Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。
该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。 在编写您的spider时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。
一旦熟悉了Scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
如果您安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。
我们强烈推荐您安装 IPython ,特别是如果您使用Unix系统(IPython 在Unix下工作的很好)。 详情请参考 IPython installation guide 。
启动终端
您可以使用 shell 来启动Scrapy终端:
<url> 是您要爬取的网页的地址。注意,这里我们只是进入到scrapy的shell调试里面,到进去以后,我们还可以用fetch(url)来获取其它你想要的网页内容。查看当前你这在看的是哪个网站,可以用response.url进行判断。
scrapy shell <url>
打印日志:
scrapy shell 'http://scrapy.org'
不打印日志:
scrapy shell 'http://scrapy.org' --nolog
使用终端
D:项目小项目scrapy_day6_httpbinhttpbin>scrapy shell "https://dig.chouti.com" --nolog
https://www.zhihu.com/captcha.gif?r=1512028381914&type=login
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x04E60090>
[s] item {}
[s] request <GET https://dig.chouti.com>
[s] response <200 https://dig.chouti.com>
[s] settings <scrapy.settings.Settings object at 0x04E60390>
[s] spider <DefaultSpider 'default' at 0x5a23f70>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
Scrapy终端仅仅是一个普通的Python终端(或 IPython )。其提供了一些额外的快捷方式。
可用的快捷命令(shortcut)
shelp()- 打印可用对象及快捷命令的帮助列表fetch(request_or_url)- 根据给定的请求(request)或URL获取一个新的response,并更新相关的对象view(response)- 在本机的浏览器打开给定的response。 其会在response的body中添加一个 <base> tag ,使得外部链接(例如图片及css)能正确显示。 注意,该操作会在本地创建一个临时文件,且该文件不会被自动删除。
打印当前请求的状态码:
>>> response
<200 https://dig.chouti.com>
>>> response.headers
{b'Date': [b'Thu, 30 Nov 2017 09:45:06 GMT'], b'Content-Type': [b'text/html; charset=UTF-8'], b'Server': [b'Tengine'], b'Content-Language': [b'en'], b'X-Via': [b'1.1 bd157:10 (Cdn Ca
che Server V2.0)']}
尝试我们的xpath表达式抽取内容
>>> sel.xpath('//a[@class="show-content color-chag"]/text()').extract_first()
'
t
【迅雷嘉奖维护公司利益员工 每人奖10万】11月30日讯,迅雷与迅雷大数据近日发生“内讧”,双方多次发布公告互相指责。对此,迅雷发布内部邮
件,嘉奖在关键时刻维护公司利益的5名员工,并给予每人10万元的奖励。
'
>>> sel.xpath('//a[@class="show-content color-chag"]/text()').extract_first().strip()
'【迅雷嘉奖维护公司利益员工 每人奖10万】11月30日讯,迅雷与迅雷大数据近日发生“内讧”,双方多次发布公告互相指责。对此,迅雷发布内部邮件,嘉奖在关键时刻维护公司利益的5名员工,并给予每
人10万元的奖励。'
这里也可以用css抽取
>>> sel.css('.part1 a::text').extract_first().strip()
'Netflix买下《白夜追凶》海外发行权,将在全球190多个国家和地区播出'
view就有意思了,它其实就是把下载的html保存。
>>> view(response)
True
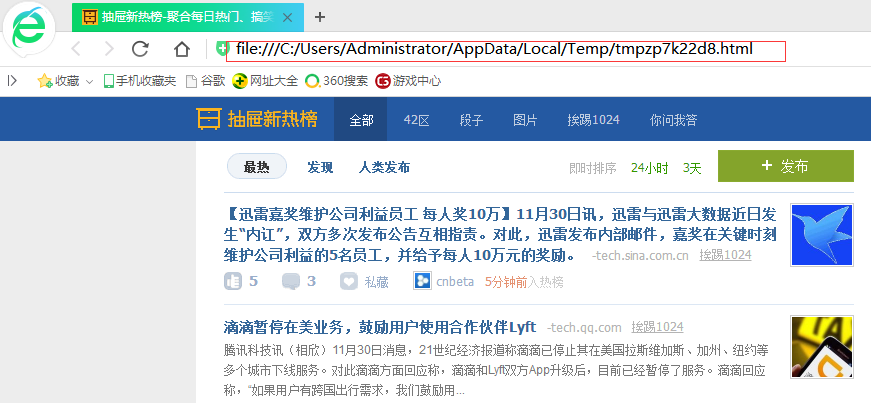
打印当前请求的url
>>> response.url
'https://dig.chouti.com'
但是这里我现在只能想到一个问题,那像是知乎这样类似的网站,单纯是提取就需要加上request的header信息,这怎么整,下面这么整就行。
1、首先我们需要from scrapy import Request,导入模块。
2、这里我们把请求到的内容赋值给data,我曾经单纯的想,这里我直接data.xpath和data.css就行,但是现实不行,data.url和headers是可以的,可查询内容就需要利用fetch(data)把请求结果,装换成response对象,这样的话我们直接用sel.xpath或者sel.css才能提取我们需要的信息。
>>> data = Request("https://www.taobao.com",headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
})
>>> fetch(data)
2017-11-30 22:24:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.taobao.com> (referer: None)
>>> response.url
'https://www.taobao.com'
>>> sel.xpath('/html/body/div[4]/div[1]/div[1]/div[1]/div/ul/li[1]/a[1]')
[<Selector xpath='/html/body/div[4]/div[1]/div[1]/div[1]/div/ul/li[1]/a[1]' data='<a href="https://www.taobao.com/markets/'>]
>>> sel.xpath('/html/body/div[4]/div[1]/div[1]/div[1]/div/ul/li[1]/a[1]').extract_first()
'<a href="https://www.taobao.com/markets/nvzhuang/taobaonvzhuang" data-cid="1" data-dataid="222887">女装</a>'
>>> data.headers
{b'User-Agent': [b'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'], b'Accept-Encoding': [b'gzip,deflate']}
3、仔细思考的同学会发现这个请求头里面只有我们提交的浏览器类型信息,其它什么都没有,而shell自带的header里面内容要很多。
>>> data.headers
{b'User-Agent': [b'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'], b'Accept-Encoding': [b'gzip,deflate']}
>>> response.headers
{b'Timing-Allow-Origin': [b'*'], b'Eagleid': [b'7583cc6515120518627751757e'], b'Age': [b'48'], b'Cache-Control': [b'max-age=0, s-maxage=90'], b'X-Cache': [b'HIT TCP_MEM_HIT dirn:-2:-
2 mlen:-1'], b'Vary': [b'Accept-Encoding', b'Ali-Detector-Type, X-CIP-PT'], b'Server': [b'Tengine'], b'Content-Type': [b'text/html; charset=utf-8'], b'X-Swift-Cachetime': [b'90'], b'
Set-Cookie': [b'thw=cn; Path=/; Domain=.taobao.com; Expires=Fri, 30-Nov-18 14:24:22 GMT;'], b'Via': [b'cache10.l2cn416[351,200-0,M], cache29.l2cn416[352,0], cache1.cn338[0,200-0,H],
cache6.cn338[0,0]'], b'Strict-Transport-Security': [b'max-age=31536000'], b'X-Swift-Savetime': [b'Thu, 30 Nov 2017 14:23:34 GMT'], b'Date': [b'Thu, 30 Nov 2017 14:24:22 GMT']}