1. 模型性能评价及选择
看下sklearn中支持哪些机器学习的评估指标:
from sklearn.metrix import SCORERS SCORERS
1.1回归模型性能评价及选择


1.1.1Mean Absolute Error 平均绝对误差(MAE)
损失函数没有用这个,是因为绝对值不方便求导

1.1.2Mean Squared Error 均方误差(MSE)

1.1.3Root Mean Squared Error:均方根误差(RMS)
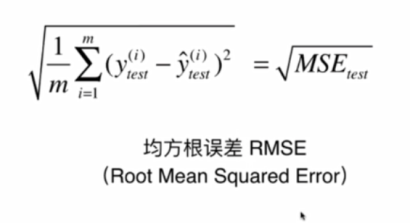
https://zhuanlan.zhihu.com/p/36326966
优缺点:在不同的物品中无法衡量好坏
1.1.4Coefficient of determination 决定系数(R2和调整R2)
R2方法是将预测值跟只使用均值的情况下相比,看能好多少。其区间通常在(0,1)之间。0表示还不如什么都不预测,直接取均值的情况,而1表示所有预测跟真实结果完美匹配的情况。

R方的意义:
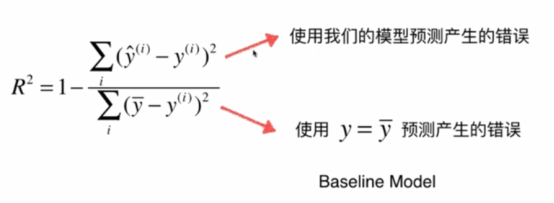
注意:
- R^2<=1
- R^2越大越好,当我们的模型不犯任何错误,R^2=1
- 当我们的模型等于基模型的时候,R^2=0
- 如果R^2<0 ,说明我们学习到的模型还不如基模型,很有可能我们的数据不存在任何线性关系
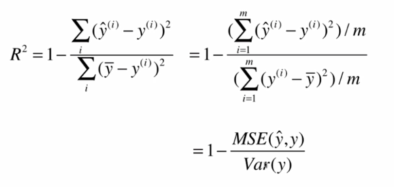
1.2分类模型性能评价及选择
给你一个癌症检测的数据集。你已经建好了分类模型,取得了96%的精度。为什么你还是不满意你的模型性能?你可以做些什么呢? https://zhuanlan.zhihu.com/p/43926232
衡量分类器的好坏?https://zhuanlan.zhihu.com/p/43088612
机器学习和统计里面的auc的物理意义是啥?https://zhuanlan.zhihu.com/p/43088612
1.2.1准确率 Accuracy
# same to accuracy print("score", KNN_classifier.score(X_test, y_test)) # must predict the result before use the function print("accuracy_score:",accuracy_score(y_test, y_predict))
1.2.2准确率悖论 Accuracy Paradox
这个图是我们用分类器模型预测出来的结果得到的准确率:

下面这个是我们用一个傻瓜式的分类,将所有的结果预测为0得到的精确度

1.2.3伪阳性和伪阴性 False Positive 和 False Negative
伪阳性(第一类错误):预测某类事情会发生但是实际并没有发生
伪阴性(第二类错误):预测某类事情不会发生但是实际发生
一般来说第二类错误比第一类错误严重得多。比如说艾滋病检测
你怎么理解第一类和第二类错误?https://zhuanlan.zhihu.com/p/44483185
1.2.4混淆矩阵 Confusion Matrix

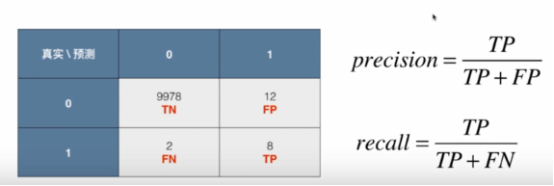
1.2.5精准率(查准率) Precision
有时候我们会更加注重精准率,比如说股票预测
Precison = TP/(TP+FP)
1.2.6召回率(查全率)Recall
有时候更加注重召回率,比如说病人诊断,比如说地震预测
Recall = TP/(TP+FN)
真阳性率和召回有什么关系?写出方程式。https://zhuanlan.zhihu.com/p/44200970
1.2.7 F1 Score
有些情况下并没有上面两个这么极端,我们希望能同时关注精准率和召回率,这种时候我们使用F1 score ,同时使用精准率和召回率。
F1 score使用的是precision和recall的调和平均值,调和平均值的特点是两者中有一个特别低整个值也就特别低,只有这两个都同时很高,结果才会很高
F1=2PR/(P+R)取值范围为(0,1)
1.2.8 AUC Area Under Curve
AUC 值为 ROC 曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器。
0.5 < AUC < 1,优于随机猜测。有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
注:对于AUC小于 0.5 的模型,我们可以考虑取反(模型预测为positive,那我们就取negtive),这样就可以保证模型的性能不可能比随机猜测差。
1.2.9 累计准确曲线 CAP Curve(ROC)
蓝色的曲线:使用随机模型联系客户
红色的曲线:使用模型预测概率之后有选择的联系客户
黑色的线:最好的曲线
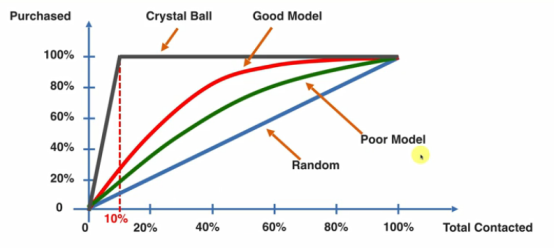
那么如何量化曲线的好与不好?
AR比值越接近1,说明模型的效果越好,比值越接近0,说明模型的效果越差
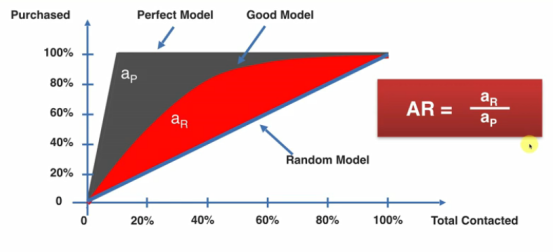
但是计算面积比较复杂,那如何用一个简单的方法去判断?
这个时候我们可以选择X轴的50%的点,去看y的值