简单的描述就是一个字典树, 我们用下图来简单描述一下。
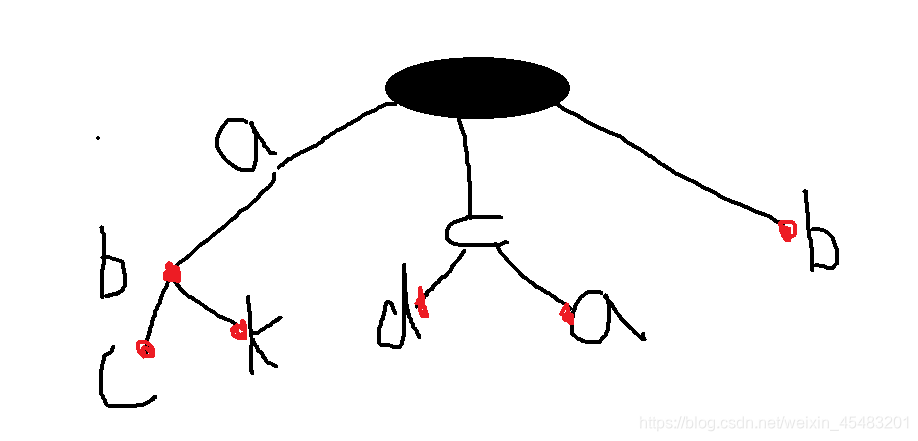
上述的字典树代表着
ab
abc
abk
cd
ca
b
这六个单词,我们不难发现其中标记是红色的代表从一个伪根节点到这是一个完整的单词。不同的单词有重复的部分,例如accepted,accept。
下面是建树代码。
其中tree[ i ][ j ]数组的意思是,以 i j 为父节点的子节点的一个下标,另一个下标就是节点的value,通常就是字母的值。
const int N = 1e6 + 10;
int tree[N][26], tot;
bool is_word[N];
char str[N];
void build_tree() {
int root = 0;
int n = strlen(str);
for(int i = 0; i < n; i++) {
if(!tree[root][str[i] - 'a']) tree[root][str[i] - 'a'] = ++tot;
root = tree[root][str[i] - 'a'];
}
is_word[root] = true;//这个点结束的单词的个数。
}
我们把上面的树在数组中打印下来。
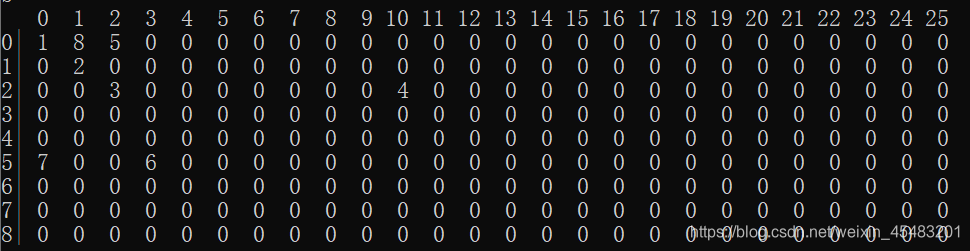
我们可以模拟一遍上面的数组到底是如何形成的,这样有助于方便理解。
其实一开始我也搞不懂到底这样为什么可以,后面自己模拟一下自然就懂了。
字典树建好了,接下来就是查找字典里有没有出现过某个单词了。
const int N = 1e6 + 10;
int tree[N][26], tot;
bool is_word[N];
char str[N];
bool find_word() {
int root = 0, ans = 0;
int n = strlen(str);
for(int i = 0; i < n; i++) {
root = tree[root][str[i] - 'a'];
if(!root) return false;//如果有一个字母是没有出现的自然就是查找失败了。
}
return is_word[root];//再次判断,查找的单词是否只是字典里的一个单词的字串。
}
一道水题
前缀统计
给定N个字符串S1,S2…SN,接下来进行M次询问,每次询问给定一个字符串T,求S1~SN中有多少个字符串是T的前缀。
输入字符串的总长度不超过106,仅包含小写字母。
输入格式
第一行输入两个整数N,M。
接下来N行每行输入一个字符串Si。
接下来M行每行一个字符串T用以询问。
输出格式
对于每个询问,输出一个整数表示答案。
每个答案占一行。
输入样例:
3 2
ab
bc
abc
abc
efg
输出样例:
2
0
#include<iostream>
#include<cstring>
#include<cstdio>
using namespace std;
const int N = 1e6 + 10;
int tree[N][26], tot, num_tree[N];
char str[N];
void build_tree() {
int root = 0;
int n = strlen(str);
for(int i = 0; i < n; i++) {
if(!tree[root][str[i] - 'a']) tree[root][str[i] - 'a'] = ++tot;
root = tree[root][str[i] - 'a'];
}
num_tree[root]++;
}
int find_sub() {
int root = 0, ans = 0;
int n = strlen(str);
for(int i = 0; i < n; i++) {
root = tree[root][str[i] - 'a'];
if(!root) return ans;
ans += num_tree[root];
}
return ans;
}
int main() {
int n, m;
scanf("%d %d", &n, &m);
for(int i = 0; i < n; i++) {
scanf("%s", str);
build_tree();
}
for(int i = 0; i < m; i++) {
scanf("%s", str);
printf("%d
", find_sub());
}
return 0;
}