一、基本概念:
1. Hash函数
通过哈希函数,将输入域(可以是非常大的范围)指定到一个固定范围的输出域s上。
具有四大性质:
1. 拥有无限的输入域
2. 如果输入值相同,返回值一样
3. 如果输入值不相同,返回值可能相同,可能不同
4. 不同输入值得到的哈希值,整体均匀的分布在输出域s中——优秀哈希函数的判断。
经典算法:MD5、SHA1
2. 一致性哈希算法
例如,服务器集群中,如果目前的机器数为N,如果使用取余的哈希算法中,一旦增减或减少一台机器,则所有的数据都要重新取余计算器对应的机器。
一致性哈希算法特点:
将HASH函数计算后得到的数据当作一个环,每个数据和每台机器都对应在环上的一个位置,对于一个数据来说,找到它分属的机器,就是以它自己为起点,在环上顺时针找到离它最近的机器即可。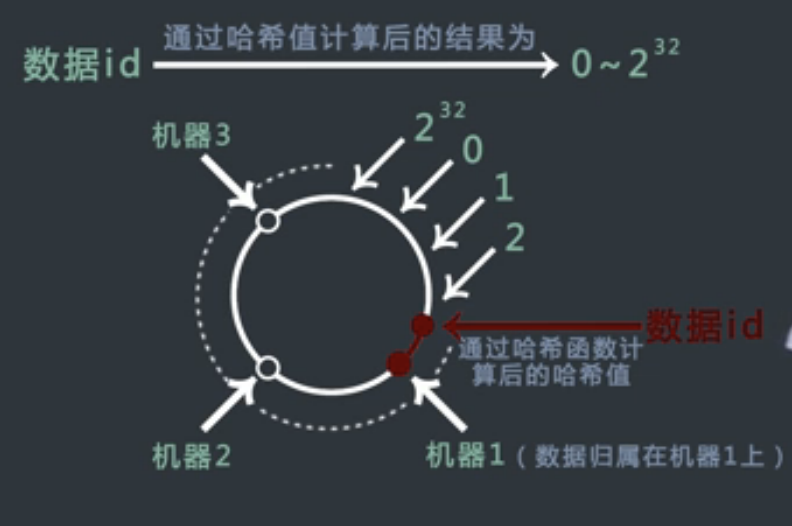
所以增减、迁移数据的代价很小。
3. Map/Reduce
Map:把大任务利用HASH分成若干小任务,在机器中运行
Reduce:将小任务得到的结果并发处理,得到最终的结果
4. 解题套路——词频统计
1. 根据内存的限制,对整个数据根据哈希函数分配到不同的机器上/或者分流。
例如:如果数字是0~232,内存限制是10M,则意味着每个区域最大的范围是:10M,所以所需要的分区数是:232/10M= 64
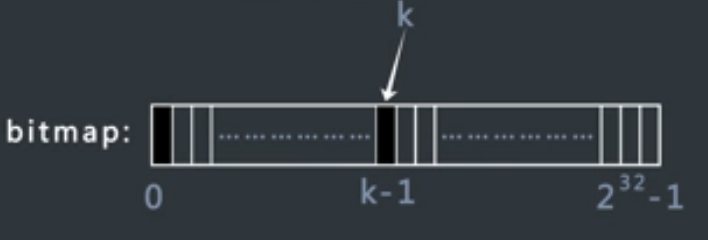
2. 在每个分区上根据bitmap,对每个数据进行词频统计。
对于bitmap,每一位只能有0/1,第k-1位代表的就是数字k是否出现
例如:对于0~232范围内的数据,只需要长度为232的bit数组,也就是:128M
3. 如果要选出TOP-K,则利用最大堆/最小堆
4. 综合所有分区,得到结果。
二、遇到的题目:
1. 统计一篇文章中每个单词的词频
(1)预处理——抓取全部有效单词
- 去掉标点符号
- 补全缩写字母
- 连词处理(换行)
- 大小写处理
(2)利用Map:生成每个单词词频为1的记录:(dog, 1)、(pig, 1)、(dog,1)——>可能有重复
通过hash函数得到每个单词的哈希值,根据哈希值分配成若干组。——相同单词一定分在一个组
(3)在每个分组中,利用reduce将单词记录合并。最后再将所有的单词记录合并。
2. 对10亿个IPV4的地址进行排序,每个Ip只出现一次
1)申请一个128M的bitmap,在bitmap中每个位置对应的值只能是0/1代表出现/不出现
2)将ipv4地址——>整数,如果出现在相应的bitmap中的位置设为1
3)遍历bitmap,得到未出现的数字
3. 对10亿人的年龄进行排序
基数排序
4. 有一个包含20亿个全部是32为整数的大文件,在其中找到出现次数最多的数,但是内存限制为2G
1)根据内存限制进行分区。
20亿/2G = 16个
2)在每一个区间内,使用hash表统计词频,选出词频最多的数
3)综合每个分区的词频第一,得到最终的第一。
5. 32位无符号函数的范围:0~4294967295.现在有一个包含了20多亿个无符号整数的文件,在无符号范围内找到一个未出现的数,内存<10M
1)根据内存限制,对232差不多42亿个数字,进行分组:
分组个数:232/10M =64
2)若一个分区词频的数字<它的长度,则代表有缺失
3)在这个有缺失的分区,利用bitmap找出缺失的那个数
6. 从百亿词汇中,找到最热的100个词
1)根据哈希函数,分流到各个机器,如果每台机器的内存不够,则进一步分流到分区中,
2)在每个可处理的最小分区中,利用hashmap统计词频
3)在每个分区中,利用最小堆选出TOP100
4)综合所有,利用外排序/最小堆得到最终的TOP100