一,模块的概念
别人写好的功能放在一个文件里
内置模块:安装python解析器的时候一起装上的
第三方模块,扩展模式:需要自己安装
自定义模块:自己写的py文件
1.序列化模块
序列:列表,元祖,字符串,bytes
Q1:什么叫序列化
把一个数据类型转换成, 字符串,bytes类型的过程就是序列化
Q2:为什么要把一个数据类型序列化?
当需要把一个数据类型存储在文件中
当需要把一个数据类型通过网络传输的时候
json的优点:在所有语言中都通用
缺点:只支持非常少的数据类型,对数据类型的约束很苛刻:
字典的key必须是字符串,且所有的字符串都必须是用""表示
只支持:数字 字符串 列表 字典
应用场景:在网络操作中,以及多语言环境中,要传递字典、数字、字符串、列表等简单的数据类型的时候使用
import json stu = {'name':'小明','sex':'male'} ret = json.dumps(stu) #序列化过程 lis = [1,2,3,4,5,6] lst = json.dumps(lis) print(stu,type(stu)) print(ret,type(ret)) print(lst,type(lst)) a = json.loads(ret) #反序列化的过程 b = json.loads(lst) print('a-->',a,type(a)) print('b-->',b,type(b))
文件操作间的序列化与反序列化:
#dump和load比较适合存取单个数据量的较大的字典或列表,否则最好使用dumps和loads import json dic = {'name':'小明','sex':'male'} with open('json_file','w',encoding='utf-8') as f: json.dump(dic,f,ensure_ascii=False) #可以多次往一个文件中dump,但是不能多次load,否则报错 #ensure_ascii参数默认为True,传入False,中文字符默认以中文的形式传入文件 with open('json_file','r',encoding='utf-8') as f: dic = json.load(f) print(dic,dic['name'])
json格式化输出
#json格式化 import json data = {'username':['李华','二愣子'],'sex':'male','age':16} json_dic2 = json.dumps(data,sort_keys=True,indent=4,separators=(',',':'),ensure_ascii=False) print(json_dic2)
pickle的优点:
操作文件必须以+b模式打开
在load的时候,如果这个要被load的内容所在的类不在内存中,会报错
pickle支持多次dump和多次load(需要异常处理)
支持几乎所有的python数据类型
缺点:只有python语言支持
import pickle stu = {'name':'小明','sex':'male',1:('a','b')} ret = pickle.dumps(stu) #以bytes形式序列化 print(ret) d = pickle.loads(ret) #反序列化后,pickle几乎完全支持python的数据类型,所以int类型的键,和元组都能支持 print('d--->',d,type(d))
文件操作间的序列化与反序列化:
import pickle class Course(): def __init__(self,name,price): self.name = name self.price = price python = Course('python',29800) linux = Course('linux',25800) mysql = Course('mysql',18000) ret1 = pickle.dumps(python) ret2 = pickle.dumps(linux) ret3 = pickle.dumps(mysql) print(ret1) print(ret2) print(ret3) p = pickle.loads(ret1) a = pickle.loads(ret2) d = pickle.loads(ret3) print(p.name,p.price) print(a.name,a.price) print(d.name,d.price) with open('pickle_file','wb') as f: pickle.dump(python,f) #dump序列化对象,可传入一个文件句柄 # f.write(ret1) with open('pickle_file','rb') as f: course = pickle.load(f) #load反序列化对象,可传入一个文件句柄 # ret = f.read() # course = pickle.loads(ret) print(course.name)
#多次dump序列化传入对象,并多次load反序列化读取对象 import pickle class Course(): def __init__(self,name,price): self.name = name self.price = price python = Course('python',29800) linux = Course('linux',25800) mysql = Course('mysql',18000) def my_dump(course): with open('pickle_file','ab') as f: pickle.dump(course,f) my_dump(python) my_dump(linux) my_dump(mysql) with open('pickle','rb') as f: while 1: try: content = pickle.load(f) print(content.name) except EOFError: #若读取不到数据会报错,所以需要异常处理 break
2.时间模块(time)
格式化时间:str数据类型的时间,例:'2018年9月4日 9时10分20秒'
时间字符串是人能够看懂的时间
时间戳时间:浮点数,秒为单位
#1970 1.1 00:00:00 英国伦敦时间
#1970 1.1 00:00:00 东8时区(北京时间)
时间戳是计算机能够识别的时间
结构化时间:元组
是用来操作时间的
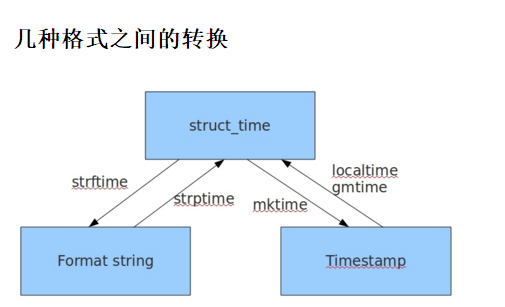
#时间戳-->结构化时间 #time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致 #time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 print(time.gmtime(1500000000)) #可传入时间戳显示,该时间戳的结构化时间(UTC) print(time.localtime(1500000000)) #不传值,默认是当期时间 #结构化时间-->时间戳 time_tuple = time.localtime(1500000000) print(time.mktime(time_tuple))
#结构化时间-->字符串时间 #time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间 print(time.strftime('%Y-%m-%d %X'))
#时间戳-->结构化时间-->字符串时间 print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(1500000000)))
#字符串时间-->结构化时间-->时间戳
#time.strptime(时间字符串,字符串对应格式)
time.strptime('2018-9-1','%Y-%m-%d') #具体时间不传,默认为0
str_time = '2018-8-8'
struct_time = time.strptime(str_time,'%Y-%m-%d')
print(struct_time)
timestamp = time.mktime(struct_time)
print(timestamp)
#实例: # 写函数,计算本月1号的时间戳时间 # 通过我拿到的这个时间,能迅速的知道我现在所在时间的年 月 def get_timestamp(): fmt_time = time.strftime('%Y-%m-1') #结构化时间-->字符串时间 struct = time.strptime(fmt_time,'%Y-%m-%d') #字符串时间-->结构化时间 res = time.mktime(struct) #结构化时间-->时间戳 return res ret = get_timestamp() print(ret)
3.随机数模块
import random #取随机小数 * print(random.random()) #(0,1)0-1范围内,不包括0,1 print(random.uniform(2,3)) #(n,m)n-m范围内,不包括n,m #取随机整数 **** print(random.randint(1,2)) #[1,2] 闭区间,包括2 print(random.randrange(1,2)) #[1,2) 开区间 不包括2 print(random.randrange(1,100,2)) #隔一个取一个 #从一个列表中随机抽取 **** lst = [1,2,3,4,5,('a','b'),'cc','dd'] ret = random.choice(lst) print(ret) ret = random.choice(range(100)) print(ret) #从一个列表中随机抽3个 ret = random.sample(lst,3) print(ret) #返回一个列表 #乱序 *** random.shuffle(lst) #将有序对象乱序 print(lst)
#实例: import random def get_code(n=6,alph_flag = True): code = '' for i in range(n): c = str(random.randint(0,9)) if alph_flag: alpha_upper = chr(random.randint(65,90)) #大写字母的ascii码 alpha_lower = chr(random.randint(97,122)) #小写字母的ascii码 c = random.choice([c,alpha_upper,alpha_lower]) code += c return code ret = get_code() print(ret)
4.os模块:操作系统相关模块
import os os.mkdir('dirname') #创建目录 os.makedirs('dirname1/dirname') #创建递归目录 #只能删掉空文件夹 os.rmdir('dirname') os.removedirs('dirname1/dirname2') #先从最底的目录开始删除 print(os.listdir('file')) #显示文件中所有的文件夹和文件的名,包括隐藏文件 print(os.stat('file')) #主要用作查看文件最后修改时间 # 转换为绝对路径 print(os.path.abspath('file')) print(os.path.abspath('file')) #切分目录,和文件名 path = 'file' ret = os.path.split(path) print(ret) #切分目录,和文件名,并返回目录 ret1 = os.path.dirname(path) print(ret1) #切分目录,和文件名,并返回文件名 ret2 = os.path.basename(path) print(ret2) #判断目标文件是否存在,返回bool值 res = os.path.exists('file') print(res) #判断文件或目录,返回bool print(os.path.isfile('file')) print(os.path.isdir('file')) #目录拼接 ret = os.path.join('file') ret = os.path.abspath(ret) #规范化 print(ret) #获取文件最后访问时间 os.path.getatime('file') #获取文件最后修改的时间 os.path.getmtime('file') #获取文件创建时间 os.path.getctime('file') #获取文件的大小(字节) windows 4096文件的信息,扩一倍 # linux/mac 文件夹占的大小 32/64 size = os.path.getsize('file/dirname') print(size) size = os.path.getsize('file') #只能看文件的占用的空间,不是所有文件的大小 print(size) #以字符串的形式来执行操作系统的命令 os.system('bash command') #以字符串的形式来执行操作系统的命令,并返回 os.popen('bash command').read() #显示执行这个文件时所在的目录 os.getcwd() #切换目录 print(__file__) #当前的绝对目录 os.chdir('file')
5.sys模块:是与python解释器交互的一个接口
import sys #sys.argv print(sys.argv) #命令行参数List,第一个元素是程序本身路径 #sys.path print(sys.path) #import模块,遍历这个列表,寻址模块的路径 #一个模块能否被导入,就看这个模块所在的目录在不在sys.path路径中 #内置模块和第三方扩展模块都需要我们处理sys.path就可以直接使用 #自定义的模块的导入工作需要自己手动的修改sys.path? #内置模块目录 # 'C:\xxxx\Python36\lib' # 第三方模块目录 # 'D:xxx\lib\site-packages' #sys.modules {查看当前内存空间中所有的模块:和这个模块的内存空间}
6.collections模式:根据基础数据类做一些扩展
#内置的数据类型 # int float complex # str list tuple # dict set #基础数据类型 # int float complex # str list tuple # dict #set不是基础数据类型
有序字典:py3.6以后自动有序
# 有序字典 py3.6以后自动有序 dic = {'a':1} d = dict([('a',1),('k1','v1')]) #正常创建字典的写法 print(d) from collections import OrderedDict dd = OrderedDict([('a',1),('k1','v1')]) print(dd) for k in dd: print(k,dd[k]) dd['k2'] = 'v2' print(dd)
默认字典:
# 默认字典 from collections import defaultdict d = defaultdict(list) #传入一个可调用参数,并执行,返回的值作为value的值 print(d['a']) d['b'].append(123) #增加一个键值对,并在d['b']中的列表追加元素 print(d) d = {} d['a'] #增加一个键值对 func = lambda :'default' d = defaultdict(func) #自定义默认字典的默认value print(d['kkk']) d['k'] = 'vvvvv' #修改字典的value print(d)
可命名元组:
可命名元组非常类似一个只有属性没有方法的类型
#可命名元组 from collections import namedtuple birth = namedtuple('Struct_time',['year','month','day']) b1 = birth(2018,9,5) print(type(b1)) print(b1.year) print(b1.month) print(b1.day) print(b1) #可命名元组非常类似一个只有属性没有方法的类 #['year','month','day']是对象属性名 #Struct_time是类 的名字 #这个类最大的特点就是一旦实例化 不能修改属性的值
双端队列:双端队列可以弥补list的缺点
#双端队列
#数据结构:链表原理 from collections import deque dq = deque() #创建一个双端队列 dq.append(1) #从末尾添加一个值 dq.append(2) dq.appendleft(3) #从开头添加一个值 print(dq) print(dq.pop()) #从末位弹出一个值 print(dq.popleft()) #从开头弹出一个值
#队列:先进先出,后进后出
import queue
q = queue.Queue() # 创建队列
q.put(1) #存一个值
q.put(2)
q.put('aaa')
q.put([1,2,3])
q.put({'k':'v'})
print(q.get()) #取一个值
print(q.get())
Counter: Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
c = Counter('abcdeabcdabcaba') print c 输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
7.hashlib模块:内部有不止一种算法的模块 *****
1.由于数据的不安全性,为了保证用户的信息绝对的安全,所以所有人的密码都不能以明文的形式存储,而应该经过适当的处理以密文的形式存起来。否则可能会被撞库破解
2.大家去计算这个密文,使用的是相同的算法
3.这个算法不可逆
4.不同的字符串通过这个算法的计算得到的密文总是不同的
5.相同的算法,相同的字符串,获得的结果总是相同(适用于不同的语言,不同的环境:操作系统,版本,时间)
#常规使用方式: md5_obj = hashlib.md5() #md5_obj不能重复使用 md5_obj.update('alex3714'.encode('utf-8')) ret = md5_obj.hexdigest()
hashlib摘要算法:具有多种算法,
md5算法:32位16进制的数学字符组成的字符串
应用最广大的摘要算法
效率高,相对不复杂,如果只是传统摘要不安全
sha算法:40位的16位进制的数字字符组成的字符串
sha算法要比md5算法更复杂
shan:n的数字越大算法越复杂,耗时越久,结果越长,越安全
sha_obj = hashlib.sha512() sha_obj.update('alex3714'.encode('utf-8')) ret = sha_obj.hexdigest() print(len(ret)) def get_md5(s): md5_obj = hashlib.md5() #md5_obj只能用一次,所有写成函数比较方便 md5_obj.update(s.encode('utf-8')) ret = md5_obj.hexdigest() return ret print(get_md5('alex3714'))
#多次update与一次性update结果是一样的 md51 = hashlib.md5() md51.update(b'666666') md51.update(b'999999') # 1ad2daed30c3862a267485c7cc9aacce print(md51.hexdigest()) md51 = hashlib.md5() md51.update(b'666666999999') # 1ad2daed30c3862a267485c7cc9aacce print(md51.hexdigest())
加盐:固定的盐,会导致恶意注册的用户密码泄露
def get_md5(s): md5_obj = hashlib.md5('盐'.encode('utf-8')) md5_obj.update(s.encode('utf-8')) ret = md5_obj.hexdigest() return ret
动态加盐:每个用户都有一个固定的并且互不相同的盐
def get_md5(user,s): md5_obj = hashlib.md5(user.encode('utf-8')) md5_obj.update(s.encode('utf-8')) ret = md5_obj.hexdigest() return ret print(get_md5('alex','alex3714')) #使用用户名作为盐
应用场景:
#登录验证
usr = input('username:').strip() passwd = input('passwd:').strip() def get_md5(s): md5_obj = hashlib.md5() md5_obj.update(s.encode('utf-8')) ret = md5_obj.hexdigest() return ret with open('userinfo',encoding='utf-8') as f: for line in f: u,p = line.strip().split('|') if u == usr and p == get_md5(passwd): print('登录成功') break else: print('用户或密码不正确')
# 文件的一致性校验 # 给一个文件中的所有内容进行摘要算法得到一个md5的结果
# 下载的是视频、或者大文件
# 应该是以rb的形式来读 读出来的都是bytes
# 并且不能按行读 也不能一次性读出来
import os import hashlib def get_file_md5(file_path,buffer = 1024): md5_obj = hashlib.md5() file_size = os.path.getsize(file_path) #先确认文件大小是否一致 with open(file_path,'rb') as f: while file_size: content = f.read(buffer) #默认每次取1024个字节 file_size -= len(content) md5_obj.update(content) return md5_obj.hexdigest() print(get_file_md5( r'file')) # 路径里不能有空格
8.配置文件:
当在开发环境的程序上线到生成环境或者生产环境时,往往需要修改文件,可以使用配置文件对需要操作的文件进行管理
#生成配置文件 import configparser config = configparser.ConfigParser() #相当于实例化一个对象 config["DEFAULT"] = {'ServerAliveInterval': '45', #添加属性 'Compression': 'yes', 'CompressionLevel': '9', 'ForwardX11':'yes' } config['bitbucket.org'] = {'User':'hg'} config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'} with open('example.ini', 'w') as configfile: #写入:生成配置文件 config.write(configfile)
#查看配置文件 import configparser config = configparser.ConfigParser() print(config.sections()) # [] config.read('example.ini') #加载配置文件 print(config.sections()) # ['bitbucket.org', 'topsecret.server.com'] print('bytebong.com' in config) # False print('bitbucket.org' in config) # True print(config['bitbucket.org']["user"]) # hg print(config['DEFAULT']['Compression']) #yes print(config['topsecret.server.com']['ForwardX11']) #no print(config['bitbucket.org']) #<Section: bitbucket.org> for key in config['bitbucket.org']: # 注意,有default会默认default的键 print(key) print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键 print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对 print(config.get('bitbucket.org','compression')) # yes get方法Section下的key对应的value
#配置文件的增删改 import configparser config = configparser.ConfigParser() config.read('example.ini') config.add_section('yuan') config.remove_section('bitbucket.org') config.remove_option('topsecret.server.com',"forwardx11") config.set('topsecret.server.com','k1','11111') config.set('yuan','k2','22222') config.write(open('new2.ini', "w"))
9.logging模块
Q1:什么是日志?
无处不在的,所有的程序都必须记录日志
日志的主要应用: 例: # 1.给用户看的 # 购物软件 # 视频软件 # 银行卡 # 2.给内部人员看的 # 给技术人员看的 # 计算器 # 500个小表达式 # 一些计算过程、或者是一些操作过程需要记录下来 # 程序出现bug的时候 来帮助我们记录过程 排除错误 # 给非技术人员看的 # 学校、公司的软件 # 谁在什么时候做了什么事儿,删除操作
import logging logging.basicConfig(level=logging.INFO) #显示优先级 logging.debug('debug message') # 计算或者工作的细节 logging.info('info message') # 记录一些用户的增删改查的操作 logging.warning('input a string type') # 警告操作 logging.error('error message') # 错误操作 logging.critical('critical message') # 批判的 直接导致程序出错退出的
# 简单配置 logging.basicConfig(level=logging.INFO, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', datefmt='%c', filename='test.log') logging.warning('input a string type') # 警告操作 logging.error('EOF ERROR ') # 警告操作 logging.info('6666') # 警告操作
# 对象的配置 # 解决简单配置的中文问题 # 可以同时向文件和屏幕输出内容 # 先创建一个log对象 logger logger = logging.getLogger() logger.setLevel(logging.DEBUG) # 还要创建一个控制文件输出的文件操作符 fh = logging.FileHandler('mylog.log') # 还要创建一个控制屏幕输出的屏幕操作符 sh = logging.StreamHandler() # 要创建一个格式 fmt = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') fmt2 = logging.Formatter('%(asctime)s - %(name)s[line:%(lineno)d] - %(levelname)s - %(message)s') # 文件操作符 绑定一个 格式 fh.setFormatter(fmt) # 屏幕操作符 绑定一个 格式 sh.setFormatter(fmt2) sh.setLevel(logging.WARNING) # logger对象来绑定:文件操作符, 屏幕操作符 logger.addHandler(sh) logger.addHandler(fh) logger.debug('debug message') # 计算或者工作的细节 logger.info('info message') # 记录一些用户的增删改查的操作 logger.warning('input a string type') # 警告操作 logger.error('error message') # 错误操作 logger.critical('critical message') # 批判的 直接导致程序出错退出的