一.前言(Hash table)
1.红黑树具有lgN的性能保障,能否做得更好?
可以,但是需要一种不同的获取数据的方式,并且不能保证有序操作。即散列表
2.几个需要思考的问题:
(1)散列函数的计算
(2)相等测试。可以使用equals来判断两个key是否相等
(3)碰撞冲突。两个键散列以后具有相同的数组索引。(解决方法:拉链法和线性探测法)
3.散列表是时间和空间权衡(space-time tradeoff)的经典例子。
(1)如果没有空间限制,可以将每个key作为散列表的索引
(2)如果没有时间限制,将所有的key散列到同一个地方,然后可以使用无序数组进行顺序查找
(3)时间和空间均有限:hashing
二.散列函数 hash function
1.期望:(1)易于计算(2)能够均匀分布所有键(即每个表索引对于每个键都是相同的,等概)
2.对于一些数据类型:Integer,Double,String,File,URL,Date,..已经内置有hash函数的实现,并且hascode()和equals()方法一致。
例如:Integer简单的返回自己,Boolean返回2种不同的数字,String返回hash=s[i]+(31*hash);即s[0]*31L-1+...+s[L-2]*311+s[L-1]*310
3.自定义散列函数


package com.cx.serch; public class Transaction { private String who; private Date when; private double amount; public int hashCode() { int hash=17; hash=31*hash+who.hashCode(); hash=31*hash+when.hashCode(); hash=31*hash+((Double)amount).hashCode(); return hash; } }
4.将hashCode的返回值转化为一个数组索引
(1)HashCode.int类型是-231和231-1之间
希望转化为0到M-1之间,使用数组的索引
(2)一种可能的尝试:
private int hash(Key key) { return Math.abs(key.hashCode())%M; }
但是231会出现bug
(3)使用位与,屏蔽符号位
private int hash2(Key key) { return (key.hashCode() & 0x7fffffff) %M; }
5.均匀散列假设:我们使用的散列函数能够均匀并独立地将所有的键散布在0到M-1之间
三.基于拉链法的散列表 (separate chaining)
1.使用数组和linked-list。
(1)Hash:将key散列到0-M-1的数组
(2)插入:放在第i条链路的前面
(3)查询:只需要搜索第i条链路
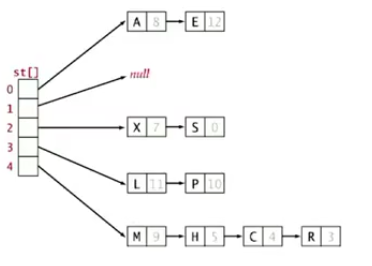
2.代码实现
package com.cx.serch; public class SeparateChainingHashST<Key,Value>{ //chain的数量 private int M=97; //存放chain的数组 private Node[] st=new Node[M]; private static class Node{ private Object key; private Object value; private Node next; private Node(Object key, Object value, Node next) { this.key = key; this.value = value; this.next = next; } } private int hash(Key key) { return (key.hashCode() & 0x7fffffff)%M; } //只用在一条链路上查找 public Value get(Key key) { int i=hash(key); for(Node x=st[i];x!=null;x=x.next) if(key.equals(x.key)) return (Value)x.value; return null; } //在一条链路上查找,存在则替换,不存在则 public void put(Key key,Value value) { int i=hash(key); for(Node x=st[i];x!=null;x=x.next) if(key.equals(x.key)) { x.value=value; return;} //放在链路的最前面 st[i]=new Node(key,value,st[i]); } }
3.说明:
(1)任意链表的key的数量为N/M的概率趋近于1.
(2)将一个查找N个元素的问题转化为查找N/M个元素的问题
(3)一般选择:N/M=5,可以保证常数时间完成查找/插入。
四.基于线性探测法的散列表 (linear probing)
1.基本思想:利用大小为M的数组保存N个键值对,其中M>N(前提),使用数组中的空位解决碰撞冲突。称为开放地址散列表。
2.散列:将key散列到0到M-1之间
3.插入:如果可以的话,放在第i个位置,如果已有元素,尝试i+1,i+2..如果到达末尾,则折回数组的开头。
4.查找:查找第i个位置,看是否匹配,如果不匹配,接着看i+1,i+2,,直到匹配或者到达下一个空位。
5.算法实现:有技巧性
package com.cx.serch; public class LinearProbingHashST<Key,Value>{ //数组的大小 private int M=30001; private Value[] values=(Value[]) new Object[M]; private Key[] keys=(Key[]) new Object[M]; private int hash(Key key) { return (key.hashCode() & 0x7fffffff)%M; } //放在第i个位置,如果已有元素,尝试i+1,i+2...,到达数组末尾,折回开头 public void put(Key key,Value value) { int i; //(i+1)%M可以保证上述操作 //keys[i]!=null表示i位置已有元素 for(i=hash(key);keys[i]!=null;i=(i+1)%M) { if(keys[i].equals(key)) {values[i]=value; return;} } //表示在空位置插入 keys[i]=key; values[i]=value; } //在第i个位置查找,如果无元素返回null,如果有元素判断是否相等,如果不相等,i++,直到到达下一个空位或匹配 public Value get(Key key) { for(int i=hash(key);keys[i]!=null;i=(i+1)%M) { if(keys[i].equals(key)) return values[i]; } return null; } }
6.说明:
(1)如果M过大,会有太多的空位置;如果M太小,查找时间会大大增加
(2)一般选择M/N=2。此时,查找成功大约在3/2次,没查找到/插入大约在5/2次。保持数组在半满状态,需要动态的调整数组的大小。
(3)线性探测法,类似于日常生活中,在一条街道上停车。
(4)拉链法和线性探测法的前提都是能够均匀分布所有键(uniform hashing assumption)
(5)上面(4)的这种前提不像快速排序那样可以由开发者避免(shuflling),如果恶意攻击者知道你的hash函数,全部插入hash值相同的元素,这将会使得性能非常的差,使用这两种方法只能期望均匀分布。
而这种情况使用红黑树就比较好,因为它由lgN的性能保障。
(6)对于(5)这种情况,可以使用一些加密算法,对key进行加密,使得攻击者无法轻易的找到hash值相同的key来恶意攻击。例如MD4,MD5,SHA-0,SHA-1。。。
但是这对于符号表来说,开销过大。

7.拉链法和线性探测法的对比
(1)拉链法:
①容易实现删除
②对于不好的hash函数,簇不是很敏感
③performance degrades gracefully
(2)线性探测法:
①空间浪费少
②有更好的缓存性能
8.散列表和平衡查找树的对比
hash table:
(1)代码容易
(2)对于无序key,不需要改变
(3)对于简单的key更快
(4)像String等已有较好hash的java实现更方便。
balanced search tree:
(1)更强的性能保障,不需要有任何假设的前提
(2)支持有序的符号表操作
(3)compareTo()的实现比equals()和hashCode()更容易
在java系统都都有实现:
(1)红黑树:java.util.TreeMap,java.util.TreeSet
(2)散列表:java.util.HashMap,java.util.IdentityHashMap