一、编码的几种常用种类
- ASCII编码
- GBK编码
- Unicode编码
二、编码的区别
-
ASCII编码
- ASCII(美国标准信息交换代码),主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
-
GBK编码
- GBK(汉字编码国家标准),GBK字符集共收录21003个汉字,包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字,对汉字采用双字节编码。
-
Unicode编码
- Unicode(国际标准字符集),它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536。
- unicode 只是一种字符码表, 而在计算机中进行存储时, 必须指定一种具体的存储方式。常见的如utf8, utf16, utf32。因为windows中,默认的unicode编码方式就是utf16, 所以英文字符才是两个字节。
-
UTF-8
- UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
- 这样做的目的解决了资源浪费。
三、编码的使用
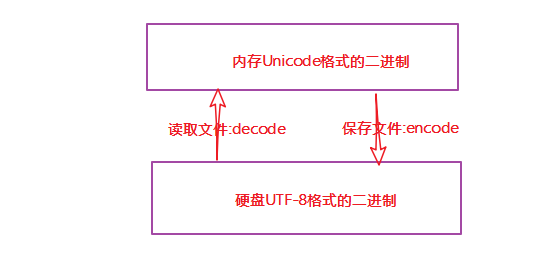
文件以什么方式保存的就以什么方式打开。
四、Python中的应用
- 在python2中,python解释器默认使用ASCII编码
- 在pythoh3中,pythin的解释器默认使用utf-8编码
- 这就是为何有的文章开头加了一句
# -*- coding: utf-8 -*-(解释器以utf-8执行文件)
五、举例
-
python2中有两种字符串类型str和unicode
- 随着python3的流行,这里就不作解释
-
python3中有两种字符串类型str和bytes
-
1 s1 = "Hello world!" 2 s2 = b"Hello world!" 3 print(type(s1)) #<class 'str'> 4 print(type(s2)) #<class 'bytes'> 5 print(s1) #Hello world! 6 print(s2) #b'Hello world!' #utf-8对于纯英文是以一个字节表示,所有进行编码后还能显示“Hello word!” -
1 s1 = "Hello world!" 2 s2 = s1.encode("utf-8") 3 print(type(s2)) #<class 'bytes'> 4 print(s2) #b'Hello world!'
#通过encode可以对str进行转换成bytes -
1 s1 = "你好,世界!" 2 s2 = s1.encode("utf-8") 3 print(type(s2)) #<class 'bytes'> 4 print(len(s2)) #18 5 print(s2) #b'xe4xbdxa0xe5xa5xbdxefxbcx8cxe4xb8x96xe7x95x8cxefxbcx81' # 在 bytes 中,无法显示为 ASCII 字符的字节,用x##显示
#len(s2),当s2为bytes类型时,len表示的是字节数,utf-8中,一个字符用3个字节表示
-