这篇文章记录关于SQL的内容,有些凌乱,是工作中点滴的积累,只能按照时间顺序,逐次记录。
一、update 关联更新
1.需求
Table A TableB
A表中的主键和B表中的主键相关联,关联(inner join)上之后,用A表中的某字段值,去更新B表中的某个字段值。
2.环境
old_table数据:
"1","1001","lee","20181001"
"2","1002","wang","20181002"
"3","1003","song","20181003"
new_table数据:
"1","1001","lee","5"
"2","1002","lee","5"
3.sql文如下:
update new_table AS new
set new.time =
(
select old.time from old_table AS old
where new.id_1 = old.id_1
and
new.id_2 = old.id_2
and
new.time<>old.time
)
where
exists (
select 1 from old_table AS old
where new.id_1 = old.id_1
and
new.id_2 = old.id_2
and
new.time<>old.time
)
执行之后可以成功更新。
但是有一个性能问题:
里面用了exists,当new_table里的数据量很大时,性能不是很好。我用oracle测试时,new_table放了100w数据,更新成功,费时27s。
如何提升性能,暂时没想到好的方法。
二、mysql流式查询(Streaming resultSet)
当确定检索条件后,进行查询,一次查询出很多数据时,我们一般可以采用数据分页的方法,分别显示。还有一种实现方式,就是流式查询,一点点将数据放入内存中,读取,使用。具体的使用方式如下面所示(今天流式查询是一个新的思路,但是使用流式查询的场景,没有实际用过,有用过的,望赐教)。
实现方式有两种:
1 stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY, 2 java.sql.ResultSet.CONCUR_READ_ONLY); 3 stmt.setFetchSize(Integer.MIN_VALUE);
1 conn = DriverManager.getConnection("jdbc:mysql://localhost/?useCursorFetch=true", "user", "s3cr3t"); 2 stmt = conn.createStatement(); 3 stmt.setFetchSize(100); 4 rs = stmt.executeQuery("SELECT * FROM your_table_here");
具体说明呢,我给出链接,官方文档说的非常详细了。
https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-reference-implementation-notes.html
在ResultSet那部分。
三、pl/sql
1.最简单,最困难。
错误信息:PL/SQL: SQL Statement ignored
乍眼一看,肯定是变量未声明。但是,检查一圈,确实就在那里,已经声明了。弄了一下午,原来是,在数据库中,表没有被创建。。。
我的心啊!
2.dbms_output.put_line('22')
在控制台打不出信息,调查后,应该添加如下语句:SET SERVEROUTPUT ON SIZE 10000;
四、oracle 常用函数
NVL NVL2
RPAD LPAD
COALESC
五、char varchar varchar2 比较(Oracle)
给个原文出处,里面说的很详细:www.orafaq.com/faq/what_is_the_difference_between_varchar_varchar2_and_char_data_types
char :输入字符后,不满最大位数时,数据库中在后面自动补空格
varcahr、varchar2:输入字符后,不满最大位数时,数据库中在后面不会补空格。目前varchar和varchar2几乎一样,然而,varchar should not be used as it is reserved for future usage.(英文后半部分的意思没有搞明白。。。有知道的前辈,望赐教!)
六、表的复制(Oracle)
工作中测试的时候,有时是多人用一个数据库。测试时,会由于各种原因,有人将一张表进行备份,再建立一个一模一样结构的表。
原来的表 A
rename A to A_bk;
create table A as select * from A_bk where rownum<‘2’;
这样开发人员就可以快速的复制一样表结构的表。但是要注意的是,新创建的表,只是表最基本的表名、字段的属性等信息与原表一样,主键等信息没有被创建,就是由于主键的问题带来了很多的麻烦,这里要切记!
七、执行计划
在Oracle里,如何查看sql的执行计划:
① explain plan for 你要执行的sql ;
② select * from table(dbms_xplan.display)
八、常用sql
Oracle:
1.变更表名
rename A to B;
2. select itemA, count(itemA) from TableName
group by itemA
having itemA in
(select distinct(itemA) from TableName
3.建表
create table XXX as select * from tableName;
4.表解锁
SELECT
object_name,
oracle_username,
s.sid,
s.serial#,
s.logon_time,
sql_address
FROM v$locked_object l,
dba_objects o,
v$session s
WHERE l.object_id = o.object_id
and l.session_id = s.sid
and object_name = 'table_name';
ALTER SYSTEM KILL SESSION 'SID,SERIAL';
九·、ROW_NMBER() OVER (Oracle)
这个是今天干活时遇到的,第一次见。觉得挺有用,记录一下。
ROW_NMBER()是一个在group数据上,计算聚合值分析功能函数。它和别的聚合函数不同之处在于,它可以为每个group返回多条数据。这话说得有些抽象,下面看例子:
1 SELECT department_id, last_name, employee_id, ROW_NUMBER() 2 OVER (PARTITION BY department_id ORDER BY employee_id) AS emp_id --PARTITION 就是分组的意思 3 FROM employees;
执行结果:

我相信,看完例子之后,大家心里能了解它的作用了。
接下来,再小小修改一下:
1 SELECT department_id, last_name, employee_id, ROW_NUMBER() 2 TO_CHAR( OVER (PARTITION BY department_id ORDER BY employee_id), 'FM09' ) AS emp_id --加上红字后,自己再跑跑,看看结果的样式有什么变化 3 FROM employees;
参考文章:
https://docs.oracle.com/cd/E11882_01/server.112/e41084/functions004.htm#SQLRF06174
https://gerardnico.com/db/oracle/row_number
十、SQL执行顺序
了解它的执行顺序有什么用?可以在编写过程中,避免一些问题。比如下面sql:
1 select A.name AS stu_name 2 from table A 3 group by stu_name;
执行时会报错,group by 的stu_name,找不到。原因在于下面的sql执行顺序。
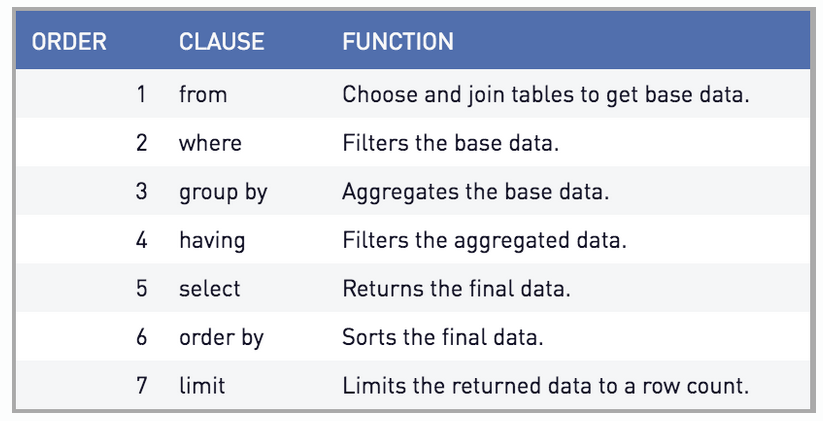
图片出处:https://www.periscopedata.com/blog/sql-query-order-of-operations
当group by 的时候,还未执行select操作,所以自然就不知道字段的别名了。
十一、sql行转列
表中的数据:

变化后的数据:

sql写法如下:
SELECT name,
SUM(CASE `Type` WHEN 'salary' THEN Amount ELSE 0 END) as 'salary',
SUM(CASE `Type` WHEN 'bonus' THEN Amount ELSE 0 END) as 'bonus'
FROM salary
GROUP BY name;
To be continued...