ElasticSearch

全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
概念
Elastic会索引所有字段,查询就是查索引。
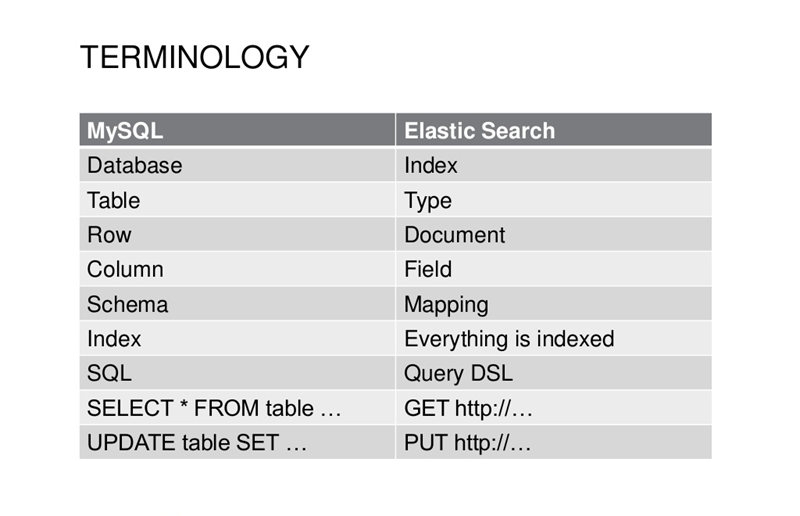
1,索引(Index)是Elastic数据管理的顶层单位,一个索引就是一个数据库。索引名称必须小写。
2,Index 里的记录称为文档(Document),多条Document组成一个Index,Document是Json格式。
3,Document文档可以分组(Type),是虚拟的逻辑分组,用来过滤Document
实操
0,
显示所有Index:curl -X GET 'http://localhost:9200/_cat/indices?v'
显示所有Type:curl 'localhost:9200/_mapping?pretty=true'
1,
新建Index,向Elastic服务器发送PUT请求,名为weather:curl -X PUT 'localhost:9200/weather'
删除Index,发送DELETE请求:curl -X DELETE 'localhost:9200/weather'
2,
新增记录,向指定Index/Type发请求:
# 向accounts索引Type组中新增记录
# 方式一:发送PUT请求,要指定该条记录的ID,下例中为1,ID不一定是数字,任何字符串都可以。
curl -X PUT 'localhost:9200/accounts/person/1' -H 'Content-Type: application/json' -d '
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}'
# 方式二:发送POST请求,ID会随机创建,和方式一等价。
curl -X POST 'localhost:9200/accounts/person' -H 'Content-Type: application/json' -d '
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}'
删除记录,发送DELETE请求,删除accounts索引person组中ID等于1的记录:curl -X DELETE 'localhost:9200/accounts/person/1'
更新记录,发送PUT请求,更新ID等于1的记录:
curl -X PUT 'localhost:9200/accounts/person/1' -H 'Content-Type: application/json' -d '
{
"user" : "张三",
"title" : "工程师",
"desc" : "数据库管理,软件开发"
}'
# 更新返回的数据中,该记录version从1变为2,记录更新次数
查看记录,发送GET请求,accounts索引person分组ID为1的记录:
curl 'localhost:9200/accounts/person/1?pretty=true'
# pretty=true以易读的格式返回。ID不存在就查不到数据。
3,
数据查询
查询所有记录,GET请求:
curl 'localhost:9200/accounts/person/_search'
# response中:took表示耗时(毫秒)、time_out表示是否超时、hits表示命中的记录
全文搜索
# 查询accounts索引person组的记录,条件是desc字段包含”软件“二字
curl 'localhost:9200/accounts/person/_search' -H 'Content-Type: application/json' -d '
{
"query" : { "match" : { "desc" : "软件" }}
}'
# Elastic默认返回10条记录,size字段可设置返回记录条数,from字段表示位移,从哪个位置开始,默认从0开始
#{
# "query" : { "match" : { "desc" : "软件" }},
# "from": 1,
# "size": 5
#}
逻辑运算
有多个条件,默认or
# 软件 or 系统
curl 'localhost:9200/accounts/person/_search' -H 'Content-Type: application/json' -d '
{
"query" : { "match" : { "desc" : "软件 系统" }}
}'
要执行and,必须使用布尔查询
# 软件 and 系统
curl 'localhost:9200/accounts/person/_search' -H 'Content-Type: application/json' -d '
{
"query": {
"bool": {
"must": [
{ "match": { "desc": "软件" } },
{ "match": { "desc": "系统" } }
]
}
}
}'
Python API
虽然 Elasticsearch 提供了一系列 Restful API 来进行存取和查询操作,我们可以使用 curl 等命令来进行操作,但毕竟命令行模式没那么方便,Python 中利用 elasticsearch 包来对接 Elasticsearch 的相关方法。
pip install elasticsearch -i https://pypi.douban.com/simple
示例:
from datetime import datetime
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
class MyElastic:
def __init__(self, index, type):
self.index = index
self.type = type
self.es = Elasticsearch()
def create_index(self):
'''
创建索引、映射
:return:
'''
_index_mappings = {
"mappings": {
# self.type: {
"properties": {
"title": {
"type": "text", # text表分词
"index": True, # 控制当前字段是否索引,默认为true,即记录索引,false不记录,即不可搜索.当身份证号和手机号这样的敏感信息被搜索的时候,可以设置为false,这样就可以不用建立倒排索引节省空间
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"data": {
"type": "date"
},
"key_word": {
"type": "keyword", # keyword表不分词
},
"source": {
"type": "text",
"index": True,
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"link": {
"type": "keyword",
}
}
# }
}
}
if not self.es.indices.exists(index=self.index):
res = self.es.indices.create(index=self.index, body=_index_mappings)
print(res)
else:
print(f'{self.index}已存在')
def insert(self, data):
"""
插入数据
:param data: 插入的数据, [{}, {}]
:return:
"""
for x in data:
res = self.es.index(index=self.index, doc_type=self.type, body=x)
print(res)
def insert_by_bulk(self):
'''
用bulk批量插入
:return:
'''
data = [
{"date": datetime.now(),
"source": "慧聪网",
"link": "http://info.broadcast.hc360.com/2017/09/130859749974.shtml",
"keyword": "电视",
"title": "付费 电视 行业面临的转型和挑战"
},
{"date": datetime.now(),
"source": "中国文明网",
"link": "http://www.wenming.cn/xj_pd/yw/201709/t20170913_4421323.shtml",
"keyword": "电视",
"title": "电视 专题片《巡视利剑》广获好评:铁腕反腐凝聚党心民心"
},
{"date": datetime.now(),
"source": "人民电视",
"link": "http://tv.people.com.cn/BIG5/n1/2017/0913/c67816-29533981.html",
"keyword": "电视",
"title": "中国第21批赴刚果(金)维和部隊启程--人民 电视 --人民网"
}
]
actions = []
for x in data:
actions.append({
'_index': 'accounts',
'_type': '_doc',
# '_id': id, # 随机生成
'_source': {
"date": x['date'],
"source": x['source'],
"link": x['link'],
"keyword": x['keyword'],
"title": x['title']
}
})
ans = bulk(self.es, actions, index=self.index, raise_on_error=True)
print(ans)
def delete_by_id(self, id):
"""
通过ID删除
:return:
"""
res = self.es.delete(index=self.index, doc_type=self.type, id=id)
print(res)
def delete_by_body(self, body):
"""
通过body删除
:return:
"""
# 删除满足条件的数据
ans = self.es.delete_by_query(index=self.index, doc_type=self.type, body=body)
print(ans)
def update_by_id(self, id, body):
"""
通过ID更新
:return:
"""
# 与插入方法一样,数据存在就更新,不存在就执行插入
res = self.es.index(index=self.index, doc_type=self.type, id=id, body=body)
print(res)
def query_by_id(self, id):
"""
通过ID查询
:return:
"""
# 根据ID查询
ans = self.es.get(index=self.index, doc_type=self.type, id=id)
print(ans)
def query_by_body(self, body):
"""
通过body查询
:return:
"""
# body = {
# "query": {
# "bool": { # 布尔查询
# "must": {"match": {"last_name": "smith"}
# },
# "filter": { # 过滤器
# "range": {
# "age": {"gt": 30}
# }
# }
# }
# }
# }
res = self.es.search(index=self.index, doc_type=self.type, body=body)
print(res)
# 以下全部是查询操作
def query_anything(self):
"""
matchmulti_match erm erms复合查询bool切片式查询
angeprefix前缀查询wildcard通配符查询
排序度量类聚合:最大值最小值求和平均值
:return:
"""
# # match: 匹配name包含python关键字的数据
# body = {
# "query":{
# "match":{
# "name":"python"
# }
# }
# }
# # multi_match: 在name和addr里匹配包含深圳关键字的数据
# body = {
# "query": {
# "multi_match": {
# "query": "深圳",
# "fields": ["name", "addr"]
# }
# }
# }
# # term: 查询name="python"的所有数据
# body = {
# "query": {
# "term": {
# "name": "python"
# }
# }
# }
# # terms: 搜索出name="python"或name="android"的所有数据
# body = {
# "query": {
# "terms": {
# "name": [
# "python", "android"
# ]
# }
# }
# }
# 复合查询bool
# bool有3类查询关系,must(都满足), should(其中一个满足), must_not(都不满足)
# # 获取name="python"并且age=18的所有数据
# body = {
# "query": {
# "bool": {
# "must": [
# {
# "term": {
# "name": "python"
# }
# },
# {
# "term": {
# "age": 18
# }
# }
# ]
# }
# }
# }
# # 切片式查询: 从第2条数据开始,获取4条数据
# body = {
# "query": {
# "match_all": {}
# }
# "from": 2 # 从第二条数据开始
# "size": 4 # 获取4条数据
# }
# # range范围查询: 查询18<=age<=30的所有数据
# body = {
# "query": {
# "range": {
# "age": {
# "gte": 18, # >=18
# "lte": 30 # <=30
# }
# }
# }
# }
# # prefix前缀查询: 查询前缀为"赵"的所有数据
# body = {
# "query": {
# "prefix": {
# "name": "p"
# }
# }
# }
# # wildcard通配符查询: 查询name以id为后缀的所有数据
# body = {
# "query": {
# "wildcard": {
# "name": "*id"
# }
# }
# }
# # 排序
# body = {
# "query": {
# "match_all": {}
# }
# "sort": {
# "age": { # 根据age字段升序排序
# "order": "asc" # asc升序,desc降序
# }
# }
# }
# # 度量类聚合
# # 最小值: 搜索所有数据,并获取age最小的值
# body = {
# "query": {
# "match_all": {}
# },
# "aggs": { # 聚合查询
# "min_age": { # 最小值的key, 名字可自定义
# "min": { # 最小
# "field": "age" # 查询"age"的最小值
# }
# }
# }
# }
# # 最大值: 搜索所有数据,并获取age最大的值
# body = {
# "query": {
# "match_all": {}
# },
# "aggs": { # 聚合查询
# "max_age": { # 最大值的key, 名字可自定义
# "max": { # 最大
# "field": "age" # 查询"age"的最大值
# }
# }
# }
# }
# # 获取和: 搜索所有数据,并获取所有age的和
# body = {
# "query": {
# "match_all": {}
# },
# "aggs": { # 聚合查询
# "sum_age": { # 和的key, 名字可自定义
# "sum": { # 和
# "field": "age" # 获取所有age的和
# }
# }
# }
# }
# # 获取平均值: 搜索所有数据,获取所有age的平均值
# body = {
# "query": {
# "match_all": {}
# },
# "aggs": { # 聚合查询
# "avg_age": { # 平均值的key, 名字可自定义
# "sum": { # 平均值
# "field": "age" # 获取所有age的平均值
# }
# }
# }
# }
# # filter_path表示过滤字段,只需要获取_id数据,多个条件用逗号隔开,获取所有数据hits.hits._*
# ans = self.es.search(index=self.index, doc_type=self.type, filter_path=["hits.hits._id", "hits.hits._source"])
# print(ans)
# count获取数据量
ans = self.es.count(index=self.index, doc_type=self.type)
print(ans)
my_elastic = MyElastic(index='accounts', type='_doc')
# my_elastic.create_index()
data = [
{"date": datetime.now(),
"source": "慧聪网",
"link": "http://info.broadcast.hc360.com/2017/09/130859749974.shtml",
"keyword": "电视",
"title": "付费 电视 行业面临的转型和挑战"
},
{"date": datetime.now(),
"source": "中国文明网",
"link": "http://www.wenming.cn/xj_pd/yw/201709/t20170913_4421323.shtml",
"keyword": "电视",
"title": "电视 专题片《巡视利剑》广获好评:铁腕反腐凝聚党心民心"
}
]
# my_elastic.insert(data=data)
# my_elastic.insert_by_bulk()
# my_elastic.query_by_id('zEMe7XEB7qhcu-1hh9aI')
body = {
"query": {
"match": {
"source": "慧聪 网" # or
},
}
}
# my_elastic.query_by_body(body)
body = {
"date": datetime.now(),
"source": "博客网",
"link": "https://cn.blog.com",
"keyword": "博客园",
"title": "修改修改修改"
}
# my_elastic.update_by_id(id='00Mn7XEB7qhcu-1hUdb0', body=body)
# my_elastic.delete_by_id('zUMe7XEB7qhcu-1hh9aI')
body = {
'query': {
'match': {
'keyword': '电视'
}
}
}
# my_elastic.delete_by_body(body)
# 以下全部是查询操作
my_elastic.query_anything()
ICP的mappings
{
"settings": {
"analysis": {
"analyzer": {
"domain_name_analyzer": {
"type": "custom",
"tokenizer": "domain_name_tokenizer",
"filter": [
"lowercase"
]
}
},
"tokenizer": {
"domain_name_tokenizer": {
"type": "path_hierarchy",
"delimiter": ".",
"reverse": true
}
}
}
},
"mappings": {
"_meta": {
"icp_version_mapping": "1.0"
},
"properties": {
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"update_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"domain": {
"type": "text",
"analyzer": "domain_name_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"sponsor": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"sponsor_type": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"icp_number": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"icp_audited": {
"type": "date"
},
"icp_updated": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"restrict": {
"type": "boolean"
},
"site_index": {
"type": "text",
"analyzer": "domain_name_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"site_name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"city": {
"type": "keyword"
},
"region": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
主域名的mappings:
{
"settings": {
"analysis": {
"analyzer": {
"domain_name_analyzer": {
"type": "custom",
"tokenizer": "domain_name_tokenizer",
"filter": [
"lowercase"
]
}
},
"tokenizer": {
"domain_name_tokenizer": {
"type": "path_hierarchy",
"delimiter": ".",
"reverse": true
}
}
}
},
"mappings": {
"_meta": {
"domains_version_mapping": "1.0"
},
"properties": {
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"update_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"name": {
"type": "text",
"analyzer": "domain_name_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"national_level": {
"type": "boolean"
},
"source": {
"type": "keyword"
}
}
}
}
测试的
_index_mappings = {
"settings": {
"analysis": {
"analyzer": {
"domain_name_analyzer": { # 自定义analyzer: domain_name_analyzer
"type": "custom",
"tokenizer": "domain_name_tokenizer", # 使用自定义的tokenizer
"filter": ["lowercase"] # token过滤器,对token规范化
}
},
"tokenizer": {
"domain_name_tokenizer": { # 自定义analyzer: domain_name_tokenizer
"type": "path_hierarchy", # 路径层次结构
"delimiter": ".", # 分隔符
"reverse": True # 反转,以最符合的顺序返回,搜索nyist.edu.cn, 反转前 [nyist, nyist.edu, nyist.edu.cn]),
# 翻转后 [nyist.edu.cn, nyist.edu, nyist]
}
}
}
},
"mappings": {
"_meta": { // 自定义的元数据
"bs_domain_version_mapping": "1.0"
},
"properties": {
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"update_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"name": {
"type": "text",
"analyzer": "domain_name_analyzer",
// "search_analyzer": "ik_max_word",
"fields": { // ES允许同一个字段有两个不同的类型, name字段可以用作全文检索, name.keyword可以用作排序或聚合
"keyword": {
"type": "keyword"
}
}
},
"city": {
"type": "keyword" // keyword表不分词
},
"region": {
"type": "keyword"
},
"icp_number": {
"type": "keyword"
},
"icp_source": {
"type": "keyword"
},
"sponsor": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"sponsor_type": {
"type": "keyword"
},
"national_level": {
"type": "boolean"
},
"tags": {
"type": "keyword" # 写成数组类型即可:["学校", "政府"]、["学校"]、[]
// "type": "nested"
},
"recycler": {
"type": "boolean"
},
"unit_id": {
"type": "keyword"
},
"unit_name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}