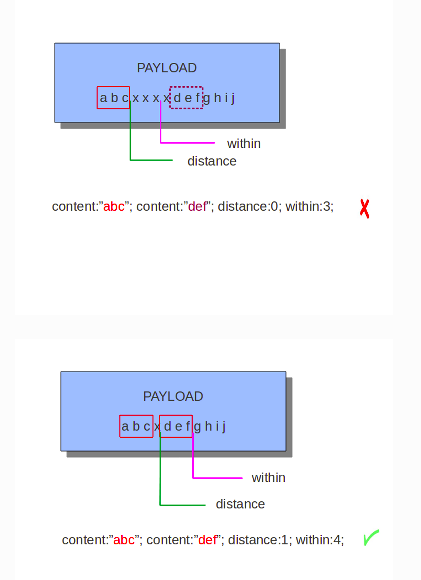
9、isdataat
查看负载的特定部分是否仍有数据
isdataat:512; # 负载的512字节位置上,时候有数据
isdataat:8,relative; # 相对一上一次匹配位置开始的n个字节上是否有数据

10、bsize
使用bsize关键字,可以匹配缓冲区的长度。这增加了内容匹配的精度,以前这可以用isdataat完成
bsize:<number>;
11、dsize
使用dsize关键字,可以匹配数据包负载的大小。
dsize:<number>;
alert udp $EXTERNAL_NET any -> $HOME_NET 65535 (msg:"GPL DELETED EXPLOIT LANDesk Management Suite Alerting Service buffer overflow"; dsize:>268; reference: bugtraq,23483; reference: cve,2007-1674; classtype: attempted-admin; sid:100000928; rev:1;)
12、byte_test
https://suricata.readthedocs.io/en/suricata-5.0.2/rules/payload-keywords.html#byte-test
byte_test:<num of bytes>, [!]<operator>, <test value>, <offset> [,relative][,<endian>][, string, <num type>][, dce][, bitmask <bitmask value>];
13、byte_jump
https://www.osgeo.cn/suricata/rules/payload-keywords.html#byte-jump
14、byte_extract
https://www.osgeo.cn/suricata/rules/payload-keywords.html#byte-extract
15、rpc
rpc(远程过程调用)是允许计算机程序在另一台计算机(或地址空间)上执行过程的应用程序。用于进程间通信。
rpc关键字可用于在sunrpc调用中匹配rpc过程号和rpc版本。用*定义的通配符可以匹配所有版本号和/或过程号。
rpc:<application number>, [<version number>|*], [<procedure number>|*]>;
16、replace

17、pcre (Perl Compatible Regular Expressions)
https://www.osgeo.cn/suricata/rules/payload-keywords.html#suricata-s-modifierss
关键字pcre匹配特定于正则表达式
pcre的复杂性带来了很高的价格:它对性能有负面影响。因此,为了减少对pcre的经常检查,pcre主要与“内容”结合使用。在这种情况下,必须先匹配内容,然后才能检查pcre。
pcre:"/<regex>/opts";
pcre: "/<regex>/i";
i 不区分大小写
s 检查换行符
m 可以使一行(有效负载)计为两行
A 模式必须在缓冲区的开头匹配
E 忽略缓冲区/负载末尾的换行符
G 反贪婪
九、Prefiltering关键字
https://www.osgeo.cn/suricata/rules/prefilter-keywords.html
1、fast_pattern
content:"Badness"; distance:0; fast_pattern;
2、prefilter
alert ip any any -> any any (ttl:123; prefilter; content:"a"; sid:1;)
十、flow关键字
1、flowbits
存在属于一个流的多个数据包,suricata会将这些信息保存在内存中。只有当两个数据包匹配时才会生成警报。因此,当第二个包匹配时,Suricata必须知道第一个包是否也是匹配的。如果一个包匹配,那么FlowBits会标记该流,因此当第二个包匹配时,它会生成一个警报。
flowbits: set, name
如果flow中存在,就会设置 条件/名字
flowbits: isset, name
可以在规则中使用,以确保当规则匹配并且在流中设置了条件时,它会生成警报
flowbits: toggle, name
反转当前设置。因此,例如,如果设置了某个条件,它将被取消设置,反之亦然。
flowbits: unset, name
可用于取消设置flow中的条件
flowbits: isnotset, name
可以在规则中使用,以确保它在匹配且flow中未设置条件时生成警报。
flowbits: noalert
此规则不会生成警报
2、flow
Flow关键字可用于匹配流的方向,例如to/from客户端或to/from服务器。它还可以匹配是否建立了流。流关键字还可以用来表示签名必须只在流上匹配(只在流上匹配)或只在包上匹配(不在流上匹配)。
to_client
在从服务器到客户端的数据包上匹配
to_server
在从客户端到服务器的数据包上匹配
from_client
在从客户端到服务器的数据包上匹配(等同于to_server)
from_server
在从服务器到客户端的数据包上匹配 (等同于to_client)
established
匹配已建立的连接
not_established
匹配不属于已建立连接的数据包
stateless
匹配属于或不属于已建立连接的数据包
only_stream
匹配流引擎重新组装的数据包
no_stream
匹配流引擎未重新组装的数据包。与重新组装的数据包不匹配
only_frag
匹配从片段中重新组装的数据包
no_frag
匹配未从片段重新组合的数据包
e.g.
flow:to_client, established
flow:to_server, established, only_stream
flow:to_server, not_established, no_frag
3、flowint
4、stream_size
十一、Bypass关键字
1、bypass
在匹配的HTTP流量上绕过流
e.g.
alert http any any -> any any (content:"suricata-ids.org"; http_host; bypass; sid:10001; rev:1;)
十二、http关键字
uri与url
<img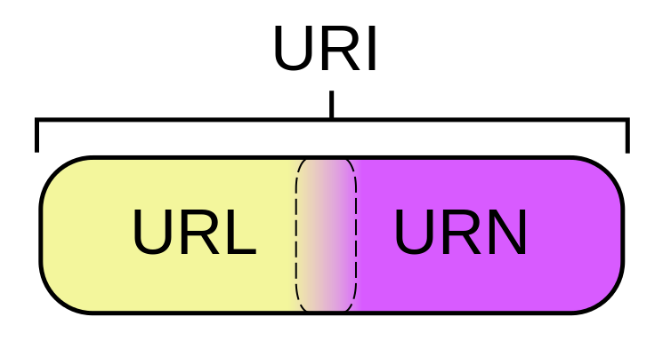
1、http_method
修饰content,表示content只能在HTTP方法缓冲区上匹配
http_method:GET, POST, PUT, HEAD, DELETE, TRACE, OPTIONS, CONNECT and PATCH
content:"GET";http_method;
2、http_uri/http_raw_uri
http_uri <===> http.uri
与 http_uri 以及 http_raw_uri 内容修饰符,可以专门匹配,并且只能在请求URI缓冲区上匹配。
URI在Suricata中有两种外观:原始URI和规范化URI。空格用十六进制%20表示这是个规范化的uri

.png)
3、uricontent
效果与http_uri相同,虽然仍然支持,但是不推荐使用。
content:"/frame.html?";http_uri
等价于
uricontent:"/frame.html?"
4、urilen
urilen用来匹配uri长度
urilen:number;

5、http.protocol
http_protocol <====> http.protocol
protocol从http请求或响应行检查协议字段。如果请求行是“GET/HTTP/1.0rn”,则此缓冲区将包含“HTTP/1.0”。
alert http any any -> any any (flow:to_server; http.protocol; content:"HTTP/1.0"; sid:1;)
6、http.request_line
http_request_line强制检查整个HTTP请求行
alert http any any -> any any (http_request_line; content:"GET / HTTP/1.0"; sid:1;)
7、http.header / http.header.raw
匹配HTTP header 缓存区所有信息,除了那些有专门文本修饰符的(http.cookie,http.method等)
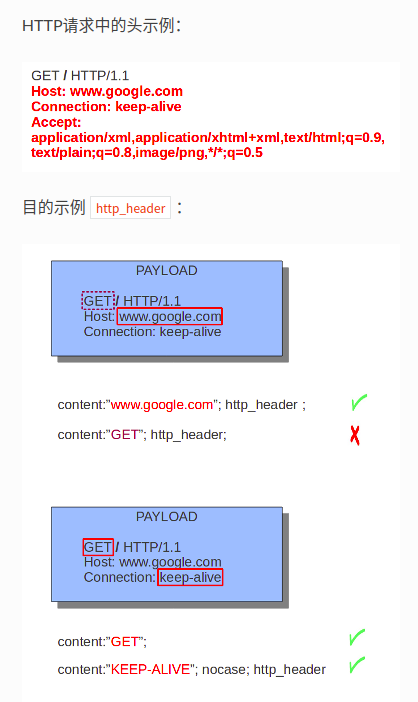
8、http.cookie
只匹配cookie缓存区,可以和 depth, distance, offset, nocase , within连用

9、http.user_agent
http.user_agent修饰符是http请求头的一部分。这使得可以在用户代理头的值上进行特定的匹配。它是标准化的,因为它不包含“User-Agent: ”、“头名称和分隔符”,也不包含尾随的回车和换行符(CRLF)。
匹配的是user-agent中的value中纯文本内容,不包括key(User-Agent: )、末尾的

注意:
http_user_agent缓冲区将不包括头名称、冒号或前导空白。即不包括“User-Agent”。http_user_agent缓冲区结尾不包含CRLF(0x0D 0x0A)。如果要匹配缓冲区的结尾,使用相对isdataat或者pcre(尽管pcre的性能会更差)- 如果一个请求包含多个“用户代理”头,这些值将在
http_user_agent缓冲区,按从上到下的顺序排列,每个缓冲区之间有逗号和空格(“,”)。
请求头:
GET /test.html HTTP/1.1
User-Agent: SuriTester/0.8
User-Agent: GGGG
匹配规则:
content:"SuriTester/0.8","GGGG";http.user_agent
- 使用
http.user_agent比使用http.header效率高约10%
10、http.accept
与HTTP Accept header匹配的粘性缓冲区。仅包含标题值。头后面的
不是缓冲区的一部分。
alert http any any -> any any (http.accept; content:"image/gif"; sid:1;)
11、http.accent_enc
与HTTP Accept-Encoding header匹配的粘性缓冲区。仅包含标题值。头后面的
不是缓冲区的一部分。
alert http any any -> any any (http.accept_enc; content:"gzip"; sid:1;)
12、http.accept_lang
与HTTP Accept-Language header匹配的粘性缓冲区。仅包含标题值。头后面的
不是缓冲区的一部分。
alert http any any -> any any (http.accept_lang; content:"en-us"; sid:1;)
13、http.connection
与HTTP Connection header匹配的粘性缓冲区。仅包含标题值。头后面的
不是缓冲区的一部分。
alert http any any -> any any (http.connection; content:"keep-alive"; sid:1;)
14、http.content_type
与HTTP Content-Type header匹配的粘性缓冲区。仅包含标题值。头后面的
不是缓冲区的一部分。
使用 flow:to_server 或者flow:to_client 区分是reuqest还是response
alert http any any -> any any (flow:to_server;
http.content_type; content:"x-www-form-urlencoded"; sid:1;)
alert http any any -> any any (flow:to_client;
http.content_type; content:"text/javascript"; sid:2;)
15、http.content_len
与HTTP Content-Length header匹配的粘性缓冲区。仅包含标题值。头后面的
不是缓冲区的一部分。
使用 flow:to_server 或者flow:to_client 区分是reuqest还是response
alert http any any -> any any (flow:to_server;
http.content_len; content:"666"; sid:1;)
alert http any any -> any any (flow:to_client;
http.content_len; content:"555"; sid:2;)
16、http_referer
要在HTTP Referer header上匹配的粘性缓冲区。仅包含标题值。头之后的
不是缓冲区的一部分。
alert http any any -> any any (http.referer; content:".php"; sid:1;)
17、http.start
检查HTTP请求/响应的的起始。
alert http any any -> any any (http.start; content:"HTTP/1.1|0d 0a|User-Agent"; sid:1;)
18、http.header_names
检查只包含HTTP头名称的缓冲区。用于确保头不存在或测试头的特定顺序。
缓冲区以 开头,以额外的 结尾
缓冲区:
\r\nHost\r\n\r\n
规范示例:
alert http any any -> any any (http_header_names; content:"|0d 0a|Host|0d 0a|"; sid:1;)
示例以确保 only 主机存在
alert http any any -> any any (http_header_names;
content:"|0d 0a|Host|0d 0a 0d 0a|"; sid:1;)
示例以确保 User-Agent 紧跟在Host后面:
alert http any any -> any any (http_header_names;
content:"|0d 0a|Host|0d 0a|User-Agent|0d 0a|"; sid:1;)
示例以确保 User-Agent 在Host之后 ,但紧跟其后:
alert http any any -> any any (http_header_names;
content:"|0d 0a|Host|0d 0a|"; content:"|0a 0d|User-Agent|0d 0a|";
distance:-2; sid:1;)
19、http.request_body
与 http.client_body 内容修饰符,可以专门匹配,并且只能在HTTP request body上匹配。

20、http.stat_code
与 http.stat_code 内容修饰符,可以专门匹配,并且只能在HTTP status code缓冲区上匹配。关键字可以与前面提到的所有内容修饰符(如 distance , offset , nocase , within 等。
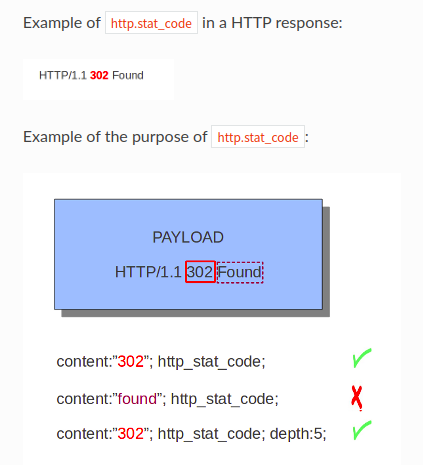
21、http.stat_msg
与 http.stat_msg 内容修饰符,可以专门匹配,并且只能在HTTP status message缓冲区上匹配。关键字可以与前面提到的所有内容修饰符(如 depth , distance , offset , nocase 和 within .

22、http.response_line
http.response_line 检查整个HTTP响应行
alert http any any -> any any (http_response_line; content:"HTTP/1.0 200 OK"; sid:1;)
23、http.response_body
与 http.response_body 内容修饰符,可以在HTTP response body进行特定匹配。关键字可以与前面提到的所有内容修饰符(如 distance , offset , nocase , within 等。
24、http.server
与 http.server 内容修饰符,可以在HTTP Server body进行特定匹配。
alert http any any -> any any (flow:to_client;
http.server; content:"Microsoft-IIS/6.0"; sid:1;)
25、http.location
与 http.server_body 内容修饰符,可以在HTTP Location headers进行特定匹配。
alert http any any -> any any (flow:to_client;
http.location; content:"http://www.google.com"; sid:1;)
26、http.host and http.host.raw
使用http.host content修饰符,可以只与规范化的hostname进行特定匹配。http.host.raw检查原始主机名。
可以与 distance, offset, within,等一起使用,但是不能与nocase一起使用
注意:
-
这个
http.host和http.raw_host缓冲区由URI(如果请求中存在完整的URI,如代理请求)或HTTP主机头填充。如果两者都存在,则使用URI。 -
这个
http.host和http.raw_host如果从主机头填充,缓冲区将不包括头名称、冒号或前导空格。也就是说,它们不包括“主机:”。 -
这个
http.host和http.raw_host缓冲区结尾不包括CRLF(0x0D 0x0A)。如果要匹配缓冲区的结尾,请使用相对的“isdataat”或PCRE(尽管PCRE的性能会更差)。 -
这个
http.host缓冲区被规范化为全部小写。 -
内容与
http.host应用于必须全部小写或具有nocase标志集。 -
http.raw_host匹配未规范化的缓冲区,因此匹配将区分大小写(除非nocase设置)。 -
如果一个请求包含多个“主机”头,这些值将在
http.host和http.raw_host缓冲区,按从上到下的顺序排列,每个缓冲区之间有逗号和空格(“,”)。请求示例:
GET /test.html HTTP/1.1 Host: ABC.com Accept: */* Host: efg.nethttp.host缓冲区内容:abc.com, efg.nethttp.raw_host缓冲区内容:ABC.com, efg.net -
相应的PCRE修改器 (
http.host):W -
相应的PCRE修改器 (
http.raw_host):Z
27、file_data
用 file_data ,检查HTTP响应主体,就像 http.server_body 。这个 file_data 关键字的工作方式与普通内容修饰符稍有不同;当在规则中使用时,规则中跟随它的所有内容匹配都会受到它的影响(修改)。
注意:
- 如果HTTP主体正在使用gzip或deflate,
file_data将匹配已解压缩的数据。 - 否定匹配受分块检查的影响。例如,‘content:!”<html”;’无法在第一个块上匹配,但可能在第二个块上匹配。要避免这种情况,请使用深度设置。深度设置会考虑到车身尺寸。假设
response-body-minimal-inspect-size大于1K,‘content:!”<html”; depth:1024;’只能在第一个检查的块中缺少模式‘<html’时匹配。 file_data也可以与SMTP一起使用