一、TOKEN
Token的特点:
- 无状态、可扩展
- 支持移动设备
- 跨程序调用
- 安全
Token原理:
- 将荷载PAYLOAD以及HEADER信息进行Base64加密,形成密文payload密文,head密文。
- 将形成的密文用句号连接起来,用服务端密钥进行HS256加密,生成签名。
- 将前面的两个密文后面用句号连接签名形成最终的TOKEN返回给服务端。
TOKEN的实现:
- 用户登录校验,校验成功后就返回TOKEN给客户端
- 客户端收到数据后保存在客户端
- 客户端每次访问API是携带TOKEN到服务器端
- 服务器端采用FILTER过滤器校验。校验成功则返回请求数据,校验失败则返回错误码。
Token用在:登录校验。
TOKEN与session对比有更高的安全性,无状态可扩展性和多平台跨越的优点。
TOKEN可以完美解决跨站请求伪造,负载均衡,无状态可扩展性等问题。
二、敏捷开发
敏捷开发是以人为核心,迭代循序渐进的开发方法。他不是一门技术,他是一种开发方式,也就是一种软件开发流程。它采用的是迭代式开发。
三大核心角色:
产品负责人:负责确定产品功能和达到要求的标准。规定软件发布日期和交付内容,同时又权利接受拒绝开发成果。
流程管理员: 负责整个敏捷开发流程在项目中的顺利实施和进行,以及与客户沟通排除沟通障碍,使开发满足客户需求。
开发团队:负责开发工作。负责不同的技术方面,成员要求达到SPRINT的目标。
三个物件:
Productbacklog(产品待办事项列表)、
Sprint backlog(迭代列表)
燃尽图
四个会议:
Sprint计划会议,每日例会
Sprint评审会议,sprint回顾会议
项目前:
- 敏捷开发需求分析
2. Product Backlog(产品需求列表)
3. Sprit计划会议
项目中:
- print Backlog(迭代列表)
2. Daily Scrum Meeting(每日立会)
3. Sprint burn down(迭代周期燃尽图)
4. 版本迭代
项目后:
评审会议
总结会议
特点:
敏捷开发技术特点:
- 个体和交互胜过过程和工具
- 可以工作的软件胜过面面俱到的文档
- 客户合作胜过合同谈判
- 相应变化胜过遵循计划
优点:
用户参与其中,客户满意度高。
提高开发效率
市场快速反应能力高
缺点:
繁琐,压力大。
最小粒度:
什么是服务:服务代表一个或一组相对较小且独立的功能单元,是用户可以感知的最小功能集。登录,添加用户。。。。。。
基本服务就是最小服务,这种服务有比较高的重用性。
合成:基本服务简单组合。
组合服务:算是最大力度服务,里面基本服务关系受到工作流程控制。
粒度就是功能大小,粗粒度表示功能业务多相对重用性较低,细粒度表示功能简单重用性高。
最大粒度:在一个抽象接口封装了大块的业务逻辑和能力。
优点:减少了服务请求的交互次数,减少成本。
缺点:带来更高的复杂性,交互大量数据,不能灵活适应需求变化,重用性低。
最小粒度:相对较小的功能单元,或交互少量数据。
优点:灵活性强,重用性高
缺点,需要通过多次服务交互才能实现。
特性:重用性、灵活性、性能
解决方案:
1、设计接口和实体类
2、统一管理设计模式
3、优化组件充足业务服务。
单点登录(SSO):
单点登录:就是用户只需一次登录就可以访问所有相互信任的应用系统。简单来说就是一处登录,处处登录,一处注销,处处注销。
作用:使得用户只要登录了其中一个系统,就可以访问其他相关系统,而不用进行身份验证登录。即用户只要登陆系统一次,该用户的身份信息就可以被系统中的多个主机上的应用所识别,不需要在访问每个应用时再分别进行登陆。
系统应用中的概念:
主要用于多系统的继承,即在多系统当中,用户只需要用到一个中央服务器,登录一次就可以访问这些系统的任何一个,无需多次登录。目前流行的企业业务整合的解决方案之一。
单点登录的组成
单点登录(SSO)体系主要有3个 :
(1)多个用户
(2)多个Web应用
(3)1个SSO认证中心(也就是我们的中央服务器)。 其中多个用户访问不同的Web应用,是否需要登 录由SSO认证中心来控制。
单点登录的实现方式
1. 以Cookie作为凭证媒介 ;
2. 通过JSONP实现 ;
3. 通过页面重定向的方式 ;
4.JWT+安全框架的实现方式
4. 使用独立登录系统 ;
单点登录的两种实现:
- redis实现单点登录
- CAS中央认证实现单点登录
Redis实现单点登录 - 处理流程:
1、登录页面提交用户名密码。
2、登录成功后生成token。Token相当于原来的jsessionid,字符串,可以使用uuid。
3、把用户信息保存到redis。Key就是token,value就是实体类对象转换成json。
4、使用String类型保存Session信息。可以使用“前缀:token”为key
5、设置key的过期时间。模拟Session的过期时间。一般半个小时。
6、把token写入cookie中。
7、Cookie需要跨域。
8、Cookie的有效期。关闭浏览器失效。
9、登录成功。
CAS中央认证:CAS SERVER 和CAS CLIENT
CAS SERVER负责对用户的认证工作,会为用户签发两个重要的数据,登录和服务。
CAS SERVER需要独立部署。
CAS CLIENT负责处理对客户端受保护的资源的访问请求,要对请求方进行身份认证,重定向到CAS SERVER进行认证。以过滤方式保护受保护的资源。对于访问受保护资源的请求,CAS CLIENT会分析请求中是否包含service ticket。
Spring boot:
Spring boot是一个非常好的微服务分布式开发框架,可以快速搭建一个系统。
Spring 4大核心:
- 自动配置
- 起步依赖
- 命令行界面
- Actuator
Springapplication的实现方法:
- 如果使用的是静态run方法那么首先要创建一个springapplication对象,他会提前做下面几件事情:
根据classpath里面是否存在某个特征类来决定是否应该创建一个为web应用使用的applicationcontext。
使用springfactoriesLoader在应用的classpath中查找加载所有可用的applicationContextInitializer。
使用springFactoriesLoader在应用的classpath中查找并加载所有可用ApplicationListener。
推断并设置main方法定义类。
- springapplication实例初始化完成并完成设置后,就开始执行run方法的逻辑,方法执行开始,首先遍历执行所有通过springFactoriesLoder可以查找到并加载的SpringApplicationRunlistener。调用它的started()方法,告诉SpringApplicationRunListener,spring boot开始执行。
- 创建并配置当前spring boot 应用将要使用的Environment。遍历调用所有apringapplicationRunListener的environmentPrepared()方法,告诉他们”当前springboot应用使用的Environment准备好了”。如果springapplication的showbanner属性被设置为true。则需要打印banner。
- 根据用户是否明确设置applicationContextClass类型以及初始化阶段的推断结果,决定改为当前SpringBoot应用创建什么类型的ApplicationContext并创建完成,然后根据条件决定是否添加ShutdownHook,决定是否使用自定义的BeanNameGenerator,决定是否使用自定义的ResourceLoader,当然最重要的是将之前准备好的Environment设置给创建好的ApplicationContext使用。
- ApplicationContext创建好之后,SpringApplication会再次借助Spring-FactoriesLoader,查找并加载classpath中所有可用的ApplicationContext-Initialzer然后遍历调用这些ApplicationContextInitializer的initialize(applicationContext)方法来对已经创建好的ApplicationContext进行进一步处理。
- 遍历所有SpringApplicationRunListener的contextPrepared()方法。最核心的一步,将之前通过@EnableAutoConfiguration获取的所有配置以及其他形式的IOC容器配置加载到已经准备完毕的ApplicationContext。遍历调用所有SpringApplicationRunListener的contextLoaded()方法。调用ApplicationContext的refresh()方法,完成IOC容器可用的最后一步,查找当前ApplicationContext中是否注册有CommandLineRunner,如果有遍历执行他们。
正常情况下,遍历执行SpringApplicationRunListener的finished()方法,只不过这种情况会将异常信息一并传入处理。
Spring boot整合Redis:
创建redis.properties配置文件。
然后建一个封装redisTemplate的redisutil类
最后建一个redisconf即可实现使用redis
Spring boot 整合jpa:
Jpa查询:基本查询分为两种,一种是spring data默认实现,一种是根据查询方法来自动解析成SQL。
- 继承JpaRepositoy
通过继承这个类来实现最基本的增删改查。
- 自定义简单查询:
JPA这里遵循的是约定大约配置的原则,就是遵循spring以及jpql定义的方法命名。Spring提供一套可以通过命名规范进行查询构建的机制,这套机制会把方法名过滤一些关键字,比如find...by、read...by,query...by和get...by。系统会根据关键字将命名解析成两个子语句,第一个By是区分这两个子语句的关键词.这个BY之前的是查询子语句(知名返回要查询的对象),后面的部分是条件子语句。如果直接findby...返回的就是定义respository时指定的领域对象集合,同时jpql中也定义了丰富的关键字:and、or等等...
Jpa关键注解一览:
@Entity 声明类为实体或表。
@Table 声明表名。
@Basic 指定非约束明确的各个字段。
@Embedded 指定类或它的值是一个可嵌入的类的实例的实体的属性。
@Id 指定的类的属性,用于识别(一个表中的主键)。
@GeneratedValue 指定如何标识属性可以被初始化,例如自动、手动、或从序列表中获得的值。
@Transient 指定的属性,它是不持久的,即:该值永远不会存储在数据库中。
@Column 指定持久属性栏属性。
@SequenceGenerator 指定在@GeneratedValue注解中指定的属性的值。它创建了一个序列。
@TableGenerator 指定在@GeneratedValue批注指定属性的值发生器。它创造了的值生成的表。
@AccessType 这种类型的注释用于设置访问类型。如果设置@AccessType(FIELD),则可以直接访问变量并且不需要getter和setter,但必须为public。如果设置@AccessType(PROPERTY),通过getter和setter方法访问Entity的变量。
@JoinColumn 指定一个实体组织或实体的集合。这是用在多对一和一对多关联。
@UniqueConstraint 指定的字段和用于主要或辅助表的唯一约束。
@ColumnResult 参考使用select子句的SQL查询中的列名。
@ManyToMany 定义了连接表之间的多对多一对多的关系。
@ManyToOne 定义了连接表之间的多对一的关系。
@OneToMany 定义了连接表之间存在一个一对多的关系。
@OneToOne 定义了连接表之间有一个一对一的关系。
@NamedQueries 指定命名查询的列表。
@NamedQuery 指定使用静态名称的查询
And findByLastnameAndFirstname
Or findByLastnameOrFirstname
Is,Equals findByFirstnameIs,findByFirstnameEquals
Between findByStartDateBetween
LessThan findByAgeLessThan
LessThanEqual find ByAgeLessThanEqual
GreaterThan findByAgeGreaterThan
GreaterThanEqual findByAgeGreaterThanEqual
After findByStartDateAfter
Before findByStartDateBefore
IsNull findByAgeIsNull
IsNotNull,NotNull findByAge(Is)NotNull
Like findByFirstnameLike
NotLike findByFirstnameNotLike
StartingWith findByFirstnameStartingWith
EndingWith findByFirstnameEndingWith
Containing findByFirstnameContaining
OrderBy findByAgeOrderByLastnameDesc
Not findByLastnameNot
In findByAgeIn(Collection ages)
NotIn findByAgeNotIn(Collection age)
TRUE findByActiveTrue()
FALSE findByActiveFalse()
IgnoreCase findByFirstnameIgnoreCase
Spring常用注解:
@Configuration 等同于spring的XML配置文件;使用Java代码可以检查类型安全。
@Controller:用于定义控制器类,在spring 项目中由控制器负责将用户发来的URL请求转发到对应的服务接口
(service层),一般这个注解在类中,通常方法需要配合注解@RequestMapping
@RestController:用于标注控制层组件(如struts中的action),@ResponseBody和@Controller的合集。
@RequestMapping:提供路由信息,负责URL到Controller中的具体函数的映射。
@Service:一般用于修饰service层的组件
@Autowired:自动导入依赖的bean
@Repository:使用@Repository注解可以确保DAO或者repositories提供异常转译,这个注解修饰的DAO或者repositories类会被ComponetScan发现并配置,同时也不需要为它们提供XML配置项。
@ControllerAdvice:包含@Component。可以被扫描到。统一处理异常。
@ExceptionHandler(Exception.class):用在方法上面表示遇到这个异常就执行以下方法。
定时任务:
现实生活中我们需要很多定制的任务,记住一些事情然后定时提醒我们,比如闹钟。应用开发中也经常需要一些周期性的操作,这时候就用到定时任务。
实现定时任务的集中实现方法:
- java.util.Timer类
Java自带的方法,允许调度一个task任务。使用这种方法可以让你程序按照一个频度执行,但不能在指定时间运行。Timertask类实现由timer安排的一次或重复执行的某个人物。每个timer对象对应的是一个线程,因此计时器所执行的任务应该迅速完成不然会延迟后续的任务。
举个栗子:
Timer timer=new Timer();
MyTask myTask=new MyTask();
timer.schedule(myTask, 1000, 2000);
TimerTask类主要实现run()方法里的业务逻辑,用法如下:
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.TimerTask;
public class MyTask extends TimerTask {
@Override
public void run() {
// TODO Auto-generated method stub
SimpleDateFormat simpleDateFormat=null;
simpleDateFormat=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
System.out.println("当前的系统时间为:"+simpleDateFormat.format(new Date()));
}
}
Timer线程如何终止:
默认情况下,创建的timer线程会一直执行,所以我们有4中方法终止timer线程。
调用timer的cancle方法
把timer线程设置成daemon线程,(new Timer(true)创建daemon线程),在jvm里,如果所有用户线程结束,那么守护线程也会被终止,不过这种方法一般不用。
当所有任务执行结束后,删除对应timer对象的引用,线程也会被终止。
调用System.exit方法终止程序
注意点:
每个timer仅对唯一一个线程
Timer不保证任务执行的十分精确。
Timer类是线程安全的。
- 连接池实现定时任务:
出现原因:
- timer之创建了一个线程,任务执行时间超过设置的时间将会出现问题。
- Timer创建的线程没有处理异常,因此一旦抛出异常,该线程就立刻终止。
方法简介
scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit)1234
上面的四个参数进行讲解:
第一个command参数是任务实例,
第二个initialDelay参数是初始化延迟时间,
第三个period参数是间隔时间,
第四个unit参数是时间单元。
3.Spring-Task
Spring自带的Task实现定时任务也有两种方式,一种是xml配置的方式,一种是使用注解@Scheduled,不管是那种方式,首先都需要在xml开头声明task
Quartz:
Quartz用一个jar文件,这个库文件包括了所有quartz核心功能。这些功能主要通过接口是Scheduler接口。
quartz的原理不是很复杂,只要搞明白几个概念,然后知道如何去启动和关闭一个调度程序即可。
1、Job
表示一个工作,要执行的具体内容。此接口中只有一个方法
void execute(JobExecutionContext context)
2、JobDetail
JobDetail表示一个具体的可执行的调度程序,Job是这个可执行程调度程序所要执行的内容,另外JobDetail还包含了这个任务调度的方案和策略。
3、Trigger代表一个调度参数的配置,什么时候去调。Scheduler可以将Trigger绑定到某一JobDetail中,这样当Trigger触发时,对应的Job就被执行。一个Job可以对应多个Trigger,但一个Trigger只能对应一个Job。
4、Calendar:org.quartz.Calendar是一些日历特定时间点的集合, 一个Trigger可以和多个Calendar关联。
5.ThreadPool:Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提高运行效率
在 Quartz 中,有两类线程,Scheduler 调度线程和任务执行线程,其中任务执行线程通常使用一个线程池维护一组线程
Spring boot实现定时任务:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
然后在启动类上面加上@EnableScheduling即可开启定时任务(@EnableScheduling 注解,它的作用是发现注解 @Scheduled的任务并由后台执行。没有它的话将无法执行定时任务)
创建定时任务实现类
安全框架Shiro:
Shiro是java的一个安全框架,功能强大,使用简单的java安全框架,为开发人员提供一个直观而全面的认证,授权,加密以及绘画管理解决方案。
为什么使用shiro:
- 易于使用,提供易于理解的java security API。
- 简单的身份认证,支持多数据源(LDAP,JDBC,Kerberos等)
- 支持一级缓存,以及提升应用程序的性能。
- Shiro干净的API和设计模式使它可以方便与许多的其他框架和应用进行集成。
Shiro的用途:
- 验证用户来核实他们的身份
- 对用户执行访问控制,如:判断用户是否被分配了一个确定的安全角色、判断用户是否被允许做某事。
- 在任何环境下使用sessionAPI,即使没有web或ejb容器。
- 在身份验证,访问看哦内置期间或在会话的生命周期,对时间做出反应。
- 启用单点登录功能
- 数据加密,防止密码明文储存。
主要功能特点:

Authentication:身份认证/登录,验证用户是不是拥有相应的身份。
Authorization:授权,即权限验证,验证某个已认证的用户是否拥有某个权限;即判断用户是否能做事情,常见的如:验证某个用户是否拥有某个角色。或者验证某个用户对某个资源是否具有某个权限;
Session Manager:会话管理,即用户登录后就是一次会话,在没有退出之前,它的所有信息都在会话中;会话可以是普通JavaSE环境的,也可以是如Web环境的;
Cryptography:加密,保护数据的安全性,如密码加密存储到数据库,而不是明文存储;
Web Support:Web支持,可以非常容易的集成到Web环境;
Caching:缓存,比如用户登录后,其用户信息、拥有的角色/权限不必每次去查,这样可以提高效率;
Concurrency:并发,shiro支持多线程应用的并发验证,即如在一个线程中开启另一个线程,能把权限自动传播过去;
Testing:提供测试支持;
Run As:允许一个用户假装为另一个用户(如果允许)的身份进行访问;
Remember Me:记住我,这个是非常常见的功能,即一次登录后,下次再来的话不用登录了。
总体架构:
1) Subject:主体,代表了当前“用户”。这个用户不一定是一个具体的人,与当前应用交互的任何东西都是 Subject,如第三方进程,后台账户等,它仅仅意味着“当前跟软件交互的东西”。 Subject在shiro中是一个接口,接口中定义了很多认证授相关的方法,外部程序通过subject进行认证授,而subject是通过SecurityManager安全管理器进行认证授权 ,我们可以把 Subject 认为是一个门面,SecurityManager 才是实际的执行者。
2) SecurityManager:安全管理器。对全部的subject进行安全管理,Shiro框架的核心,即所有与安全有关的操作都会与 SecurityManager 交互。通过SecurityManager可以完成subject的认证、授权等,实质上SecurityManager是通过Authenticator进行认证,通过Authorizer进行授权,通过SessionManager进行会话管理等。 SecurityManager是一个接口,继承了Authenticator, Authorizer, SessionManager这三个接口
3) Realm:域。Shiro 从 Realm 获取安全数据(如用户、角色、权限),就是说 SecurityManager 要验证用户身份,那么它需要从 Realm 获取相应的用户进行比较以确定用户身份是否合法,也需要从 Realm 得到用户相应的角色/权限进行验证用户是否能进行操作。我们可以把 Realm 看成 DataSource,即安全数据源。
记住一点,Shiro不会去维护用户、维护权限;这些需要我们自己去设计/提供;然后通过相应的接口注入给Shiro即可。
也就是说对于我们而言,最简单的一个Shiro应用:
1、应用代码通过Subject来进行认证和授权,而Subject又委托给SecurityManager;
2、我们需要给Shiro的SecurityManager注入Realm,从而让SecurityManager能得到合法的用户及其权限进行判断。
内部结构:
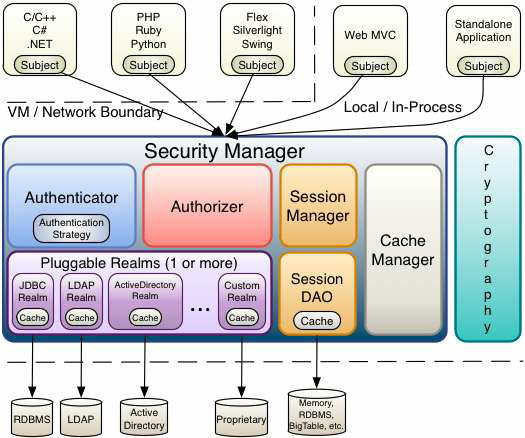
1) Subject:主体,可以看到主体可以是任何与应用交互的“用户”。
2) SecurityManager:它是 Shiro 的核心,所有具体的交互都通过 SecurityManager 进行控制。它管理着所有 Subject、且负责进行认证和授权、及会话、缓存的管理。
3) Authenticator:认证器,负责主体认证的,认证就是核实用户身份的过程。这个过程常见的例子是“用户名/密码”组合。多数用户再登录软件系统时,通常会提供自己的用户名和密码,如果储存在系统里的密码与用户提供的匹配,他们就被认为通过认证。
4) Authrizer:授权器,或者访问控制器。它用来决定主体是否有权限进行相应的操作,即控制着用户能访问应用中的哪些功能。
5) Realm 可以有1个或多个Realm,可以认为是安全实体数据源,即用于获取安全实体的;可以是JDBC实现,也可以是LDAP实现,或者内存实现等等;由用户提供;注意:Shiro不知道你的用户/权限存储在哪及以何种格式存储;所以我们一般在应用中都需要实现自己的Realm;
6) SessionManager:即会话管理 ,shiro框架定义了一套会话管理,它不依赖web容器的session,所以shiro可以使用在非web应用上,也可以将分布式应用的会话集中在一点管理,此特性可使它实现单点登录。
7) SessionDAO:用于会话的增删改查。我们可以自定义 SessionDAO 的实现,控制session 存储的位置。如通过 JDBC 写到数据库或通过 jedis 写入 redis 中。另外SessionDAO 中可以使用 Cache 进行缓存,以提高性能。
8) CacheManager:缓存管理器。它来管理如用户、角色、权限等的缓存的。因为这些数据基本上很少去改变,放到缓存中后可以提高访问的性能。
9) Cryptography:密码模块,Shiro 提高了一些常见的加密组件用于如密码加密/解密的。
环境配置:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-core</artifactId>
<version>1.2.2</version>
</dependency>
</dependencies>
身份验证:
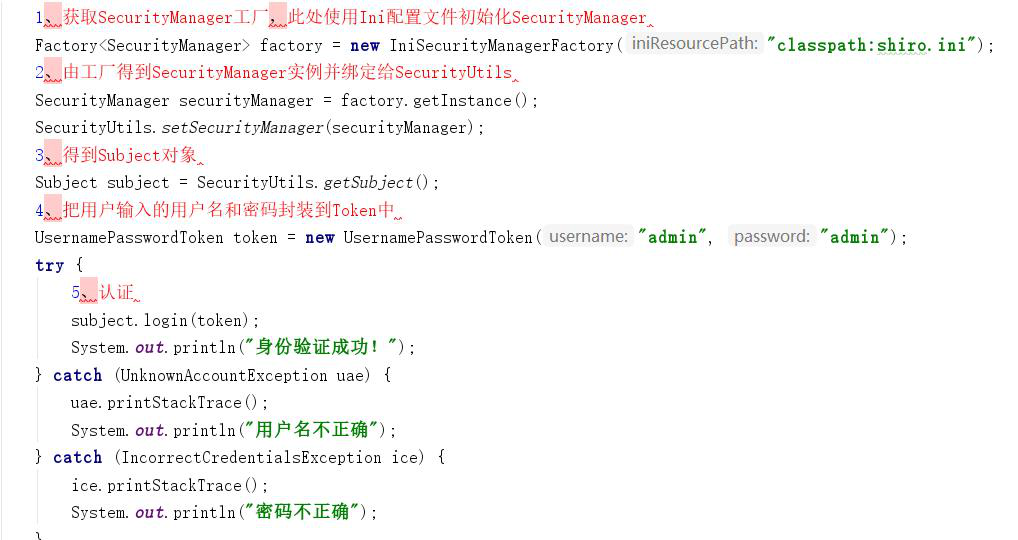
验证流程:
1、首先调用Subject.login(token)进行登录,其会自动委托给Security Manager,调用之前必须通过SecurityUtils. setSecurityManager()设置;
2、SecurityManager负责真正的身份验证逻辑;它会委托给Authenticator进行身份验证;
3、Authenticator才是真正的身份验证者,Shiro API中核心的身份认证入口点,此处可以自定义插入自己的实现;
4、Authenticator可能会委托给相应的AuthenticationStrategy进行多Realm身份验证,默认ModularRealmAuthenticator会调用AuthenticationStrategy进行多Realm身份验证;
5、Authenticator会把相应的token传入Realm,从Realm获取身份验证信息,如果没有返回/抛出异常表示身份验证失败了。此处可以配置多个Realm,将按照相应的顺序及策略进行访问。
Springboot整合shiro:
依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>net.sourceforge.nekohtml</groupId>
<artifactId>nekohtml</artifactId>
<version>1.9.22</version>
</dependency>
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-spring</artifactId>
<version>1.4.0</version>
</dependency>
Shiro提供了完整的企业级会话管理功能,不依赖于底层容器(如web容器tomcat),不管JavaSE还是JavaEE环境都可以使用,提供了会话管理、会话事件监听、会话存储/持久化、容器无关的集群、失效/过期支持、对Web的透明支持、SSO单点登录的支持等特性。即直接使用Shiro的会话管理可以直接替换如Web容器的会话管理。0
Shiro的会话支持不仅可以在普通的JavaSE应用中使用,也可以在JavaEE应用中使用,如web应用。且使用方式是一致的。
登录成功后使用Subject.getSession()即可获取会话;其等价于Subject.getSession(true),即如果当前没有创建Session对象会创建一个;另外Subject.getSession(false),如果当前没有创建Session则返回null(不过默认情况下如果启用会话存储功能的话在创建Subject时会主动创建一个Session)。
session.getId():获取当前会话的唯一标识。
session.getHost():获取当前Subject的主机地址,该地址是通过HostAuthenticationToken.getHost()提供的。
session.getTimeout();
session.setTimeout(毫秒); :获取/设置当前Session的过期时间;如果不设置默认是会话管理器的全局过期时间。
session.getStartTimestamp();
session.getLastAccessTime();
获取会话的启动时间及最后访问时间;如果是JavaSE应用需要自己定期调用session.touch()去更新最后访问时间;如果是Web应用,每次进入ShiroFilter都会自动调用session.touch()来更新最后访问时间。
session.touch();
session.stop();
更新会话最后访问时间及销毁会话;当Subject.logout()时会自动调用stop方法来销毁会话。如果在web中,调用javax.servlet.http.HttpSession. invalidate()也会自动调用Shiro Session.stop方法进行销毁Shiro的会话。
session.setAttribute("key", "123");
Assert.assertEquals("123", session.getAttribute("key"));
session.removeAttribute("key");
设置/获取/删除会话属性;在整个会话范围内都可以对这些属性进行操作。
企业级搜索引擎Solr:
Solr是企业级全文检索工具,采用了词源匹配和切分词。提供了检索功能的实现。
为什么使用solr:
搜索关键字的时候要通过like去数据库遍历查询每个字,效率很低,而且有些是无法查询的。Solr做的事情就是分词,然后去匹配分词的词中是否有你想搜的词就好了,当然了,为了提高这种检索效率和内存节省底层做了很复杂的事情,可以这么简单的认为,全文搜索这件事情上数据库是无法满足的,数据库本身不能实现分词效果,而只能使用模糊查询,但是模糊查询非常低效,查询速度比较慢,由于在实际生活中,一般搜索是用的比较多的,这样数据库压力自然就很大,所以我们就让供专业的solr来做搜索功能
全文检索:
对文档内容进行分词,对分词后的结果创建索引,然后通过对所有进行搜索的方式叫做全文检索。
全文检索相当于根据偏旁部首或拼音查字典一样,在文档很多情况查找速度提高。
应用场景:对于数据量大,数据结构不固定的数据采用全文检索。百度google等搜索引擎,电商网站都在使用全文检索。
Lucene:
Lucence是apache开发的一个全文检索引擎工具包,他不是一个完整的全文检索搜索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分着引擎。
Lucene是一个索引与搜索类库,而不是一个完整的程序。
Solr简介:
Solr是apache的顶级开源项目,采用java开发,solr提供比lucene更丰富的查询语言,同时实现了可配置,可扩展,并对索引搜索性能进行优化。是一个企业级搜索引擎。
Solr可独立运行,solr提供了一个管理界面,通过管理界面可以查询solr的配置和运行情况。
对比solr和lucene:
Solr和Lucene的本质区别有以下三点:搜索服务器,企业级和管理。Lucene本质上是搜索库,不是独立的应用程序,而Solr是。Lucene专注于搜索底层的建设,而Solr专注于企业应用。Lucene不负责支撑搜索服务所必须的管理,而Solr负责。所以说,一句话概括Solr: Solr是Lucene面向企业搜索应用的扩展
Solr通过managed-schema的方式来配置Filed,与Lucene相比,这种方式更为灵活。特别是在团队开发中,更易于团队协同作战。而且solr还提供了Copy Field和Dynamic Filed这两种Lucene没有的Filed,这使得文档建模更为灵活,功能更加强大。
作为一个Web应用程序,solr可以轻松地部署在Jetty、Tomcat等Servlet服务器上。
Solr特性:
1.基于标准的开放接口:Solr搜索服务器支持通过XML、JSON和HTTP查询和获取结果。
2.易管理:Solr可以通过HTML页面管理,Solr配置通过XML完成。
3.可伸缩性:能够有效地复制到另外一个Solr搜索服务器。
4.灵活的插件体系:新功能能够以插件的形式方便的添加到Solr服务器上。
5.强大的数据导入功能:数据库和其他结构化数据源现在都可以导入、映射和转化。
Solrj:
Solrj是操作solr的java客户端,提供了增删改查solr索引的java接口。
SolrJ针对 Solr提供了Rest 的HTTP接口进行了封装, SolrJ底层是通过使用httpClient中的方法来完成Solr的操作。
Solrj面对对象的思想,所有搜索条件均以setter属性的方式设置到其封装的对象中。但是,实际上还是通过拼接URL的方式,走http请求的方式再请求Solr服务器。如果采用http直接访问的方法,我们必然会用到httpclient请求solr服务器。
依赖:
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.4.0</version>
</dependency>
RabbitMQ(消息队列):
(1) 先看几个例子;
2.1异步处理
场景说明:用户注册后,需要发注册邮件和注册短信,传统的做法有两种1.串行的方式;2.并行的方式
(1)串行方式:将注册信息写入数据库后,发送注册邮件,再发送注册短信,以上三个任务全部完成后才返回给客户端。 这有一个问题是,邮件,短信并不是必须的,它只是一个通知,而这种做法让客户端等待没有必要等待的东西. 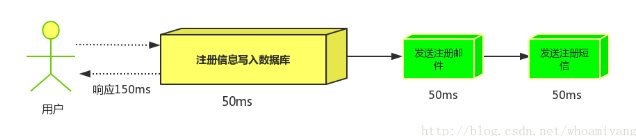
(2)并行方式:将注册信息写入数据库后,发送邮件的同时,发送短信,以上三个任务完成后,返回给客户端,并行的方式能提高处理的时间。
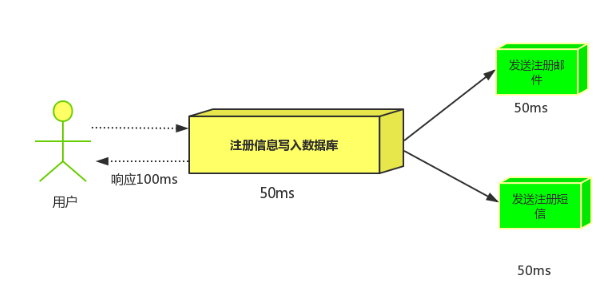
假设三个业务节点分别使用50ms,串行方式使用时间150ms,并行使用时间100ms。虽然并性已经提高的处理时间,但是,前面说过,邮件和短信对我正常的使用网站没有任何影响,客户端没有必要等着其发送完成才显示注册成功,英爱是写入数据库后就返回.
(3)消息队列
引入消息队列后,把发送邮件,短信不是必须的业务逻辑异步处理
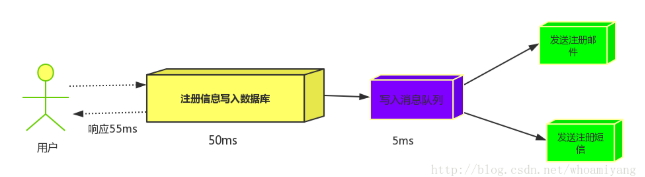
由此可以看出,引入消息队列后,用户的响应时间就等于写入数据库的时间+写入消息队列的时间(可以忽略不计),引入消息队列后处理后,响应时间是串行的3倍,是并行的2倍。
2.2 应用解耦
场景:双11是购物狂节,用户下单后,订单系统需要通知库存系统,传统的做法就是订单系统调用库存系统的接口.

这种做法有一个缺点:
- 当库存系统出现故障时,订单就会失败。(这样马云将少赚好多好多钱^ ^)
订单系统和库存系统高耦合.
引入消息队列
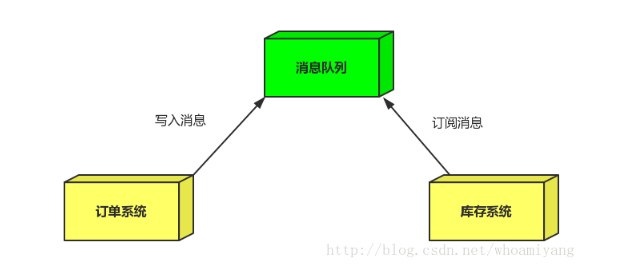
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
库存系统:订阅下单的消息,获取下单消息,进行库操作。
就算库存系统出现故障,消息队列也能保证消息的可靠投递,不会导致消息丢失(马云这下高兴了).
库存不够的情况:暂不讨论
文档:
关于秒杀的系统架构优化思路 http://www.cnblogs.com/chenpingzhao/p/6195788.html
浅谈库存扣减相关问题 https://blog.csdn.net/xiongyouqiang/article/details/79388120
2.3流量削峰
流量削峰一般在秒杀活动中应用广泛
场景:秒杀活动,一般会因为流量过大,导致应用挂掉,为了解决这个问题,一般在应用前端加入消息队列。
作用:
1.可以控制活动人数,超过此一定阀值的订单直接丢弃(我为什么秒杀一次都没有成功过呢^^)
2.可以缓解短时间的高流量压垮应用(应用程序按自己的最大处理能力获取订单)
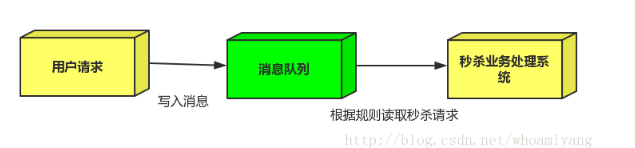
1.用户的请求,服务器收到之后,首先写入消息队列,加入消息队列长度超过最大值,则直接抛弃用户请求或跳转到错误页面. (库存不够的情况)
2.秒杀业务根据消息队列中的请求信息,再做后续处理.
别啥固定式使用场景了,说的透彻一点,他就是服务器之间通信的,前面博文中提到的Httpclient也可以做到,但是这个相对于其他通信在中间做了一个中间仓库。
好处1:降低了两台服务器之间的耦合,哪怕是一台服务器挂了,另外一台服务器也不会报错或者休克,反正他监听的是MQ,只要服务器恢复再重新连上MQ发送消息,监听服务器就能再次接收。
好处2:MQ作为一个仓库,本身就提供了非常强大的功能,例如不再是简单的一对一功能,还能一对多,多对一,自己脑补保险箱场景,只要有特定的密码,谁都能存,谁都能取。也就是说能实现群发消息和以此衍生的功能。
好处3:现在普遍化的持久化功能,当MQ挂掉可以存储在磁盘等下重启恢复。(需要设置)
这里提到了消息队列,
什么是消息队列?
1、什么是消息队列?
《百度百科》
(1) “消息队列”(Message Queue)是在消息的传输过程中保存消息的容器。
(2) “消息”是在两台计算机间传送的数据单位。消息可以非常简单,例如只包含文本字符串;也可以更复杂,可能包含嵌入对象。
(3) 消息被发送到队列中。“消息队列”是在消息的传输过程中保存消息的容器。消息队列管理器在将消息从它的源中继到它的目标时充当中间人。队列的主要目的是提供路由并保证消息的传递;如果发送消息时接收者不可用,消息队列会保留消息,直到可以成功地传递它。
(4) 消息队列就是一个消息的链表。可以把消息看作一个记录,具有特定的格式以及特定的优先级。对消息队列有写权限的进程可以向消息队列中按照一定的规则添加新消息;对消息队列有读权限的进程则可以从消息队列中读走消息。消息队列是随内核持续的。 -
什么是MQ?
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取队列中的消息。
Jms:
https://blog.csdn.net/jiuqiyuliang/article/details/46701559
消息队列:队列,先进先出,数据结构,放消息的队列。
2、为什么会需要消息队列?
(1) 主要原因是由于在高并发环境下,由于来不及同步处理,请求往往会发生堵塞,比如说,大量的insert,update之类的请求同时到达MySQL,直接导致无数的行锁表锁,甚至最后请求会堆积过多,从而触发too many connections错误。通过使用消息队列,我们可以异步处理请求,从而缓解系统的压力。
(2) 消息队列使用消息将应用程序连接起来。这些消息通过像RabbitMQ这样的消息代理服务器在应用程序之间路由,就像在应用程序中间放一个邮局。专注于程序之间的 消息通信。
3、
消息队列的应用场景:
异步处理
应用解耦
流量削峰
4、什么是RabbitMQ?
(1) RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
(2) Erlang语言:是一种通用的面向并发的编程语言,具有并发性,分布式、健壮性等特点,擅长处理并发。

(3) AMQP协议(Advanced Message Queuing Protocol)
① AMQP,即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。 AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。通讯的时候可以使用TCP或者UDP,常用的还是TCP。不限编程语言及系统。(TCP、UDP属于传输层(保证传输质量))
AMQP消息能以一对多的广播方式进行路由,也可以选择一对一的方式路由。
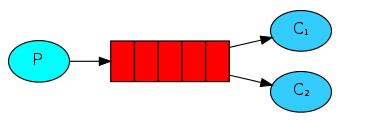
② 
1) 一对一
③ 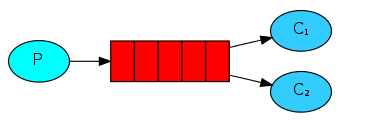
1) 一对多
(4) RabbitMQ是一个在AMQP基础上完成的,可复用的企业消息系统。
RabbitMQ系统架构:
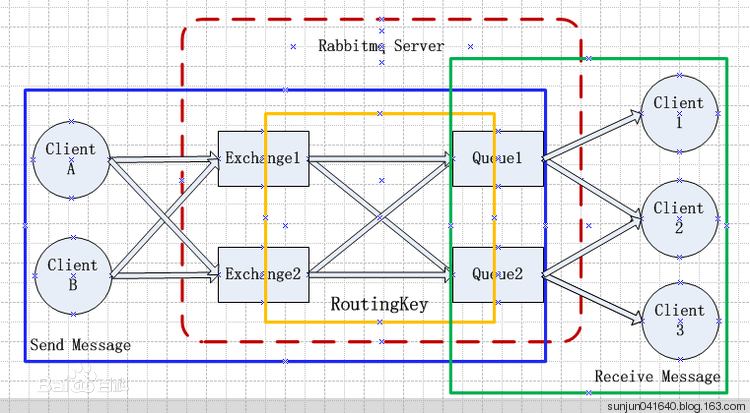
5、概念
(1) 生产者(producer)创建消息.然后发布(发送)到代理服务器(RabbitMQ)。
(2) 什么是消息呢?消息包含两部分内容:有效载荷(payload)和标签(label),有效载荷就是你想要传输的数据。它可以是任何内容.一个 JSON数组或者是你最喜欢的任何东西,RabbitMQ不会在意这些。标签:它描述了有效载荷.并且 RabbitMQ用它来决定谁将获得消息的拷贝。
(3) 举例来说,不同于 TCP协议的是.当你明确指定发送方和接收方时, AMQP只会用标答表述这条消息(一个交换器的名称和可选的主题标记),然后把消息交由 Rabbit, Rabbit会根据标签把消息发送给感兴趣的接收方。这种通信方式是一种“发后即忘"( fire-and-forget)的单向方式。眼下你只需要知道生产者会创建消息并设置标签(见图2」)。
(4) 消费者:消费者很容易理解。它们连接到代理服务器上,并订阅到队列( queue)上。把消息队列想象成一个具名邮箱。每当消息到达特定的邮箱时, RabbitMQ会将其发送给其中一个订阅的/监听的消费者。当消费者接收到消息时,它只得到消息的一部分:有效载荷。在消息路由过程中,消息的标签并没有随有效载荷一同传递。 RabbitMQ甚至不会告诉你是谁生产/发送了消息。就好比你拿起信件时,却发现所有的信封都是空白的。想要知道这条消息是否是从 Millie姑妈发来的唯一方式是她在信里签了名。同理,如果需要明确知道是谁生产的 AMQP消息的话,就要看生产者是否把发送方信息放人有效载荷中。
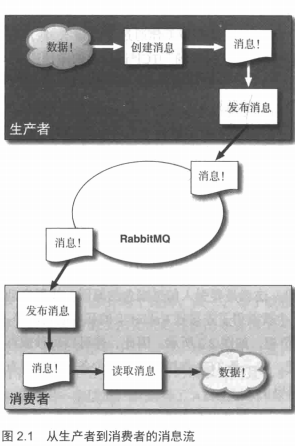
整个过程其实很简单:生产者创建消息,消费者接收这些消息。你的应用程序可以作为生产者,向其他应用程序发送消息。或者作为一个消费者,接收消息。也可以在两者之间进行切换。不过在此之前,它必须先建立一条信道( channel)等等!什么是信道呢?
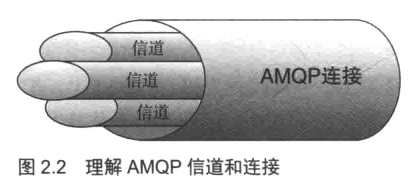
信道(channel):
你必须首先连接到 Rabbit,才能消费或者发布消息。你在应用程序和 Rabbit代理服务器之间创建一条 TCP连接。一旦 TCP连接打开(你通过了认证),应用程序就可以创建一条 AMQP信道。信道是建立在“真实的" TCP连接内的虚拟连接。 AMQP命令都是通过信道发送出去的。每条信道都会被指派一个唯一 ID(AMQP库会帮你记住 ID的)a不论是发布消息、订阅队列或是接收消息,这些动作都是通过信道完成的。你也许会问为什么我们需要信道呢?为什么不直接通过 TCP连接发送 AMQP命令呢7主要原因在于对操作系统来说建立和销毁 TCP会话是非常昂贵的开销。假设应用程序从队列消费消息,并根据服务需求合理调度线程。假设你只进行 TCP连接,那么每个线程都需要自行连接到 Rabbito也就是说高峰期有每秒成百上千条连接。这不仅造成 TCP连接的巨大浪费,而且操作系统每秒也就只能建立这点数量的连接勹因此,你可能很快就碰到性能瓶颈了。如果我们为所有线程只使用一条 TCP连接以满足性能方面的要求,但又能确保每个线程的私密性,就像拥有独立连接一样的话,那不就非常完美吗?这就是要引人信道概念的原因。线程启动后,会在现成的连接上创建一条信道,也就获得了连接到 Rabbit上的私密通信路径,而不会给操作系统的 TCP栈造成额外负担,如图2.2所示。因此,你可以每秒成百上千次地创建信道而不会影响操作系统。在一条 TCP连接上创建多少条信道是没有限制的。把它想象成一束光纤电缆就可以了。
RabbitMQ建议客户端线程之间不要共用Channel,至少要保证共用Channel的线程发送消息必须是串行的,但是建议尽量共用Connection.
Connection:连接,对于RabbitMQ而言,其实就是一个位于客户端和Broker之间的TCP连接。
AMQP元素:交换器 队列 绑定
生产者吧消息发送到交换机上,消息最终到达队列,并被消费者接受。
绑定决定了消息如何从路由器路由到特定的队列。
队列:
消息就像具名邮箱,消息最终到达队列中并等待消费。
从消息队列中接受消息的方式:
(1)通过 AMQP的 basic.consume命令订阅。这样做会将信道置为接收模式,直到取消对队列的订阅为止。订阅了消息后,消费者在消费(或者拒绝)最近接收的那条消息后,就能从队列中(可用的)自动接收下一条消息。如果消费者处理队列消息,并且/或者需要在消息一到达队列时就自动接收的话,你应该使用basic.consume
(2)某些时候,你只想从队列获得单条消息而不是持续订阅。向队列请求单条消息是通过 AMQP的 basic.get乜命令实现的。这样做可以让消费者接收队列中的下一条消息。如果要获得更多消息的话,需要再次发送 basic.get命令。你不应该将basic.get放在一个循环里来替代basic.get。因为这样做会影响 Rabbit的性能。大致上讲, basic-get命令会订阅消息,获得单条消息,然后取消订阅。消费者理应始终使用 basic.consume来实现高吞吐量。
channel.basicConsume(TASK_QUEUE_NAME, false, consumer);
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
具体看代码。
关于消息去向的讨论:
1、消息到无人订阅的队列
消息会一直在队列中等待,一旦有消费者订阅该队列,队列上的消息就会发给消费者。
2、多个消费者订阅同一个消息队列
循环发送。
假设有Query队列,消费者A和消费者B订阅到了Query队列,当消息到达query队列时:
(1)消息massage-a到达query
(2)RabbitMQ把massage-a消息发送给A
(3)A确认收到了消息massage-a
(4)RabbitMQ吧massage-a从query中删除
(5)消息message-b到达query队列
(6)RabbitMQ把massage-b发送给B
(7)B确认收到了消息massage-b
(8)RabbitMQ把massage-b从query中删除
消息的确认模式:
自动确认:
手动确认:
消费者监听队列的时候,有一个参数,如果为flase 则为手动模式。True是自动模式。
False必须做反馈。
消费者接受到消息必须进行确认。
消费者接收到的每一条消息都必须进行确认。消费者必须通过 AMQP的basic.ack命令显式地向 RabbitMQ发送一个确认,或者在订阅到队列的时候就将auto_ack参数设置为 true。当设置auto_ack时,一旦消费者接收消息, RabbitMQ会自动视其确认了消息。需要记住的是,消费者对消息的确认和告诉生产者消息已经被接收了这两件事毫不相关。因此,消费者通过确认命令告诉 RabbitMQ它已经正确地接收了消息,同时 RabbitMQ才能安全地把消息从队列中删除。
如果消费者收到一条消息,然后确认之前从 Rabbit断开连接(或者从队列上取消订阅), RabbitMQ会认为这条消息没有分发,然后重新分发给下一个订阅的消费者。如果你的应用程序崩溃了,这样做可以确保消息会被发送给另一个消费者进行处理。
另一方面,如果应用程序有 bug而忘记确认消息的话, Rabbit将不会给该消费者发送更多消息了。这是因为在上一条消息被确认之前, Rabbit会认为这个消费者并没有准备好接收下一条消息。你可以好好利用这一点。如果处理消息内容非常耗时,则你的应用程序可以延迟确认该消息,直到消息处理完成。这样可以防止 Rabbit持续不断的消息涌向你的应用而导致过载。
在收到消息后,如果你想要明确拒绝而不是确认收到该消息的话,该如何呢?举例来说,假设在处理消息的时候你遇到了不可恢复的错误,但是由于硬件问题,只影响到当前的消费者(这就是一个很好的示例,直到消息处理完成之前,你绝不能进行确认)。只要消息尚未确认,则你有以下两个选择:
(0)把消费者从 RabbitMQ服务器断开连接。这会导致 RabbitMQ自动重新把消息人队并发送给另一个消费者。这样做的好处是所有的 RabbitMQ版本都支持。缺点是,这样连接/断开连接的方式会额外增加 RabbitMQ的负担(如果消费者在处理每条消息时都遇到错误的话,会导致潜在的重大负荷)。
(2)如果你正使用 RabbitMQ2.0.0或者更新的版本,那就使用 AMQP的basic.reject命令。顾名思义:basic.reject允许消费者拒绝 RabbitMQ发送的消息。如果把 reject命令的 requeue参数设置成 true的话, RabbitMQ会将消息重新发送给下一个订阅的消费者。如果设置成 false的话, RabbitMQ立即会把消息从队列中移除,而不会把它发送给新的消费者。你也可以通过对消息确认的方式来简单地忽略该消息(这种忽略消息的方式的优势在于所有版本的 RabbitMQ都支持)。如果你检测到一条格式错误的消息而任何一个消费者都无法处理的时候,这样做就十分有用。
死信队列:
利用死信队列 实现定时发送
临时队列:断开连接就会删除
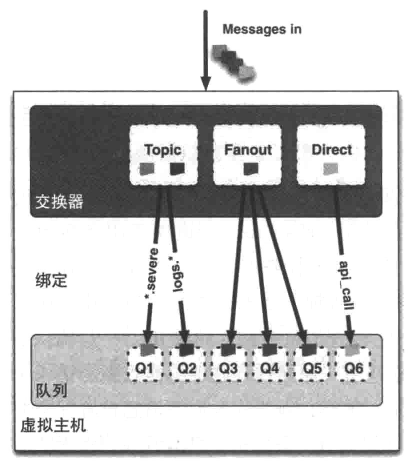
交换机(exchange)和绑定(binding):
就像在前几节看到的那样,你想让消费者从队列中获取消息。现在的问题是,消息是如何到达队列的呢?让我们来认识一下 AMQP的交换器和绑定。当你想要将消息投递到队列时,你通过把消息发送给交换器来完成。然后,根据确定的规则, RabbitMQ将会决定消息该投递到哪个队列。这些规则被称作路由键( routing key)。队列通过路由键绑定到交换器。当你把消息发送到代理服务器时,消息将拥有一个路由键一一一即便是空的—RabbitMQ也会将其和绑定使用的路由键进行匹配。如果相匹配的话,那么消息将会投递到该队列。如果路由的消息不匹配任何绑定模式的话,消息将进人“黑洞"
消息会根据路由键从交换机路由到队列,如何处理投递到多个队列的情况呢?
消息有路由键,队列有匹配规则。
不同类型的交换机发挥了作用:
交换机类型:
Header(头)
Header交换器允许你匹配AMQP消息的header而非路由键,除此之外,header交换器和direct交换机完全一致,但性能会差很多,因此他并不实用,而且几乎用不到了。
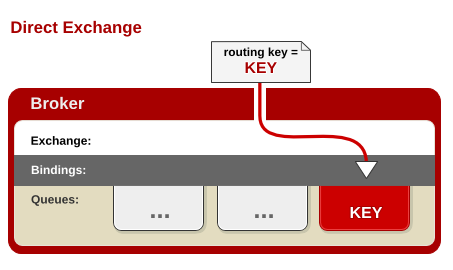
Direct(直接)
Direct Exchange – 处理路由键。需要将一个队列绑定到交换机上,要求该消息与一个特定的路由键完全匹配。这是一个完整的匹配。如果一个队列绑定到该交换机上要求路由键 “dog”,则只有被标记为“dog”的消息才被转发,不会转发dog.puppy,也不会转发dog.guard,只会转发dog。
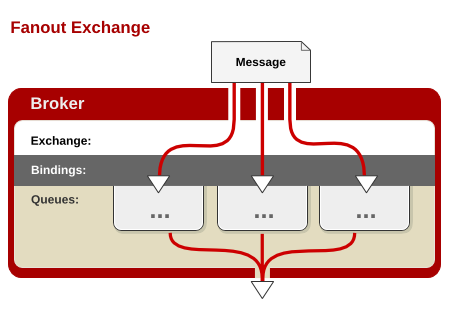
Fanout(展开)
Fanout Exchange – 不处理路由键。你只需要简单的将队列绑定到交换机上。一个发送到交换机的消息都会被转发到与该交换机绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。Fanout交换机转发消息是最快的。
Topic(主题)
Topic Exchange – 将路由键和某模式进行匹配。此时队列需要绑定要一个模式上。符号“#”匹配一个或多个词,符号“*”匹配不多不少一个词。因此“audit.#”能够匹配到“audit.irs.corporate”,但是“audit.*” 只会匹配到“audit.irs”。我在RedHat的朋友做了一张不
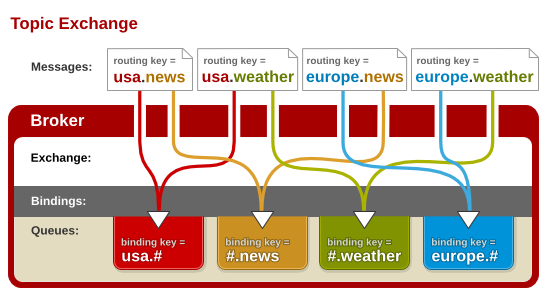
|
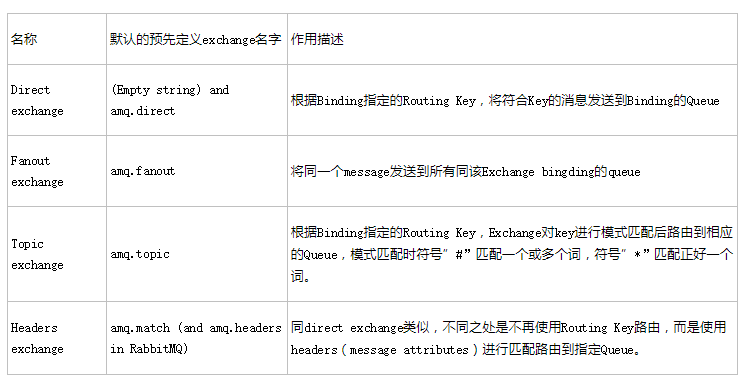
名称 |
默认的预先定义exchange名字 |
作用描述 |
|
Direct exchange |
(Empty string) and amq.direct |
根据Binding指定的Routing Key,将符合Key的消息发送到Binding的Queue |
|
Fanout exchange |
amq.fanout |
将同一个message发送到所有同该Exchange bingding的queue |
|
Topic exchange |
amq.topic |
根据Binding指定的Routing Key,Exchange对key进行模式匹配后路由到相应的Queue,模式匹配时符号”#”匹配一个或多个词,符号”*”匹配正好一个词。 |
|
Headers exchange |
amq.match (and amq.headers in RabbitMQ) |
同direct exchange类似,不同之处是不再使用Routing Key路由,而是使用headers(message attributes)进行匹配路由到指定Queue。 |
简单的说:
“exchange”(交换器)接收发布应用程序发送的消息,并根据一定的规则将这些消息路由到“消息队列”。
“message queue”(消息队列)存储消息,直到这些消息被消费者安全处理完为止。
“binding”(绑定)定义了exchange和message queue之间的关联,提供路由规则。
虚拟主机(vhost):
每一个 RabbitMQ服务器都能创建虚拟消息服务器,我们称之为虚拟主机( vhost)。每一个 vhost本质上是一个 mini版的 RabbitMQ服务器,拥有自己的队列、交换器和绑定一一更重要的是,它拥有自己的权限机制。这使得你能够安全地使用一个 RabbitMQ服务器来服务众多应用程序,而不用担心你的 Sudoku(数独)应用可能会删除狗狗防丢跟踪器正在使用的队列。 vhost之于 Rabbit就像虚拟机之于物理服务器一样:它们通过在各个实例间提供逻辑上分离,允许你为不同应用程序安全保密地运行数据。这很有用,它既能将同一 Rabbit的众多客户区分开来,又可以避免队列和交换器的命名冲突。否则你可能不得不运行多个 Rabbit,并忍受随之而来头疼的管理问题。相反,你可以只运行一个 Rabbit,然后按需启动或关闭 vhost。
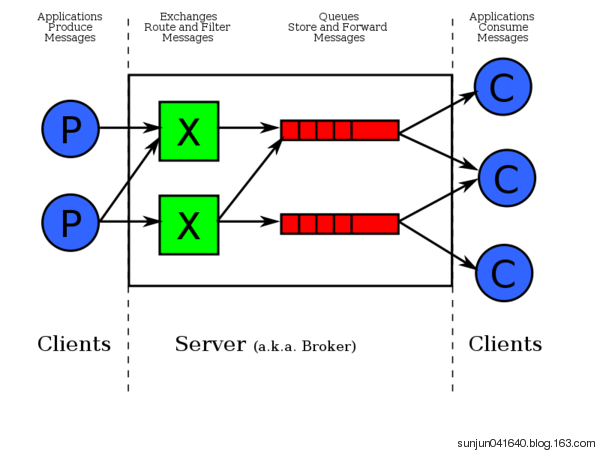
Broker::它提供一种传输服务,它的角色就是维护一条从生产者到消费者的路线,保证数据能按照指定的方式进行传输,简单来说就是消息队列服务器实体
消息持久化:
持久化队列,非持久化队列,
费持久化 速度快
队列类型:
简单队列:
代码
分析说明
阅后即焚
监听程序 如果没有 会阻塞阻塞。
Work模式:
一个生产者,多个消费者
消息是被一个消费者获取(争抢)
一个快,一个慢,结果拿到的结果是一样的
应该是快的拿到的多
轮训。
集群的时候
订阅模式:
前台系统 例如 搜索系统 或者 消费系统 自己创建一个队列,然后把队列绑定到交换机,就可以创建了
没有耦合度了
某些系统不需要通知了,只要解除队列与交换机的绑定即可。
如果只是把数据发送到交换机,没有队列绑定交换价,那么消息会丢失。
交换机咩有存储消息的能力,只做交换,不做存储。
发一个消息,可以通知多个消费者
路由模式和 交换机模式 和 订阅模式 其实是一样的 只是交换机的类型不一样。
路由模式:
有选择的接收消息
路由模式 ,绑定多个路由键,再写一个就行
先启动消费者 会报错 因为没有 交换机。
通配符模式:
修改路由键:
将路由键和某模式进行匹配。此时队列需要绑定要一个模式上。符号“#”匹配一个或多个词,符号“*”匹配不多不少一个词。因此“audit.#”能够匹配到“audit.irs.corporate”,但是“audit.*” 只会匹配到“audit.irs”。
后台系统的配置文件
6、RabbitMQ集群
7、RabbitMQ集群处理问题
8、RabbitMQ镜像队列
9、RabbitMQ恢复故障
10、RabbitMQ Management插件 web
消息队列的安装:linux+windows
RabbitMQ的用户类型
2 使用了消息队列会有什么缺点?
分析:一个使用了MQ的项目,如果连这个问题都没有考虑过,就把MQ引进去了,那就给自己的项目带来了风险。我们引入一个技术,要对这个技术的弊端有充分的认识,才能做好预防。要记住,不要给公司挖坑!
回答:回答也很容易,从以下两个个角度来答
系统可用性降低:你想啊,本来其他系统只要运行好好的,那你的系统就是正常的。现在你非要加个消息队列进去,那消息队列挂了,你的系统不是呵呵了。因此,系统可用性降低
系统复杂性增加:要多考虑很多方面的问题,比如一致性问题、如何保证消息不被重复消费,如何保证保证消息可靠传输。因此,需要考虑的东西更多,系统复杂性增大。
但是,我们该用还是要用的。
11、消息队列比较
3、消息队列如何选型?
1、ActiveMQ
Apache出品。号称最流行的,能力强劲的开源消息总线。
特点有兼容常见J2EE服务器,支持Spring,Ajax
2、RabbitMQ
流行的、开源的消息队列。用AMQP(高级消息队列协议)标准实现。支持多种客户端,包括.Net,Java,PHP。
用于分布式系统中存储转发消息。易用性、扩展性、高可用性等方面表现不俗。
3、ZeroMQ
号称史上最快的消息队列,实际类似于Socket的一系列接口。普通Socket是端到端(1:1)的关系,而ZMQ是N:M。ZMQ屏蔽了各种连接的细节,让网络编程更简单。
用于node与node间的通信。node可以是主机或进程。
4、Kafka
高吞吐量的分布式发布订阅消息系统。
持久化
高吞吐
集群、分区
支持Hadoop

综合上面的材料得出以下两点:
(1)中小型软件公司,建议选RabbitMQ.一方面,erlang语言天生具备高并发的特性,而且他的管理界面用起来十分方便。正所谓,成也萧何,败也萧何!他的弊端也在这里,虽然RabbitMQ是开源的,然而国内有几个能定制化开发erlang的程序员呢?所幸,RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug,这点对于中小型公司来说十分重要。
不考虑rocketmq和kafka的原因是,一方面中小型软件公司不如互联网公司,数据量没那么大,选消息中间件,应首选功能比较完备的,所以kafka排除。
不考虑rocketmq的原因是,rocketmq是阿里出品,如果阿里放弃维护rocketmq,中小型公司一般抽不出人来进行rocketmq的定制化开发,因此不推荐。
(2)大型软件公司,根据具体使用在rocketMq和kafka之间二选一。一方面,大型软件公司,具备足够的资金搭建分布式环境,也具备足够大的数据量。
针对rocketMQ,大型软件公司也可以抽出人手对rocketMQ进行定制化开发,毕竟国内有能力改JAVA源码的人,还是相当多的。至于kafka,根据业务场景选择,如果有日志采集功能,肯定是首选kafka了。具体该选哪个,看使用场景。
4 如何保证消息队列是高可用的?
普通集群和镜像集群模式
5 如何保证消息不被重复消费?
分析:这个问题其实换一种问法就是,如何保证消息队列的幂等性?这个问题可以认为是消息队列领域的基本问题。换句话来说,是在考察你的设计能力,这个问题的回答可以根据具体的业务场景来答,没有固定的答案。
回答:先来说一下为什么会造成重复消费?
其实无论是那种消息队列,造成重复消费原因其实都是类似的。正常情况下,消费者在消费消息时候,消费完毕后,会发送一个确认信息给消息队列,消息队列就知道该消息被消费了,就会将该消息从消息队列中删除。只是不同的消息队列发送的确认信息形式不同,例如RabbitMQ是发送一个ACK确认消息,RocketMQ是返回一个CONSUME_SUCCESS成功标志,kafka实际上有个offset的概念,简单说一下(如果还不懂,出门找一个kafka入门到精通教程),就是每一个消息都有一个offset,kafka消费过消息后,需要提交offset,让消息队列知道自己已经消费过了。那造成重复消费的原因?,就是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将该消息分发给其他的消费者。
如何解决?这个问题针对业务场景来答分以下几点
(1)比如,你拿到这个消息做数据库的insert操作。那就容易了,给这个消息做一个唯一主键,那么就算出现重复消费的情况,就会导致主键冲突,避免数据库出现脏数据。
(2)再比如,你拿到这个消息做redis的set的操作,那就容易了,不用解决,因为你无论set几次结果都是一样的,set操作本来就算幂等操作。
(3)如果上面两种情况还不行,上大招。准备一个第三方介质,来做消费记录。以redis为例,给消息分配一个全局id,只要消费过该消息,将<id,message>以K-V形式写入redis。那消费者开始消费前,先去redis中查询有没消费记录即可。
6 如何保证消费的可靠性传输?
分析:我们在使用消息队列的过程中,应该做到消息不能多消费,也不能少消费。如果无法做到可靠性传输,可能给公司带来千万级别的财产损失。同样的,如果可靠性传输在使用过程中,没有考虑到,这不是给公司挖坑么,你可以拍拍屁股走了,公司损失的钱,谁承担。还是那句话,认真对待每一个项目,不要给公司挖坑。
回答:其实这个可靠性传输,每种MQ都要从三个角度来分析:生产者弄丢数据、消息队列弄丢数据、消费者弄丢数据
RabbitMQ
(1)生产者丢数据
从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm模式来确保生产者不丢消息。
transaction机制就是说,发送消息前,开启事务(channel.txSelect()),然后发送消息,如果发送过程中出现什么异常,事物就会回滚(channel.txRollback()),如果发送成功则提交事物(channel.txCommit())。
然而缺点就是吞吐量下降了。因此,按照博主的经验,生产上用confirm模式的居多。一旦channel进入confirm模式,所有在该信道上面发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后,rabbitMQ就会发送一个Ack给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了.如果rabiitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。处理Ack和Nack的代码如下所示(说好不上代码的,偷偷上了):
channel.addConfirmListener(new ConfirmListener() {
@Override
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("nack: deliveryTag = "+deliveryTag+" multiple: "+multiple);
}
@Override
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
System.out.println("ack: deliveryTag = "+deliveryTag+" multiple: "+multiple);
}
});
(2)消息队列丢数据
处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
那么如何持久化呢,这里顺便说一下吧,其实也很容易,就下面两步
1、将queue的持久化标识durable设置为true,则代表是一个持久的队列
2、发送消息的时候将deliveryMode=2
这样设置以后,rabbitMQ就算挂了,重启后也能恢复数据
(3)消费者丢数据
消费者丢数据一般是因为采用了自动确认消息模式。这种模式下,消费者会自动确认收到信息。这时rahbitMQ会立即将消息删除,这种情况下如果消费者出现异常而没能处理该消息,就会丢失该消息。
至于解决方案,采用手动确认消息即可。
7 如何保证消息的顺序性?
分析:其实并非所有的公司都有这种业务需求,但是还是对这个问题要有所复习。
回答:针对这个问题,通过某种算法,将需要保持先后顺序的消息放到同一个消息队列中(kafka中就是partition,rabbitMq中就是queue)。然后只用一个消费者去消费该队列。
有的人会问:那如果为了吞吐量,有多个消费者去消费怎么办?
这个问题,没有固定回答的套路。比如我们有一个微博的操作,发微博、写评论、删除微博,这三个异步操作。如果是这样一个业务场景,那只要重试就行。比如你一个消费者先执行了写评论的操作,但是这时候,微博都还没发,写评论一定是失败的,等一段时间。等另一个消费者,先执行写评论的操作后,再执行,就可以成功。
总之,针对这个问题,我的观点是保证入队有序就行,出队以后的顺序交给消费者自己去保证,没有固定套路。
RabbitMQ知识详解:
https://blog.csdn.net/dreamchasering/article/details/77653512
4.任务分发机制
4.1Round-robin dispathching循环分发
RabbbitMQ的分发机制非常适合扩展,而且它是专门为并发程序设计的,如果现在load加重,那么只需要创建更多的Consumer来进行任务处理。
4.2Message acknowledgment消息确认
为了保证数据不被丢失,RabbitMQ支持消息确认机制,为了保证数据能被正确处理而不仅仅是被Consumer收到,那么我们不能采用no-ack,而应该是在处理完数据之后发送ack.
在处理完数据之后发送ack,就是告诉RabbitMQ数据已经被接收,处理完成,RabbitMQ可以安全的删除它了.
如果Consumer退出了但是没有发送ack,那么RabbitMQ就会把这个Message发送到下一个Consumer,这样就保证在Consumer异常退出情况下数据也不会丢失.
RabbitMQ它没有用到超时机制.RabbitMQ仅仅通过Consumer的连接中断来确认该Message并没有正确处理,也就是说RabbitMQ给了Consumer足够长的时间做数据处理。
如果忘记ack,那么当Consumer退出时,Mesage会重新分发,然后RabbitMQ会占用越来越多的内存.
5.Message durability消息持久化
要持久化队列queue的持久化需要在声明时指定durable=True;
这里要注意,队列的名字一定要是Broker中不存在的,不然不能改变此队列的任何属性.
队列和交换机有一个创建时候指定的标志durable,durable的唯一含义就是具有这个标志的队列和交换机会在重启之后重新建立,它不表示说在队列中的消息会在重启后恢复
消息持久化包括3部分
1. exchange持久化,在声明时指定durable => true
hannel.ExchangeDeclare(ExchangeName, "direct", durable: true, autoDelete: false, arguments: null);//声明消息队列,且为可持久化的
- 1
2.queue持久化,在声明时指定durable => true
channel.QueueDeclare(QueueName, durable: true, exclusive: false, autoDelete: false, arguments: null);//声明消息队列,且为可持久化的
- 1
3.消息持久化,在投递时指定delivery_mode => 2(1是非持久化).
channel.basicPublish("", queueName, MessageProperties.PERSISTENT_TEXT_PLAIN, msg.getBytes());
- 1
如果exchange和queue都是持久化的,那么它们之间的binding也是持久化的,如果exchange和queue两者之间有一个持久化,一个非持久化,则不允许建立绑定.
注意:一旦创建了队列和交换机,就不能修改其标志了,例如,创建了一个non-durable的队列,然后想把它改变成durable的,唯一的办法就是删除这个队列然后重现创建。
6.Fair dispath 公平分发
你可能也注意到了,分发机制不是那么优雅,默认状态下,RabbitMQ将第n个Message分发给第n个Consumer。n是取余后的,它不管Consumer是否还有unacked Message,只是按照这个默认的机制进行分发.
那么如果有个Consumer工作比较重,那么就会导致有的Consumer基本没事可做,有的Consumer却毫无休息的机会,那么,Rabbit是如何处理这种问题呢?
通过basic.qos方法设置prefetch_count=1,这样RabbitMQ就会使得每个Consumer在同一个时间点最多处理一个Message,换句话说,在接收到该Consumer的ack前,它不会将新的Message分发给它
channel.basic_qos(prefetch_count=1)
- 1
注意,这种方法可能会导致queue满。当然,这种情况下你可能需要添加更多的Consumer,或者创建更多的virtualHost来细化你的设计。
7.分发到多个Consumer
7.1Exchange
先来温习以下交换机路由的几种类型:
Direct Exchange:直接匹配,通过Exchange名称+RountingKey来发送与接收消息.
Fanout Exchange:广播订阅,向所有的消费者发布消息,但是只有消费者将队列绑定到该路由器才能收到消息,忽略Routing Key.
Topic Exchange:主题匹配订阅,这里的主题指的是RoutingKey,RoutingKey可以采用通配符,如:*或#,RoutingKey命名采用.来分隔多个词,只有消息这将队列绑定到该路由器且指定RoutingKey符合匹配规则时才能收到消息;
Headers Exchange:消息头订阅,消息发布前,为消息定义一个或多个键值对的消息头,然后消费者接收消息同时需要定义类似的键值对请求头:(如:x-mactch=all或者x_match=any),只有请求头与消息头匹配,才能接收消息,忽略RoutingKey.
默认的exchange:如果用空字符串去声明一个exchange,那么系统就会使用”amq.direct”这个exchange,我们创建一个queue时,默认的都会有一个和新建queue同名的routingKey绑定到这个默认的exchange上去
channel.BasicPublish("", "TaskQueue", properties, bytes);
- 1
因为在第一个参数选择了默认的exchange,而我们申明的队列叫TaskQueue,所以默认的,它在新建一个也叫TaskQueue的routingKey,并绑定在默认的exchange上,导致了我们可以在第二个参数routingKey中写TaskQueue,这样它就会找到定义的同名的queue,并把消息放进去。
如果有两个接收程序都是用了同一个的queue和相同的routingKey去绑定direct exchange的话,分发的行为是负载均衡的,也就是说第一个是程序1收到,第二个是程序2收到,以此类推。
如果有两个接收程序用了各自的queue,但使用相同的routingKey去绑定direct exchange的话,分发的行为是复制的,也就是说每个程序都会收到这个消息的副本。行为相当于fanout类型的exchange。
下面详细来说:
8.消息序列化
RabbitMQ使用ProtoBuf序列化消息,它可作为RabbitMQ的Message的数据格式进行传输,由于是结构化的数据,这样就极大的方便了Consumer的数据高效处理,当然也可以使用XML,与XML相比,ProtoBuf有以下优势:
1.简单
2.size小了3-10倍
3.速度快了20-100倍
4.易于编程
6.减少了语义的歧义.
,ProtoBuf具有速度和空间的优势,使得它现在应用非常广泛
rabbitMQ教程(三)一篇文章看懂rabbitMQ
一、rabbitMQ是什么:
RabbitMQ,遵循AMQP协议,由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。
学过websocket的来理解rabbitMQ应该是非常简单的了,websocket是基于服务器和页面之间的通信协议,一次握手,多次通信。 而rabbitMQ就像是服务器之间的socket,一个服务器连上MQ监听,而另一个服务器只要通过MQ发送消息就能被监听服务器所接收。
但是MQ和socket还是有区别的,socket相当于是页面直接监听服务器。而MQ就是服务器之间的中转站,例如邮箱,一个人投递信件给邮箱,另一个人去邮箱取,他们中间没有直接的关系,所以耦合度相比socket小了很多。
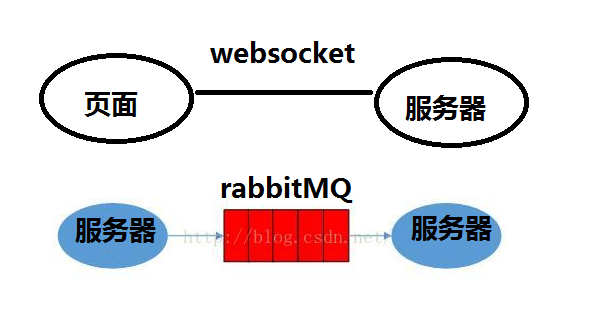
上图是最简单的MQ关系,生产者-MQ队列-消费者
五、一些细节说明
MQ不能进行批量的消息处理,你看到的传输再多也只是消息被一条一条的存入队列,消费者从队列中一条一条的取出。这kafKa有区别,所以在效率上比不上kafKa,但是MQ主打的是稳定。
每次消费者取出消息时会通知队列,我拿到了,当队列接收到这条消息,就会把消息删除,这是默认的ACK机制。如果在接收消息之后,消费者挂掉,或者任何情况没有返回ack,队列中这条消息将不会删除,可以一直存着,等待其他消费者来取。 注意,但是如果设置不返回ack,在不断的发送消息到队列又不删除,会导致MQ仓库boom~~~~
关于秒杀的系统架构优化思路 http://www.cnblogs.com/chenpingzhao/p/6195788.html
浅谈库存扣减相关问题 https://blog.csdn.net/xiongyouqiang/article/details/79388120
定时任务:MQ
RabbitMQ权限系统。
管理用户
RabbitMQ 整合 spring
RabbitMQ整合 spring-boo
消费者的优先级
Ttl
交换机到交换机的绑定
Rabbitmq事务
消息确认
幂等性
定时任务 quartz
Spring-boot的定时任务
RabbitMQ-exchangeDeclare()方法:
exchange: 交换器名称
type : 交换器类型 DIRECT("direct"), FANOUT("fanout"), TOPIC("topic"), HEADERS("headers");
durable: 是否持久化,durable设置为true表示持久化,反之是非持久化,持久化的可以将交换器存盘,在服务器重启的时候不会丢失信息.
autoDelete是否自动删除,设置为TRUE则表是自动删除,自删除的前提是至少有一个队列或者交换器与这交换器绑定,之后所有与这个交换器绑定的队列或者交换器都与此解绑,一般都设置为fase
internal 是否内置,如果设置 为true,则表示是内置的交换器,客户端程序无法直接发送消息到这个交换器中,只能通过交换器路由到交换器的方式
arguments:其它一些结构化参数比如:alternate-exchange
如果到此交换器的消息不能以其他方式路由,则将它们发送到这里命名的备用交换器。
(设置“交互交换”参数。)
rabbitMQ-queueDeclare()方法:
queueDeclare(String queue, boolean durable,boolean exclusive, Map<String, Object> arguments);
queue: 队列名称
durable: 是否持久化, 队列的声明默认是存放到内存中的,如果rabbitmq重启会丢失,如果想重启之后还存在就要使队列持久化,保存到Erlang自带的Mnesia数据库中,当rabbitmq重启之后会读取该数据库 (true为持久化)
exclusive:是否排外的,有两个作用,
一:当连接关闭时connection.close()该队列是否会自动删除;
二:该队列是否是私有的private,
如果不是排外的,可以使用两个消费者都访问同一个队列,没有任何问题,
如果是排外的,会对当前队列加锁,其他通道channel是不能访问的,如果强制访 问会报异常:com.rabbitmq.client.ShutdownSignalException: channel error; protocol method: #method(reply-code=405, reply-text=RESOURCE_LOCKED - cannot obtain exclusive access to locked queue 'queue_name' in vhost '/', class-id=50, method-id=20)
一般等于true的话用于一个队列只能有一个消费者来消费的场景
autoDelete:是否自动删除,当最后一个消费者断开连接之后队列是否自动被删除,可以通过RabbitMQ Management,查看某个队列的消费者数量,当consumers = 0时队列就会自动删除
arguments: 队列中的消息什么时候会自动被删除?
Message TTL(x-message-ttl):设置队列中的所有消息的生存周期(统一为整个队列的所有消息设置生命周期), 也可以在发布消息的时候单独为某个消息指定剩余生存时间,单位毫秒, 类似于redis中的ttl,生存时间到了,消息会被从队里中删除,注意是消息被删除,而不是队列被删除, 特性Features=TTL, 单独为某条消息设置过期时间AMQP.BasicProperties.Builder properties = new AMQP.BasicProperties().builder().expiration(“6000”); channel.basicPublish(EXCHANGE_NAME, “”, properties.build(), message.getBytes(“UTF-8”));
Auto Expire(x-expires): 当队列在指定的时间没有被访问(consume, basicGet, queueDeclare…)就会被删除,Features=Exp
Max Length(x-max-length): 限定队列的消息的最大值长度,超过指定长度将会把最早的几条删除掉, 类似于mongodb中的固定集合,例如保存最新的100条消息, Feature=Lim Max Length
Bytes(x-max-length-bytes): 限定队列最大占用的空间大小, 一般受限于内存、磁盘的大小, Features=Lim B
Dead letter exchange(x-dead-letter-exchange): 当队列消息长度大于最大长度、或者过期的等,将从队列中删除的消息推送到指定的交换机中去而不是丢弃掉,Features=DLX
Dead letter routing key(x-dead-letter-routing-key):将删除的消息推送到指定交换机的指定路由键的队列中去, Feature=DLK
Maximum priority(x-max-priority):优先级队列,声明队列时先定义最大优先级值(定义最大值一般不要太大),在发布消息的时候指定该消息的优先级, 优先级更高(数值更大的)的消息先被消费,
Lazy mode(x-queue-mode=lazy): Lazy Queues: 先将消息保存到磁盘上,不放在内存中,当消费者开始消费的时候才加载到内存中
Master locator(x-queue-master-locator) 设置集群的主队列
idea中@Data标签getset不起作用
spring cloud中使用@Data标签,不用手动添加get set方法,但是如果项目中其他类中使用getset方法,如果报错,原因是idea中没有添加Lombok插件,添加上插件便可以解决。截图如下
@Controller和@RestController的区别?
知识点:@RestController注解相当于@ResponseBody + @Controller合在一起的作用。
1) 如果只是使用@RestController注解Controller,则Controller中的方法无法返回jsp页面,或者html,配置的视图解析器 InternalResourceViewResolver不起作用,返回的内容就是Return 里的内容。
2) 如果需要返回到指定页面,则需要用 @Controller配合视图解析器InternalResourceViewResolver才行。
如果需要返回JSON,XML或自定义mediaType内容到页面,则需要在对应的方法上加上@ResponseBody注解。
例如:
1.使用@Controller 注解,在对应的方法上,视图解析器可以解析return 的jsp,html页面,并且跳转到相应页面
若返回json等内容到页面,则需要加@ResponseBody注解
Nginx:
Nginx和tomcat对比:在web1.0时代,并发量小,用户少。用户直接访问tomcat是没有问题的。
Web2.0时代,信息量爆炸,渐渐出现了高并发的问题,一个tomcat承载不了这些访问量,需要同时使用多个tomcat,nginx就可以把这多个tomcat统一代理对外开放为一个端口地址
nginx更加擅长静态资源的处理服务,将项目的静态资源统一放在静态服务器,提高访问效率。
为什么要使用代理服务器?
(1)提高访问速度
由于目标主机返回的数据会存放在代理服务器的硬盘中,因此下一次客户再访问相同的站点数据时,会直接从代理服务器的硬盘中读取,起到了缓存的作用,尤其对于热门站点能明显提高请求速度。
(2)nginx的一些特性可以保住脆弱的java服务器。
(3)nginx用于提供静态页面服务,比java服务器要强。
Nginx特点:
(1)跨平台:Nginx 可以在大多数 Unix like OS编译运行,而且也有Windows的移植版本。
(2)配置异常简单,非常容易上手。配置风格跟程序开发一样,神一般的配置
(3)非阻塞、高并发连接:数据复制时,磁盘I/O的第一阶段是非阻塞的。官方测试能够支撑5万并发连接,在实际生产环境中跑到2~3万并发连接数.(这得益于Nginx使用了最新的epoll模型)
(4)事件驱动:通信机制采用epoll模型,支持更大的并发连接。
(5)master/worker结构:一个master进程,生成一个或多个worker进程
(6)内存消耗小:处理大并发的请求内存消耗非常小。在3万并发连接下,开启的10个Nginx 进程才消耗150M内存(15M*10=150M)
(7)成本低廉:Nginx为开源软件,可以免费使用。而购买F5 BIG-IP、NetScaler等硬件负载均衡交换机则需要十多万至几十万人民币
(8)内置的健康检查功能:如果 Nginx Proxy 后端的某台 Web 服务器宕机了,不会影响前端访问。
(9)节省带宽:支持 GZIP 压缩,可以添加浏览器本地缓存的 Header 头。
(10)稳定性高:用于反向代理,宕机的概率微乎其微
Nginx三大核心功能:
(一)反向代理:
反向代理是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
正向代理客户端必须设置正向代理服务器,当然前提是要知道正向代理服务器的IP地址,还有代理程序的端口。
反向代理正好与正向代理相反,对于客户端而言代理服务器就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理的命名空间中的内容发送普通请求,接着反向代理将判断向哪个原始服务器转交请求,并将获得的内容返回给客户端。
反向代理服务器通常有两种模型,它可以作为内容服务器的替身,也可以作为内容服务器集群的负载均衡器:
作为内部服务器替身就是代理域名直接去代理后台服务器tomcat等
内部服务器负载均衡,同时代理几台tomcat服务器
(二)负载均衡
为什么解决负载均衡:
(1)解决并发压力,提高应用处理性能(增加吞吐量,加强网络处理能力)
(2)提供故障转移,实现高可用
(3)通过添加或减少服务器数量,提供网站伸缩性(扩展性)
什么是负载均衡:
负载均衡指的是多个服务器共同完成一件事情,核心是“分摊压力”。Ngnix实现负载均衡指的是将请求转发给服务器集群。Ngnix默认处理负载均衡的方式是“轮询”,我们可以通过weight来调整权重。
Nginx负载均衡的方式:
1、轮询(默认)
2、weight(轮询权值)
3、ip_hash
4、fair(第三方)
5、url_hash(第三方)
(三)动静分离
动静分离的优点,配置动静分离
为什么动静分离?
1.分担服务器压力,动态请求和静态请求都是tomcat,静态资源请求处理速度效率很低,将静态文件放到另一个服务器增加访问效率,便于维护。
2.Nginx很容易构造一个静态内容的服务,提供一个静态站点的服务器。
动静分离的概念和作用:
为了提高网站的响应速度,减轻程序服务器(Tomcat,Jboss等)的负载对于静态资源比如图片,js,css等文件,我们可以在反向代理服务器中进行缓存,这样浏览器在请求一个静态资源时,代理服务器就可以直接处理,而不用将请求转发给后端服务器。用户请求的动态文件比如servlet,jsp则转发给Tomcat,Jboss服务器处理,这就是动静分离。这也是反向代理服务器的一个重要的作用。
代理服务器和静态服务器即为一台服务器上,这里只是为了明显区分动静分离所处服务器的不同;
静态服务器中,存放的资源主要是源代码文件、图片、属性、样式以及其它所有非动态的资源文件;
动静分离在前后端分离的项目契合度更高,更能够发挥它的优势,
高并发:
高并发简单来说就是在同一时刻不同用户访问同一资源的问题,专业点的说法就是同一时刻有多个线程访问同一个数据资源。
Nginx的高并发处理:
nginx的高并发就是通过worker的抢占机制同时搭配了异步非阻塞方式来实现的。
主进程只进行监听,请求等处理都是在工作进程完成的。当工作进程得到客户端的请求时,对请求并不是一次性处理完,而只是处理一部分,处理到请求阻塞的时候,工作进程不会一直等着该请求阻塞完成,而是会去做其他客户的请求,这个切换是客户请求主动让出的,不需要任何代价。这样就实现了一个工作进程可以同时处理多个客户端的请求。从而实现高并发。
进程模型:
nginx在启动后,会有一个master进程和多个worker进程。master进程主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。而基本的网络事件,则是放在worker进程中来处理了。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的。一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致,这里面的原因与nginx的进程模型以及事件处理模型是分不开的。
nginx采用这种进程模型有什么好处呢?
首先,对于每个worker进程来说,独立的进程,不需要加锁,所以省掉了锁带来的开销,同时在编程以及问题查上时,也会方便很多。其次,采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master进程则很快重新启动新的worker进程。当然,worker进程的异常退出,肯定是程序有bug了,异常退出,会导致当前worker上的所有请求失败,不过不会影响到所有请求,所以降低了风险
Nginx事件模型:
异步非阻塞:
Nginx采取异步非阻塞的方式处理请求。
处理请求流程:收到请求,建立连接,接收数据,发送数据。
如果采用阻塞调用,会陷入内核等待,在单进程的nginx下这样cpu就会空闲,没法充分使用。
采用非阻塞调用,会在事件没有准备好时,返回EAGAIN来通知,此时线程还可以做其他事情,然后再回来查看事件是否准备完成。这种情况下的消耗也比较大。
异步非阻塞调用是一种机制,可以同时监控多个事件,调用他们是阻塞的,但是可以设置超时时间,在超时时间内,如果有事件处理好了,就返回。以epoll为例,当事件没有准备好时,放到epoll中,事件准备好了,就去处理它,只有当所有的事件都没准备好时,才会在epoll里面等待。这样就可以处理大量未完成的并发事件。
线程只有一个,所以同时能处理的请求只有一个,只是在请求间不断地切换而已,切换也是因为事件未准备好而主动让出,没有任何代价。
异步非阻塞时间处理机制:
让你可以同时监控多个事件,调用他们是阻塞的,但可以设置超时时间,在超时时间之内,如果有事件准备好了,就返回。当事件没准备好时,放到epoll里面,事件准备好了,我们就去读写,写返回EAGAIN时,我们将它再次加入到epoll里面。这样,只要有事件准备好了,我们就去处理它,只有当所有事件都没准备好时,才在epoll里面等着。这样,我们就可以并发处理大量的并发了,当然,这里的并发请求,是指未处理完的请求,线程只有一个,所以同时能处理的请求当然只有一个了,只是在请求间进行不断地切换而已,切换也是因为异步事件未准备好,而主动让出的。
与多线程相比,这种事件处理方式是有很大的优势的,不需要创建线程,每个请求占用的内存也很少,没有上下文切换,事件处理非常的轻量级。并发数再多也不会导致无谓的资源浪费(上下文切换)
Spring cloud:
Spring cloud简介:
基于SpringBoot 提供一套微服务解决方案,包括服务注册与发现,配置中心,全链路监控,服务网管,负载均衡,熔断器等组件。除了NetFlix的开源组件做高度抽象封装之外,还有一些中立的开源组件。
利用SpringBoot的开发遍历性技巧,分布式系统基础设施的开发。包括配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等,它们都可以用SpringBoot的开发风格做到一键启动和部署。
微服务:
微服务的核心就是将传统的一站式应用根据业务拆成一个一个的服务,彻底的去耦合,每一个微服务提供单个业务功能的服务,一个服务做一件事情,从技术角度看就是一种小而独立的处理过程,类似于进程的概念,能够自行单独启动或销毁,拥有自己独立的数据库。
微服务条目 技术
服务开发 Springboot、Spring、SpringMVC
服务配置与管理 Netflix公司的Archaius、阿里的Diamond等
服务注册与发现 Eureka、Consul、Zookeeper等
服务调用 Rest、RPC、gRPC
服务熔断器 Hystrix、Envoy等
负载均衡 Ribbon、Nginx等
服务接口调用(客户端调用服务的简化工具) Feign等
消息队列 Kafka、RabbitMQ、ActiveMQ等
服务配置中心管理 SpringCloudConfig、Chef等
服务路由(API网关) Zuul等
服务监控 Zabbix、Nagios、Metrics、Spectator等
全链路追踪 Zipkin,Brave、Dapper等
服务部署 Docker、OpenStack、Kubernetes等
数据流操作开发包 SpringCloud Stream(封装与Redis,Rabbit、Kafka等发送接收消息)
事件消息总线 Spring Cloud Bus
Spring cloud和boot的关系:
Springboot专注于快读方便的开发单个个体微服务。
Springcloud是关注全局的微服务协调整理治理框架,他将springboot开发的一个个单个微服务整合并管理起来,为各个微服务之间提供了配置管理,服务发现,断路器,路由,微代理,时间总线,全局锁,决策精选,分布会话等等集成服务。
Springboot可以离开springcloud独立开发,但是cloud离不开springboot,属于依赖关系。
Springboot专注于快速、方便的开发单个微服务个体,springcloud专注于全局的服务治理框架。
Springcloud的作用:
Spring cloud是一系列框架的有序集合。利用springboot开发遍历的技巧,简化了分布式系统基础设施开发。Spring cloud就是微服务的大管家,采用微服务的框架之后,项目的数量非常多,springcloud作为大管家就需要提供各种方案来维护整个生态。
SpringCloud的核心特性:
- 分布式/版本化配置
- 服务注册和发现
- 路由
- 服务和服务之间的调用
- 负载均衡
- 断路器
- 分布式消息传递
Eureka:
简介:Eureka主要实现了服务注册和发现。(zookeeper)
Eureka采用了C-S的设计架构。EurekaServer 作为服务注册功能的服务器,他是服务注册中心。
系统中的其他微服务,使用Eureka的客户端连接到Eureka Server并维持心跳连接,这样系统维护人员可以通过Eureka来监控系统中各个微服务是否正常运行,Cloud其他模块可以通过Eurake来发现系统中哦你的其他微服务,并执行相应逻辑。
Eureka组件:Eureka Server 和Eureka Client
Eureka Server提供服务注册服务
各个节点启动后,会在EurekaServer中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到
EurekaClient是一个Java客户端,用于简化Eureka Server的交互,客户端同时也具备一个内置的、使用轮询(round-robin)负载算法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳(默认周期为30秒)。如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,EurekaServer将会从服务注册表中把这个服务节点移除(默认90秒)
Zookeeper和Eureka:
Zookeeper保证CP。当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟前的注册信息,但不能接受直接挂掉不可用。因此,服务注册中心对可用性的要求高于一致性。但是,因网络问题导致的zookeeper集群式去master节点的概率较大,虽然服务器最终恢复,但漫长的选举时间导致注册服务长期不可用是不可容忍的。
Eureka保证AP。在设计上Eureka优先保证了可用性。EurekaServer各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余节点依然可以提供注册和发现服务。而Eureka客户端在想某个server注册或发现链接失败时,会自动切换到其他server节点,只要有一台server正常运行,就能保证注册服务可用,只不过查询到的信息不一定是最新的。
Eureka还有一种自我保护机制,如果15分钟内超过85%的节点都没有正常心跳,那么EurekaServer将认为客户端和注册中心网络故障,此时:1、Eurekaserver不再从注册列表中移除因为长时间没有收到心跳而应该过期的服务。2.EurekaServer仍能够接受新服务的注册查询请求,但不会被同步到其他节点上当网络稳定时,当前EurekaServer节点新的注册信息会同步到其他节点中。因此,Eureka可以很好的应对因网络故障导致部分节点式去联系的情况,而不会像Zooper那样整个服务瘫痪。
Eureka配置:
依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
配置yml:
server:
port: 7001
eureka:
instance:
hostname: localhost #eureka服务端的实例名称
client:
register-with-eureka: false #false表示不向注册中心注册自己。
fetch-registry: false #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
service-url:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
添加启动类注解:
@EnableEurekaServer
Eureka客户端配置:
添加依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
添加启动类注解:
@EnableEurekaClient
YML:
server:
port: 8001
mybatis:
config-location: classpath:mybatis/mybatis.cfg.xml # mybatis配置文件所在路径
type-aliases-package: com.atguigu.springcloud.entities # 所有Entity别名类所在包
mapper-locations:
- classpath:mybatis/mapper/**/*.xml # mapper映射文件
spring:
application:
name: microservicecloud-dept
client: #客户端注册进eureka服务列表内
service-url:
defaultZone: http://localhost:7001/eureka
Feign:
Feign简介:Feign是一个声明式的Web Service客户端,它使得编写Web Serivce客户端变得更加简单。我们只需要使用Feign来创建一个接口并用注解来配置它既可完成。它具备可插拔的注解支持,包括Feign注解和JAX-RS注解。Feign也支持可插拔的编码器和解码器。Spring Cloud为Feign增加了对Spring MVC注解的支持,还整合了Ribbon和Eureka来提供均衡负载的HTTP客户端实现。
Feign通过接口的方法调用Rest服务,该请求发送到Eureka服务器,通过Feign直接找到服务接口。由于在进行服务调用的时候融合了Ribbon技术,所以也支持了负载均衡。
Feign的实现:
依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-feign</artifactId>
</dependency>
添加启动类注解:
@EnableDiscoveryClient
@EnableFeignClients
服务雪崩:
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”.
雪崩原因:硬件故障,负载过大(双11),代码问题.
熔断器:它可以实现快速失败,如果他在一段时间内侦测到许多类似的错误,会强迫其以后的多个调用快速失败,不再访问远程服务器,从而防止应用程序不断尝试执行可能会失败的操作,使应用程序继续执行而不用等待修正错误,或者浪费CPU时间去等到长时间的超时产生。熔断器也可以使硬哟娜程序能够诊断错误是否修正,如果已修正,应用程序会再次尝试调用操作。
Hystrix:
Hystrix特性:
1.断路器机制。 当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务. 断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN). 这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN). Hystrix的断路器就像我们家庭电路中的保险丝, 一旦后端服务不可用, 断路器会直接切断请求链, 避免发送大量无效0203. 。
你请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力.
2.Fallback
Fallback相当于降级操作,对于查询操作。我们可以实现一个fallback方法,当请求后端服务出现异常的时候,可以使用fallback方法返回的值,fallback方法的返回值一般是设置的默认值或来自缓存。
服务降级:
yml添加节点
feign:
hystrix:
enabled: true
继承并实现生产者接口
value=指定生产者服务名字 fallbackFactory=实现类的全限定名
@FeignClient(value = "MICROSERVICDEPT",fallbackFactory=DeptClientServiceFallbackFactory.class
3.资源隔离
在Hystrix中,主要通过线程池来实现资源隔离,通常使用的时候我们会根据调用的远程服务划分出多个线程池,这样做主要优点是运行环境被隔离开,这样就算调用服务的代码存在bug或优于其他原因导致自己所在的线程池被耗尽时,不会对系统的其他服务造成影响,但是带来的代价就是维护多个线程池会对系统带来额外的性能开销,如果对性能有严格要求而且确信自己调用服务的客户端代码不会出现的话,可以使用Hystrix的信号模式来隔离资源。
Hystrix监控:
依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artfactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
添加注解:
@EnableCircuitBreaker
启动服务器查看监控数据:
访问/hystrix.stream端点 比如:http://localhost:5001/hystrix.stream
先访问服务中的任意接口,然后访问/hystrix.stream端点才会显示对应的接口监控数据。
Hystrix的监控是以文字形式展现的,不方便分析。Hystrix Dashboard可视化监控。
添加依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix-dashboard</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
添加注释:
@EnableHystrixDashboard,启用Hystrix Dashboard功能。
启动服务器查看监控数据,访问当前节点。
Ribbon:
简介:
Spring cloud Ribbon 是基于Netflix Ribbon实现的一套客户端负载均衡工具。简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法,将Netflix的中间层服务连接在一起。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。我们也很容易使用Ribbon实现自定义的负载均衡算法。
通过配置方式更爱负载均衡策略:
为consumer项目添加配置:
(yml)
dm-user-provider:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
其他负载均衡策略均定义在com.netflix.loadbalancer包中,可以根据需要选择合适的策略。
Zuul微服务网关:
简介:Zuul作为边界应用服务,zuul能实现动态路由、监控、弹性与安全性。
Zuul实现:
创建项目
添加Zuul依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.3.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zuul</artifactId>
<version>1.3.5.RELEASE</version>
</dependency>
修改配置指定服务端口、Eureka Server地址等信息
spring:
application:
name: dm-gateway-zuul
server:
port: 7600
eureka:
client:
service-url:
defaultZone: http://localhost:7776/eureka/
添加注解
@EnableZuulProxy
配置zuul网关过滤器:
微服务名: 映射路径
zuul:
routes:
dm-user-consumer: /user/**
strip-prefix: false
每个服务在处理请求的时候都要判断是否验证token
需要验证token是否有效
效率低
每个请求都需要转发到具体的微服务后再判断,然后将判断的结果回转给网关
在网关转发前就行进过滤处理
过滤器
创建过滤器
继承ZuulFilter
重写方法
filterType():过滤器类型
filterOrder():过滤顺序
shouldFilter():是否进行拦截过滤
run():确定需要拦截之后执行的方法
分布式总配置:
每个服务都有自己的配置文件,很多公共的配置信息更改配置信息都需要重新发布服务
Spring Cloud Config
公共信息都保存到远程仓库
连接Config Server,无需重启更新配置参数
统一加密解密
创建项目
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
<version>1.3.5.RELEASE</version>
</dependency>
添加注解
@EnableConfigServer
@EnableDiscoveryClient
Yml:
server:
port: 7900
spring:
cloud:
config:
server:
git:
uri: Git仓库地址
username: 账号名称
password: 账号密码
search-paths: config-repo
application:
name: dm-config-server
eureka:
client:
service-url:
defaultZone: http://root:123456@localhost:7776/eureka/
启动服务
访问端点
http://localhost:7900/client/dev/sprint2.0_dev
映射规则:/{application}/{profile}/{label}
{application}:Git仓库中文件名的前缀, 通常使用微服务名称
{profile}:{application}-后面的数值
在同一个分支下可以有多个{application}名称相同的文件
{label}:Git仓库的分支名,默认为maste
创建远程配置文件:
dm-gateway-zuul-dev.properties
添加依赖:
为Zuul网关项目dm-gateway-zuul添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
编写Config Client:
spring:
application:
#对应映射规则中的{application}部
name: dm-gateway-zuul
cloud:
config:
#对应映射规则中的{label}部分
label: sprint2.0_dev
#对应Config Server的地址
#对应映射规则中的{profile}部分
profile: dev
eureka:
client:
service-url:
defaultZone:http://root:123456@localhost:7776/eureka/
配置refresh:
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
添加注解
@RefreshScope
添加配置
management:
security:
enabled: false
访问刷新端点http://localhost:7900/refresh
使用Sleuth微服务跟踪:
添加依赖,整合Sleuth
在前面示例的基础上,为 provider、consumer项目添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>1.2.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
修改配置文件
修改consumer项目的application.yml文件,在其中设置日志级别为info
server:
port: 8080
spring:
application:
name: dm-user-consumer
eureka:
client:
service-url:
defaultZone: http://root:123456@localhost:7776/eureka/
logging:
level: info
配置Zipkin Server:
创建项目
指定artifactId为sleuth
添加注解
@EnableZipkinServer
添加依赖
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
分别修改consumer、provider 的application.yml,在其中指定Zipkin Server地址和采样率
spring:
zipkin:
base-url: http://localhost:7777
sleuth:
sampler:
percentage: 1.0
在开发、测试中配置文件中的spring.sleuth.sampler.percentage属性设置为1.0,代表100%采样,否则可能会忽略掉大量span,可能看不到想要查看的请求