前置处理器
预处理器是JMeter的元素,在测试场景中用于执行采样器请求之前执行的操作。预处理器可用于不同的性能测试需求,例如从数据库中获取数据、在采样器执行之间或在测试数据生成之前设置超时。
1、BeanShell PreProcessor
假设我们要测试一个需要“token”参数的请求,这个参数可以是任何随机自字符串,我们可以轻松使用预处理器生成随机字符串并在采样器中使用它的一个很好的例子,BeanShell预处理器适用于此,因为它可以管理性能脚本中的任何程序员任务。
Right Click on the Sampler -> Add -> Pre Processors -> BeanShell PreProcessor
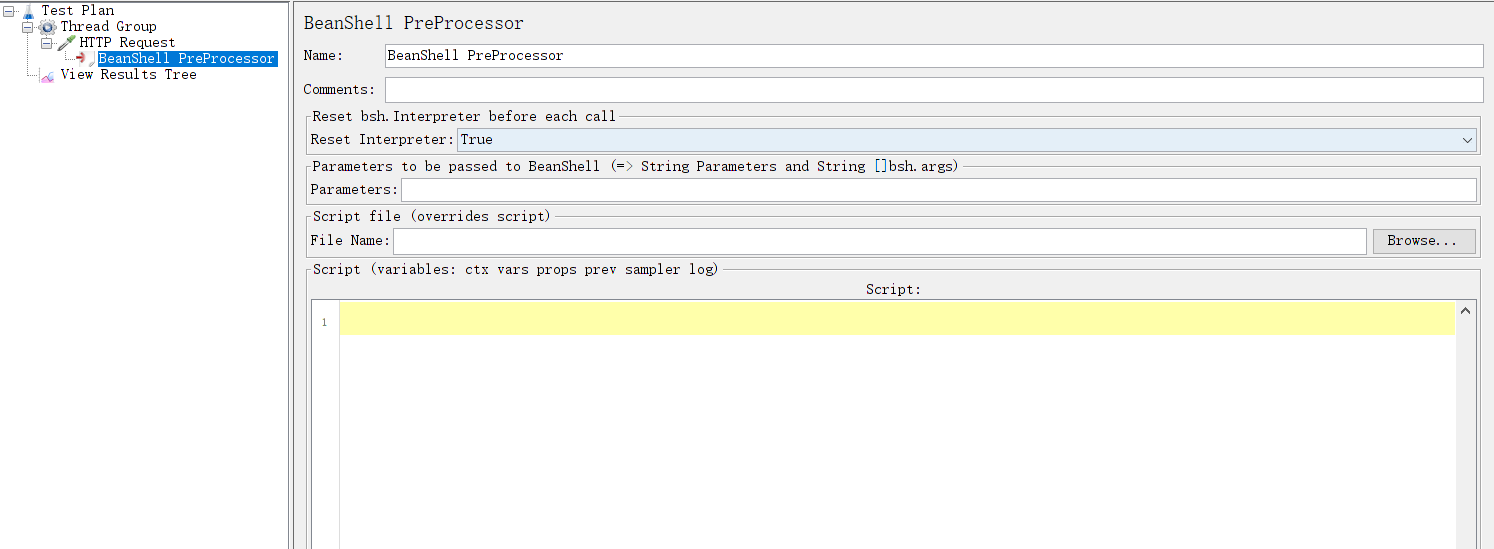
参数说明:
-
Reset bsh.Interpreter before each call: 在每次调用之前重置解释器并清除占用的内存。将此选项设置为“True”对于长时间运行的脚本可能很有用,因为重复调用可能会消耗大量内存
-
Parameters :将传递给BeanShell脚本的JMeter参数。您需要记住,如果在此配置字段中未指定JMeter变量,则不能在BeanShell预处理器中使用它们,如果指定了参数,则可以在预处理器中使用它,如下所示:
String BS_Variable_Name = vars.get("JMeterVariable"); -
File Name:需要运行的外部 BeanShell 脚本的路径
BeanShell 预处理器脚本可能是外部的,也可能是内部的。如果它是内部的,您可以将其写入 BeanShell Preprocessor 的“Script”字段。在任何其他情况下,您都需要使用“文件名”配置字段。要生成随机字符串,您可以使用这个简单的代码示例:
import java.util.Random;
chars = "1234567890abcdefghiklmnopqrstuvwxyz-";
int string_length = 36;
randomstring ="";
for (int i=0; i < string_length; i++) {
Random randomGenerator = new Random();
int randomInt = randomGenerator.nextInt(chars.length());
randomstring += chars.substring(randomInt,randomInt+1);
}
print(randomstring);
vars.put("RANDOM_STRING",randomstring);
BeanShell PreProcessor

预处理器就绪后,您现在可以使用在采样器中创建的随机脚本,
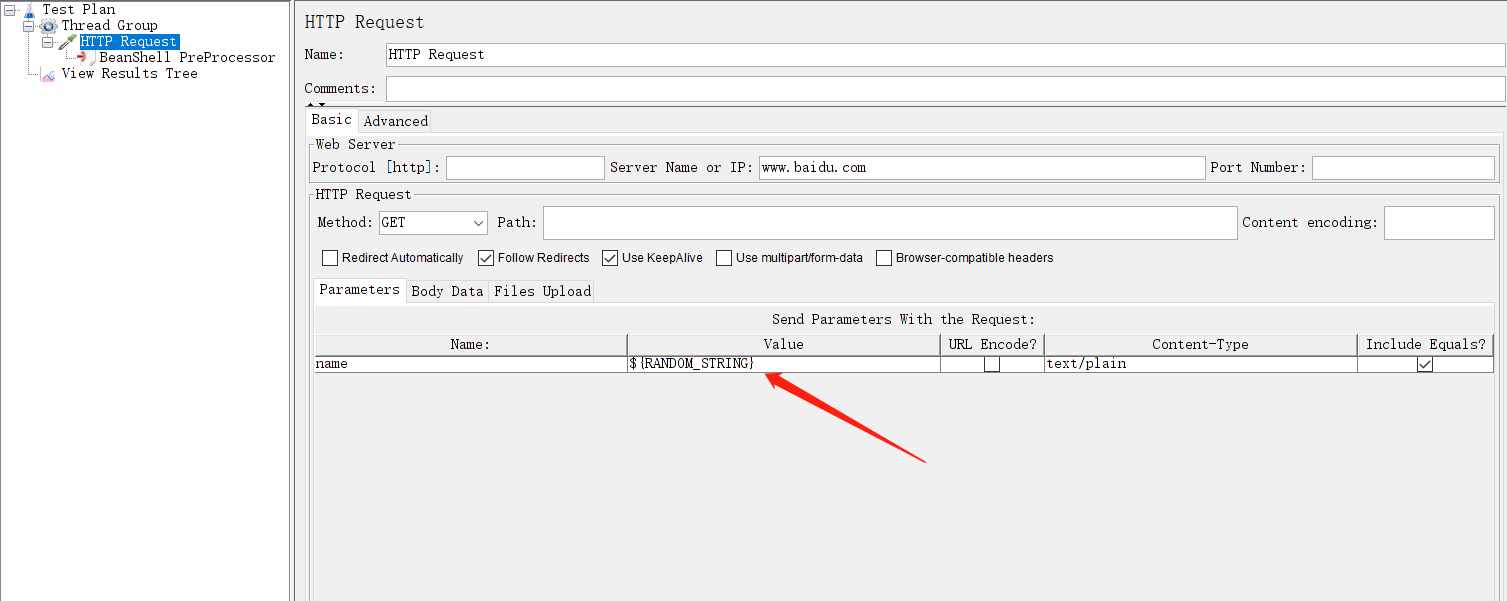
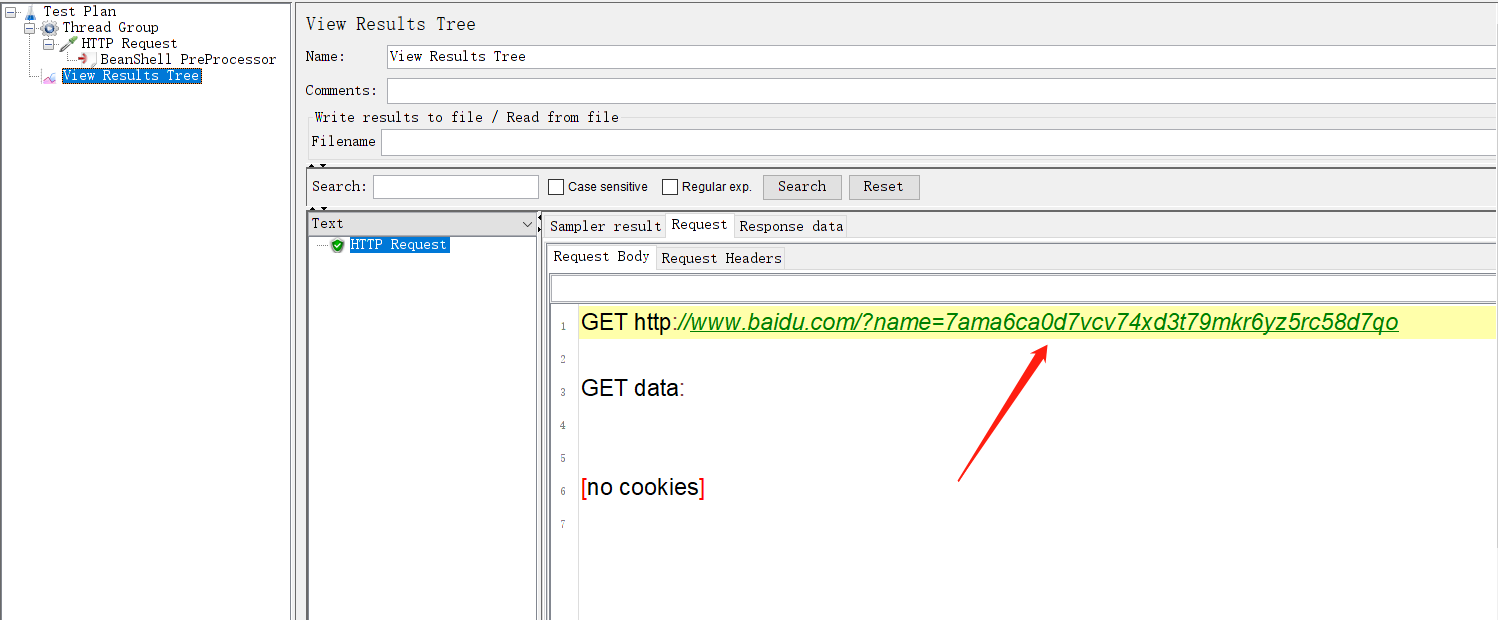
最后添加一个侦听器并验证一个发送请求,您将看到您的请求将包含一个唯一的参数
2、JSR223 PreProcessor
JSR223 预处理器是另一种使用预处理器编写脚本的方法。JSR223 具有与 BeanShell 预处理器相似的功能。与 BeanShell 的主要区别在于您可以使用其他脚本语言:ecmascript、groovy、java、javascript、jexl 和 nashorn。
使用JSR223预处理器时,您需要确保脚本不会在脚本代码中直接使用JMeter变量,因为存在一种缓存机制,该机制只缓存第一次替换,而所有下一次变量更新在预处理器中根本不可用。
To add the BeanShell PreProcessor to Sampler request:
Right Click on the Sampler -> Add -> Pre Processors -> JSR223 PreProcessor

3、HTML Link Parser
HTML 链接解析器预处理器可用于解析响应、提取所有找到的链接并进一步请求它们。当您的脚本的主要目标是模拟网络爬行时,这会很有用。
不常用
4、JDBC PreProcessor
通过使用 JDBC 预处理器,您可以在采样器之前运行 SQL 语句。
假设我们登录的过程中有用户名和密码作为参数,可以将这些测试值保留在采样器本身中,但这会非常低效,因为每次用户更新他们的用户名和密码,都必须相应地更新您的脚本。这是一个很好的例子,可以用从数据库中获取的动态值替换硬编码参数
add the JDBC PreProcessor:
Right Click on the Sampler -> Add -> Pre Processors -> JDBC PreProcessor

参数说明:
- Variable Name for created pool declared in JDBC Connection Configuration: 变量名称- 连接池的名称(在 JDBC 连接配置中指定)
- Query type: 查询类型- 所有常用的语句类型(例如,如果查询更新 db 值,则不能使用选择类型)
- SQL Query: SQL 查询- SQL 查询本身
- Parameter values: 参数值- 如果 SQL 查询参数化,则为逗号分隔的参数列表
- Parameter types: 参数类型- 逗号分隔的 SQL 参数类型列表(在此处查看有关受支持类型的更多信息:java.sql.Types 的 Javadoc)
- Variable Names: 变量名称- 以逗号分隔的变量列表,用于保留从数据库返回的获取的数据库数据值
- Result Variable Name: 结果变量名称- 包含返回数据集的键值变量
- Query timeout (s): 查询超时 (s) - 结果查询的最大秒数
- Handle ResultSet : 处理结果集 - 指定应如何处理查询结果
首先,我们需要为的数据库正确配置JDBC驱动程序。
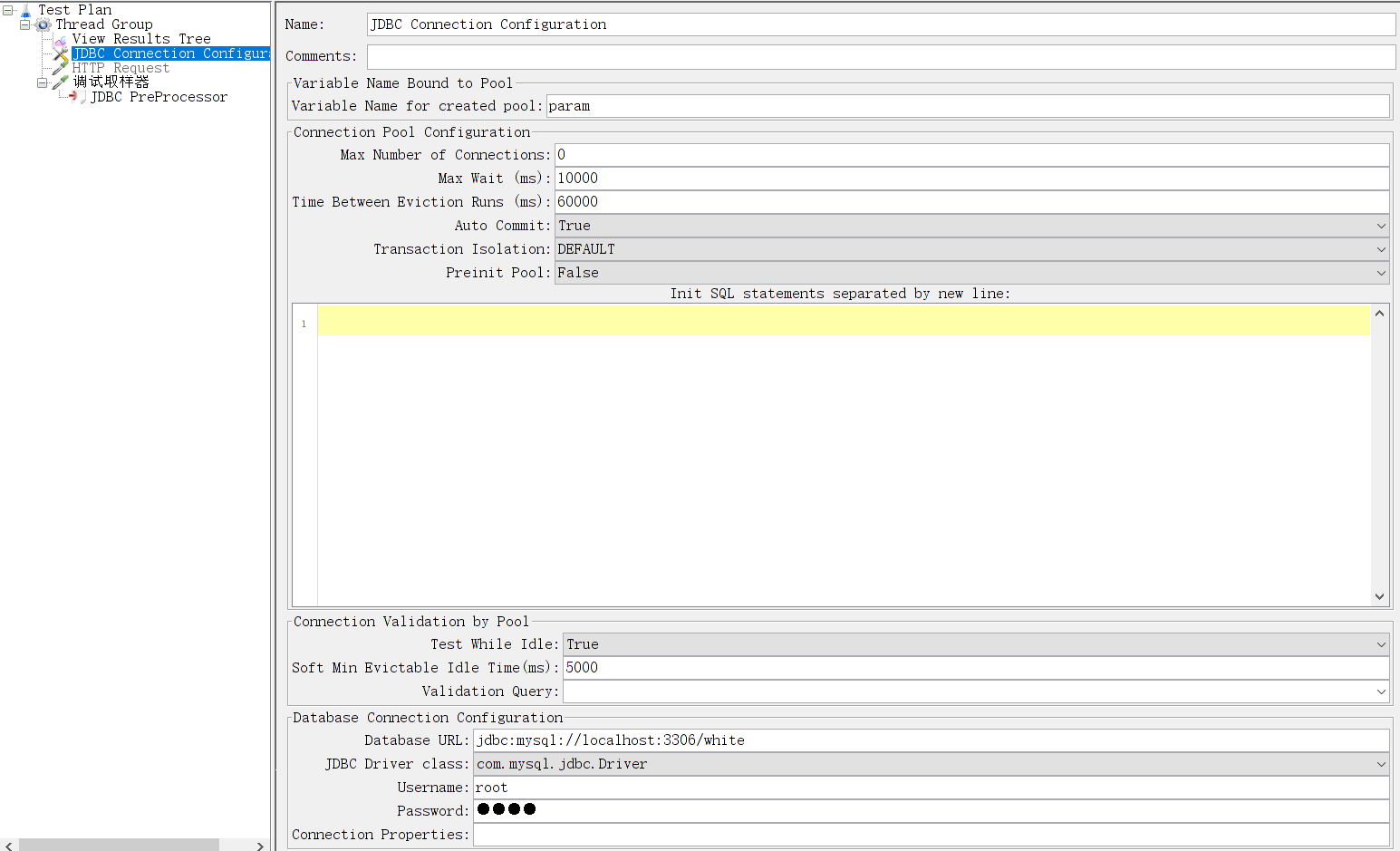
添加 JDBC 预处理器,可以只指定 Select 语句来从数据库中检索所需的数据
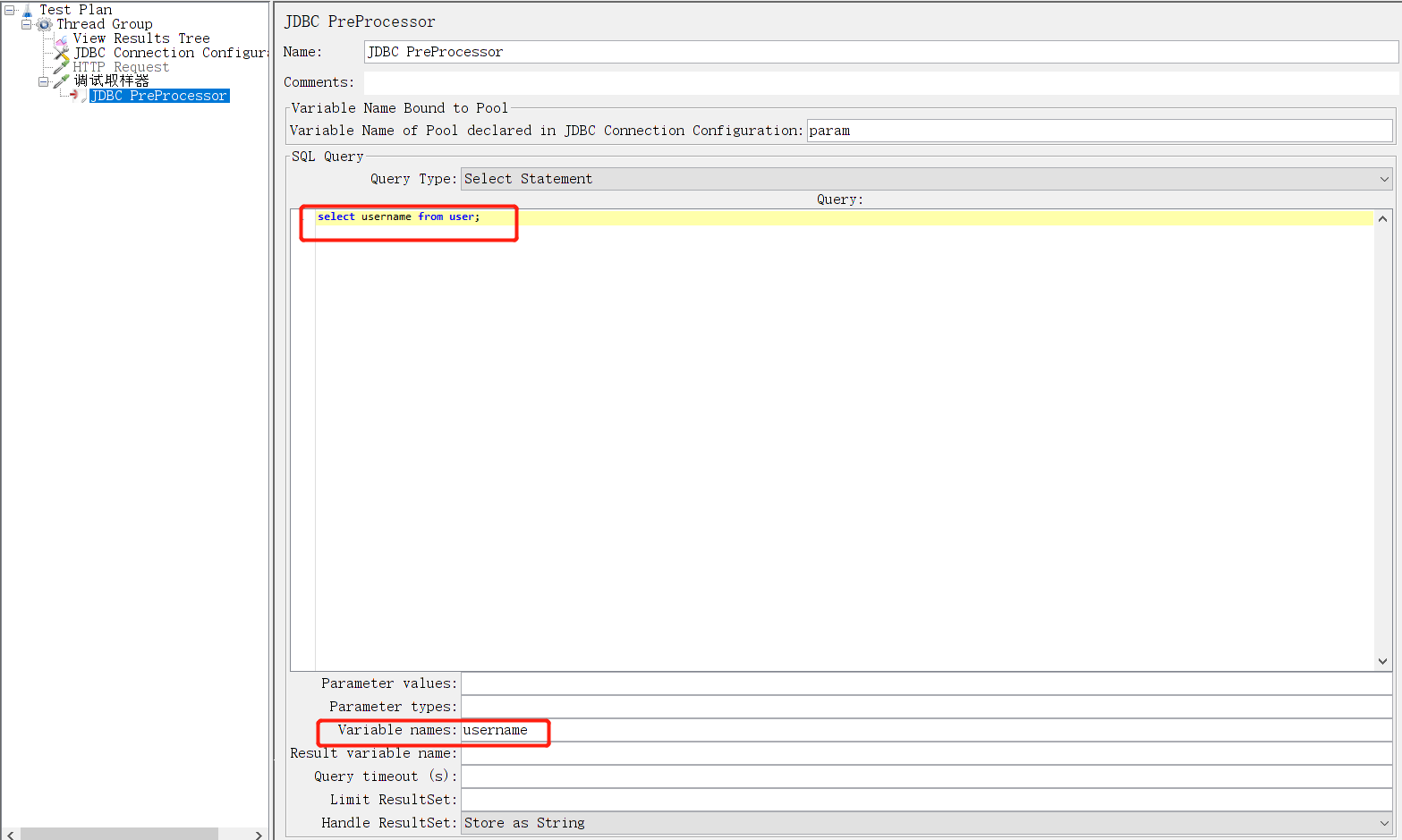
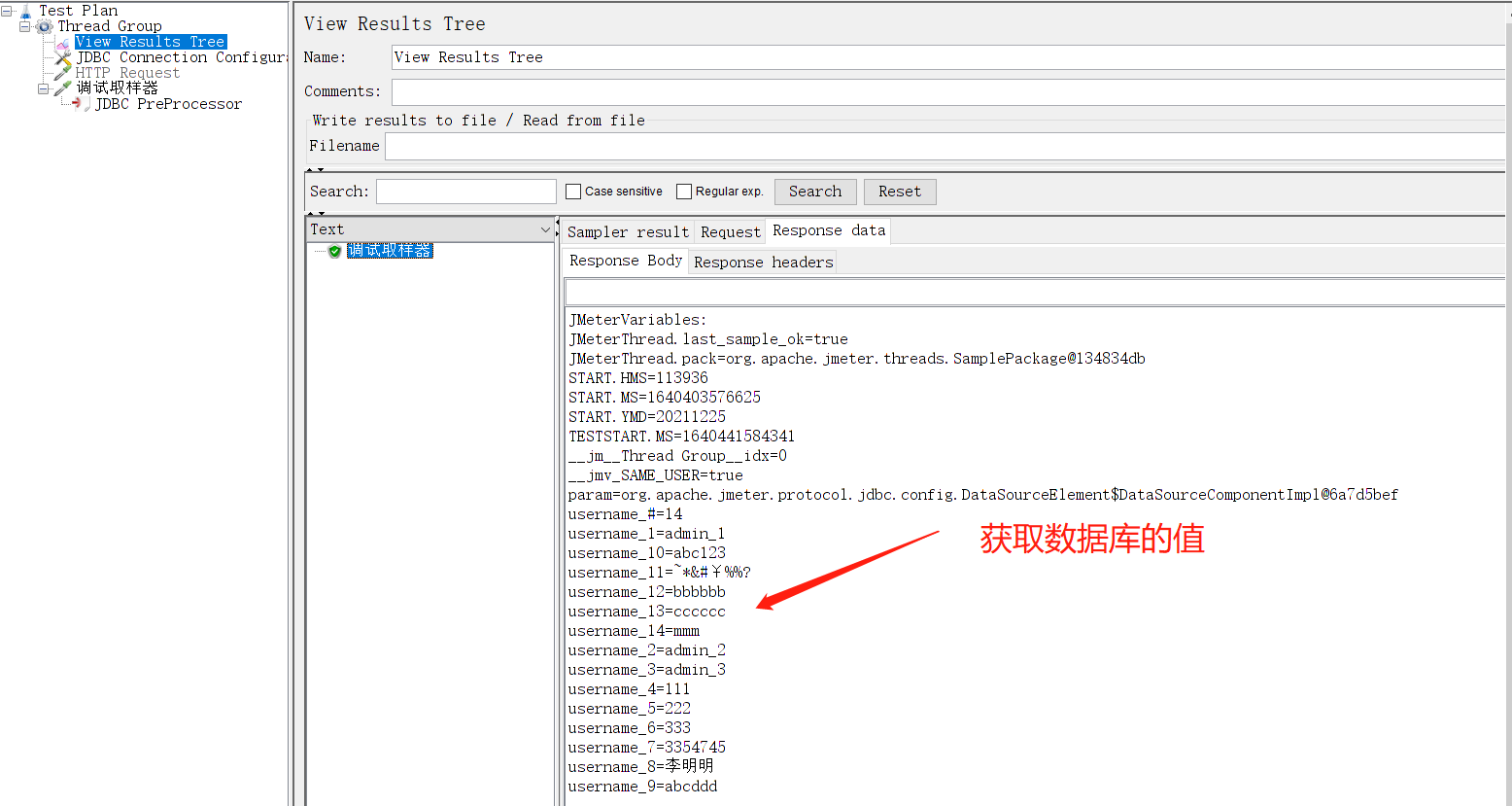
我们可以用动态获取的数据替换输入参数,这里使用调试取样器获取参数做测试。真实业务可以通过${username}获取参数值
5、RegEx User Parameters
正则表达式用户变量,用来引用前一次正则表达式提取器(Regular Expression Extractor)提取的响应数据;响应数据是由取样器返回的。比如对请求1用正则表达式提取器提取其返回list,然后请求2用RegEx User Parameters来引用list中的值
参数说明:
- Regular Expression Reference Name:正则表达式引用名称,引用的正则表达式提取器(Regular Expression Extractor)中声明的变量名
- Parameter names regexp group number:参数名称正则表达式编号
- Parameter values regex group number:参数值正则表达式组编号
假设我们有第一个 http 请求,它返回带有这种 html 的响应正文:
<div class='parameters'>
<input name='username' value='TestUser'>
<input name='password' value='Test123!'>
<div class='parameters'>
我们看到所有参数都包含名称和值。在这种情况下,我们可以创建一个通用的正则表达式来提取所有变量,包括名称和适当的值,这些变量将使用正则表达式组(圆括号)分隔:
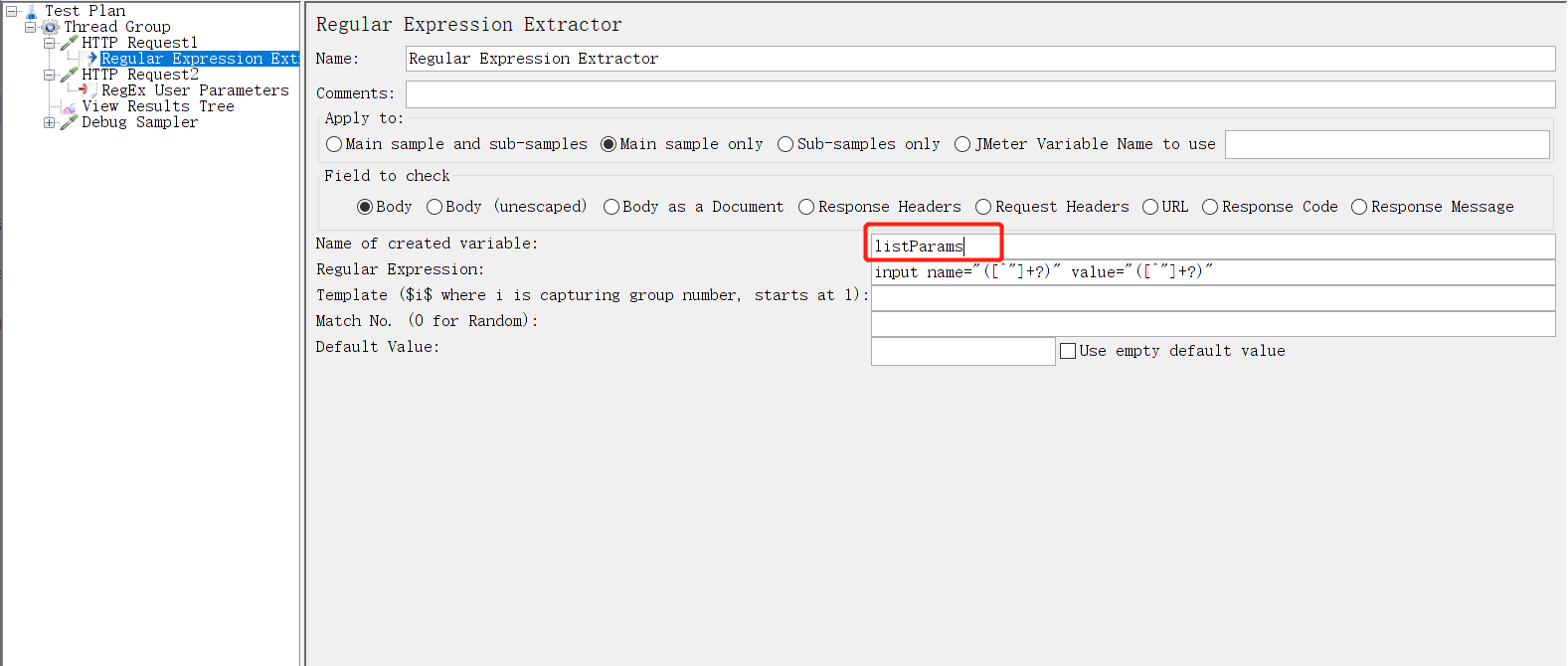
基于指定的正则表达式,我们看到 'listParams' 引用将包含从第一个请求解析的所有变量。该正则表达式的第 1 组将返回名称,而第 2 组将返回适当的值。在这种情况下,我们可以通过以下方式指定 RegEx 用户参数配置:

6、User Parameters
用户参数预处理器指定特定于各个线程的用户输入参数。对于每个线程,将根据该用户线程的顺序使用变量值.
可以利用此元件进行参数设置,在取样器中进行参数化,也就是用户(线程)在进行参数化取值时可以根据用户来区分.
如果线程数多于用户参数个数,则剩余线程从第一组用户参数开始调用
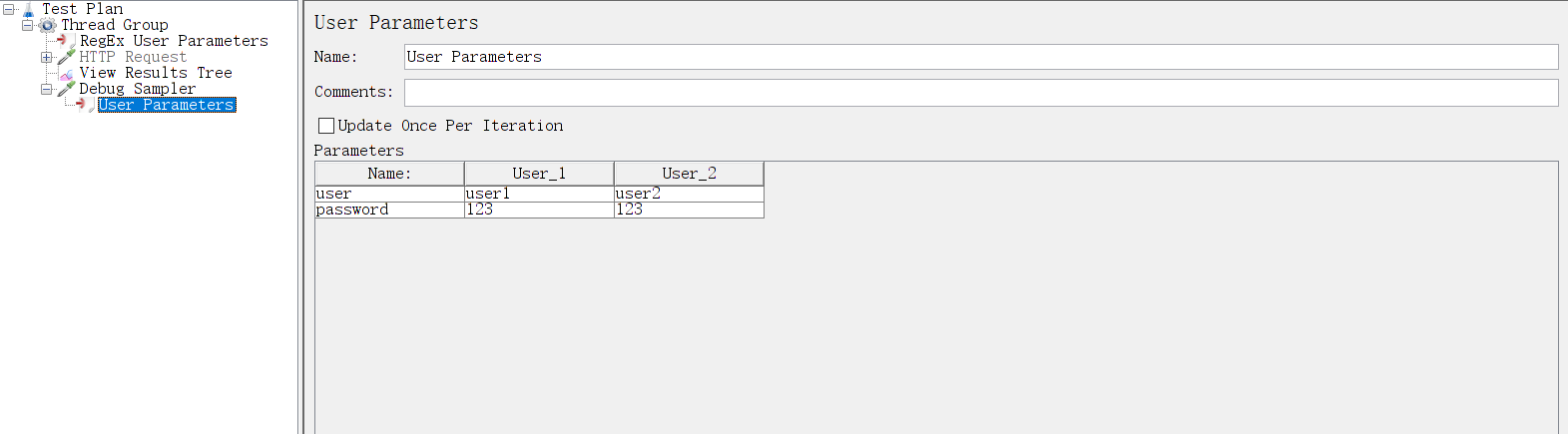
如果仅使用一次迭代更新变量并确保每次都根据父控制器的执行更新值,则需要选中“每次迭代更新一次”复选框。
通常,此预处理器是参数化请求的一种选择。但通常,csv 数据集配置元素为参数化提供了更大的灵活性。