首先导入相关模块
1 import pandas as pd 2 from pandas import Series,DataFrame 3 import numpy as np
一、Series
Series是一种类似与一维数组的对象,由下面两个部分组成:
values:一组数据(ndarray类型)
index:相关的数据索引标签
1、Series的创建
两种创建方式: (1) 由列表或numpy数组创建 默认索引为0到N-1的整数型索引
#使用列表创建Series
1 Series(data=[1,2,3,4,5]) 2 3 0 1 4 1 2 5 2 3 6 3 4 7 4 5 8 dtype: int64
# 使用numpy创建Series
# 可以通过设置index参数指定索引
1 Series(data=np.random.randint(1,40,size=(5,)),index=['a','d','f','g','t'],name='bobo') 2 3 a 3 4 d 22 5 f 35 6 g 19 7 t 21
# 由字典创建:不能在使用index.但是依然存在默认索引
1 dic = { 2 ‘name’':Tom, 3 'age':99 4 } 5 s = Series(data=dic)
2、Series的索引和切片
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的是一个Series类型)。
(1) 显式索引:
- 使用index中的元素作为索引值
- 使用s.loc[](推荐):注意,loc中括号中放置的一定是显示索引- 显示索引切片:index和loc
(2) 隐式索引:
- 使用整数作为索引值
- 使用.iloc[](推荐):iloc中的中括号中必须放置隐式索引
s.iloc[0:2]
- 隐式索引切片:整数索引值和iloc
3、Series的基本概念
可以把Series看成一个定长的有序字典
可以通过shape,size,index,values等得到series的属性
1 s.index 2 3 s.values 4 5 可以使用s.head(),tail()分别查看前n个和后n个值 6 s.head(1)
对Series元素进行去重
1 s = Series(data=[1,1,2,2,3,3,4,4,4,4,4,5,6,7,55,55,44])
2 s.unique() # array([ 1, 2, 3, 4, 5, 6, 7, 55, 44], dtype=int64)
两个Series进行相加:索引与之对应的元素会进行算数运算,不对应的就补空
1 s1 = Series([1,2,3,4,5],index=['a','b','c','d','e']) 2 s2 = Series([1,2,3,4,5],index=['a','b','f','c','e']) 3 s = s1+s2 4 s
a 2.0 b 4.0 c 7.0 d NaN e 10.0 f NaN
可以使用pd.isnull(),pd.notnull(),或s.isnull(),notnull()函数检测缺失数据
s.notnull() # 判断每行是否是空值 a True b True c True d False e True f False
s.isnull 与之恰好相反,空值为True
例如:取出所以不是空值的行
1 s[s.notnull()] 2 3 a 2.0 4 b 4.0 5 c 7.0 6 e 10.0
二、DataFrame
1、DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values

DataFrame属性:values、columns、index、shape
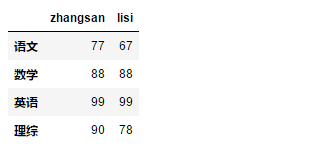
1 dic = { 2 '张三':[77,88,99,90], 3 '李四':[67,88,99,78] 4 } 5 df = DataFrame(data=dic,index=['语文','数学','英语','理综'])

字典的key作为列索引,index作为显示索引
2、DataFrame的索引
(1) 对列进行索引
- 通过类似字典的方式 df['q']
- 通过属性的方式 df.q可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name属性也已经设置好了,就是相应的列名。
例如:df['张三']

获取多个索引

#修改列索引
df.columns = ['zhangsan','lisi']
(2) 对行进行索引
- 使用.loc[]加index来进行行索引
- 使用.iloc[]加整数来进行行索引同样返回一个Series,index为原来的columns。

(3) 对元素索引的方法
- 使用列索引
- 使用行索引(iloc[3,1] or loc['C','q']) 行索引在前,列索引在后 如:df.iloc[0,1]
总结:索引的方式
1、对列进行索引使用df[],里面放置列索引
2、对行进行索引使用.loc[]方显示索引index 或.iloc[]放隐式索引整数
3、切片
总结:1、使用中括号df[0:2] 是对行进行切片
2、使用loc、iloc是对列进行切片:df.loc['B':'C','丙':'丁']
