一,浏览器的主要功能
就是向服务器发出请求,在浏览器窗口中展示您选择的网络资源,资源一般是指 HTML 文档,也可以是 PDF、图片或其他的类型。资源的位置由用户使用 URI(统一资源标示符)指定。
二,浏览器的组件

- 用户界面 - 包括地址栏、前进/后退按钮、书签菜单等。
- 浏览器引擎 - 在用户界面和呈现引擎之间传送指令。
- 呈现引擎 - 负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
- 网络 - 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
- 用户界面后端 - 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
- JavaScript 解释器。用于解析和执行 JavaScript 代码。
- 数据存储。这是持久层。浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5) 定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。
三,呈现引擎
/*渲染引擎主流程*/
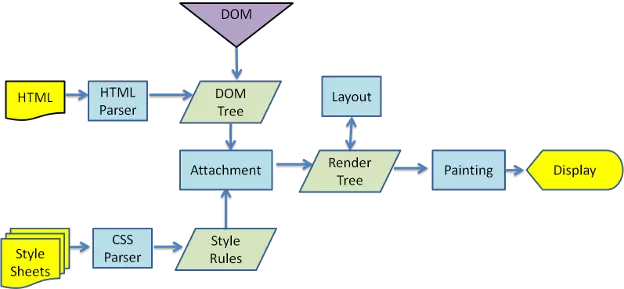
webkit 主流程
Mozilla 的 Gecko 呈现引擎主流程
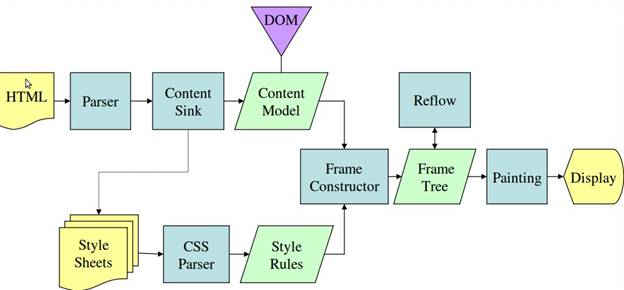
虽然 WebKit 和 Gecko 使用的术语略有不同,但整体流程是基本相同的。Gecko 将视觉格式化元素组成的树称为“框架树”。每个元素都是一个框架。WebKit 使用的术语是“呈现树”,它由“呈现对象”组成。对于元素的放置,WebKit 使用的术语是“布局”,而 Gecko 称之为“重排”。对于连接 DOM 节点和可视化信息从而创建呈现树的过程,WebKit 使用的术语是“附加”。有一个细微的非语义差别,就是 Gecko 在 HTML 与 DOM 树之间还有一个称为“内容槽”的层,用于生成 DOM 元素。
本文所讨论的浏览器——Firefox、Chrome和Safari是基于两种渲染引擎构建的,Firefox使用Geoko——Mozilla自主研发的渲染引擎,Safari和Chrome都使用webkit。
浏览器渲染引擎工作流程都差不多
呈现引擎一开始会从网络层获取请求文档的内容,内容的大小一般限制在 8k个块以内

解析 HTML 文档,逐个转化成DOM树。同时解析外部 CSS 文件以及样式元素生成CSSOM树。HTML 中这些带有视觉指令的样式信息将用于创建另一个树结构:呈现树(Render树)
呈现树包含多个带有视觉属性(如颜色和尺寸)的矩形。这些矩形的排列顺序就是它们将在屏幕上显示的顺序。
呈现树构建完毕之后,进入“布局”,为每个节点分配一个应出现在屏幕上的确切坐标。遍历呈现树,由用户界面后端层将每个节点绘制出来。
这是一个渐进的过程。不必整个 HTML 文档解析完毕之后,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,呈现引擎会将部分内容解析并显示出来。
Render树是DOM树和CSSOM树构建完毕才开始构建的吗?这三个过程在实际进行的时候又不是完全独立,而是会有交叉。会造成一边加载,一遍解析,一遍渲染的工作现象。
简而言之呢
- HTML解析成DOM树
- CSS解析成CSSOM树
- 两者结合成Render树
- Layout 根据Render Tree计算每个节点的信息
- Painting 根据计算好的信息绘制整个页面
这里面每一步都需要大量的工作,在传统的开发模式中,原生JS或JQ操作DOM时,浏览器会从构建DOM树,从头到尾执行一遍。
所以就有了虚拟DOM,将在下一篇文章总结虚拟DOM