有这么一张表:
create table hy_testtime( id number(6,0) not null primary key, name nvarchar2(20) not null, utime timestamp(6) )
如果这样给它充值:
insert into hy_testtime select rownum, dbms_random.string('*',dbms_random.value(1,20)), sysdate from dual connect by level<100 commit;
那么充值完毕后,其utime字段都会是一样的.(SQL:select to_char(utime,'yyyy-mm-dd hh24:mi:ss.ff6') from hy_testtime)
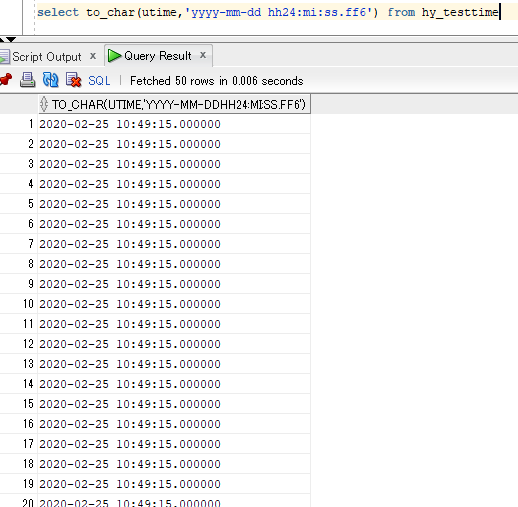
然后,用传统的反连接找utime最新的记录,会把所有99条结果都找出来.
select count(*) from hy_testtime a where not exists (select null from hy_testtime b where b.utime>a.utime)
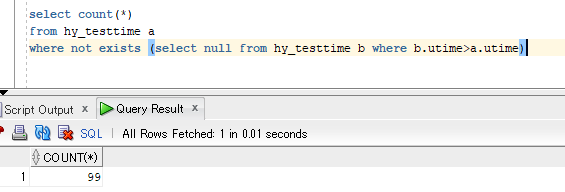
这就不是我们期待的一条记录了.
让我们换一张表:
create table hy_testtime2( id number(6,0) not null primary key, name nvarchar2(20) not null, utime timestamp(6) )
这样给它充值:
insert into hy_testtime2 select rownum, dbms_random.string('*',dbms_random.value(1,20)), systimestamp from dual connect by level<100
这回换用了systimestamp,但时间还是一样的.
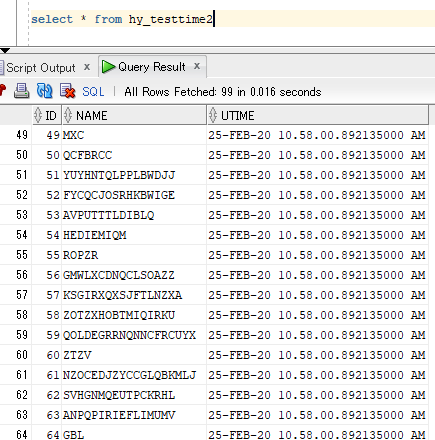
这当然还不是我们想要的.于是我们用以下更新语句去更新:
update hy_testtime2 set utime=systimestamp where id<10; commit;
再查一下:
select to_char(utime,'yyyy-mm-dd hh24:mi:ss.ff6') from hy_testtime2 where id<10
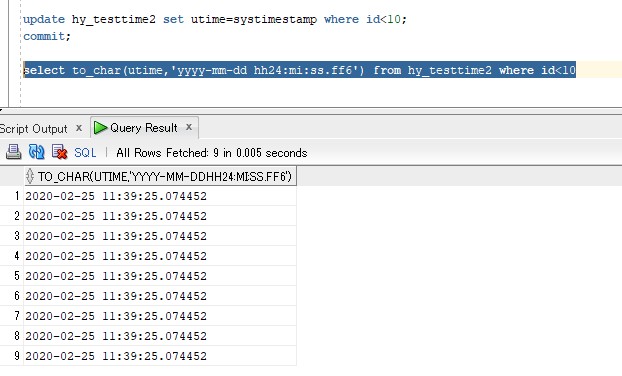
看来,只要批量更新,就会造成utime是一样的结果.
但我们去一条条更新,如下所示:
update hy_testtime2 set utime=systimestamp where id=11; update hy_testtime2 set utime=systimestamp where id=12;
然后再查查:
select to_char(utime,'yyyy-mm-dd hh24:mi:ss.ff6') from hy_testtime2 where id in(11,12)
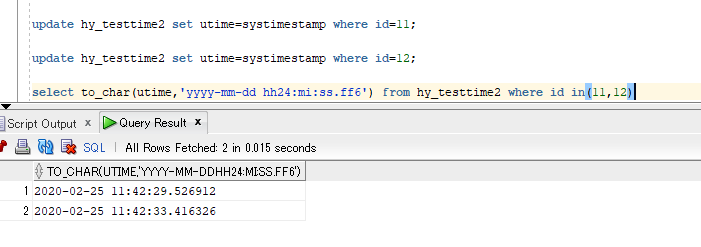
这就可以发现更新时间是不一致了.
然后再查一下utime最新记录有几条:
select count(*) from hy_testtime2 a where not exists (select null from hy_testtime2 b where b.utime>a.utime)

再看看是否是id=12的那条:
select a.* from hy_testtime2 a where not exists (select null from hy_testtime2 b where b.utime>a.utime)
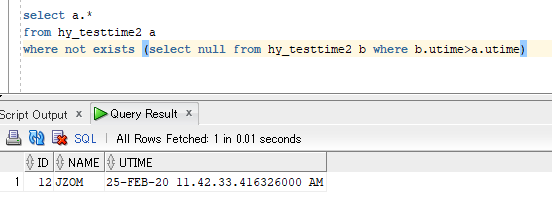
果然是.
结论: 如果是批量更新timestamp字段,那更新上去的值必然一致,无论是用sysdate还是systimestamp都是一样.
如果要拉开时间,必须一条条去更新,如果不是取Oracle的systimestamp,那么使用Java中的Timsstamp类保证精度也是一样效果.
当然,在并行环境里,utime字段还有可能会重复! 这时可行方案是发现重复再取一次时间,再设置回去. 流程是:更新utime,检查utime有无重复,发现重复则再次更新utime.
参考资料:http://www.itpub.net/thread-1931266-4-1.html
--2020-02-25--