Kafka消息系统
kafka是什么:

分布式MQ系统,每秒可以生产约25万消息,每秒处理55万消息
设计目标:
分布式,基于发布订阅的消息系统
以时间复杂度为o(1)的方式提供消息持久化能力
高吞吐率
支持消息分区,分布式消费
支持离线数据处理和实时数据处理
支持在线水平扩展
特点:
高性能 持久:直接持久化到磁盘,数据也会顺序性 分布式
kafka数据会复制到其他机器上,当一台失效时生产者和消费者用其他机器
kafka在生态圈中的位置
kafka系统架构:
生产者将消息发送给以Topic命名的消息队列Queue,消费者订阅发往某个Topic命名的消息队列Queue中的信息,其中kafka集群由若干个Broker组成
Topic由若干个Partition组成 每个Partiton里面的消息通过offset来获取
Broker:
一台kafka服务器就是一个Broker,一个集群由多个Broker组成
一个Broker可以容纳多个Topic,Broker和Broker之间没有Master和Standby的概念,他们之间的地位基本是平等的
TOPIC:
每条发送到kafka集群的消息都属于某个主题,这个主题就是Topic,物理上不同topic的消息分开存储,逻辑上一个topic的消息虽然保存在一个或多个Broker上,但是用户只需指定消息的主题Topic即可生产或者消费数据,而不需要关心数据存放在何处
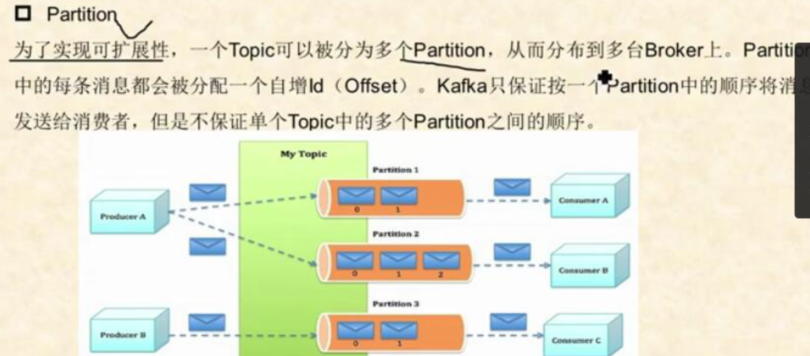
一个topic可以被分为多个partition,从而分布到多台Broker,partition
中的每条消息都会被分配到一个自增ID(offset),kafka只保证按一个partition中的顺序将消息发送给消费者,但是不保证单个topic中的多个partition之间的顺序

Replica
副本:topic的partition含有N个副本,N为副本因子。其中一个Replica为Leader,其他都为Leader Leader会处理Partition的读写请求,与此同时,follower会定期去同步leader上的数据
Message
消息,是通信的基本单位,每个生产者可以向一个topic发布一些消息
生产者:
将消息发布到指定的topic中,同时生产者也能决定此消息所属的partition
比如基于Round-Robin轮询的方式或者哈希方式一些算法
消费者:
根据指定topic的分区索引及其对应分区及其对应的分区上的消息偏移量来获取信息
消费者组
每个消费者属于一盒消费者组,反过来,每个消费者组可以包含多个消费者。如果所有的消费者都具有相同的消费者组,那么消息将会在消费者之间进行负载均衡,也就是说一个partition中的消息只会被相同消费者组中的某个消费者消费,每个消费者组消息消费是相互独立的,但是每个消费者内部不是独立的
一个分区只能被一个消费者消费,但是一个消费者可以消费多个分区
kafka拓扑结构:
:
生产者可以是某个模块下发的命令,或者是web前端产生的pageview 或者是服务器日志
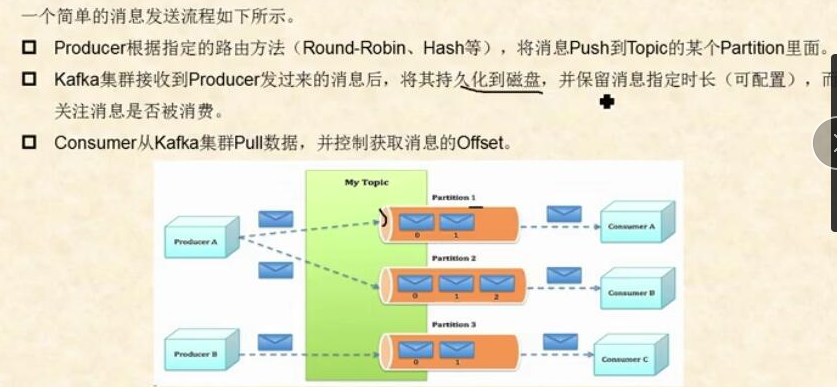
生产者通过push模式将消息发布到Broker上,消费者通过pull模式从broker上订阅并消费消息
zookeeper管理协调kafka代理
