验证码是一个很有趣的问题,其目的是谁是一个人或机器输入来区分,这个问题的实质是一个图灵测试(推荐电影《模仿游戏》),验证码是一种简单而有效的验证方法,由CMU在教授2000在有关创建。后来这头牛谁又将收集零星验证码,转化成巨大的生产力。上千万篇纸质文章数字化,眼下,Google还用其识别门牌号。路牌等(一个神人创造了验证码。又让验证码做出了巨大贡献)。更有甚者。想将验证码作为广告宣传栏(考虑到题库的建立成本和题量的有限性。我认为不可行)。12306昨天改用了图形验证码,而其实,图形验证码已经不是新奇事了。早在几个月钱,Google就换成了图形验证(谷歌让验证码更简单)。图片例如以下:

再看看咱们12306的图片验证码:




Note: 假设选错了。2s钟后。才干再试。并且图片已经换了。只是能够试N次。
12306图形验证码的若干特点
1. 文字+图像双重验证



图形这一关特点非常多。容后细说。文字这一关相对于单纯的文字验证码,难度系数下降了非常多,基本上仅仅有字体、加粗、大小、位置的变化。总得来说。对于这类无扭曲(易识别),重叠较小(易切割),背景单一(易二值化),的中文印刷体(易识别)来说。识别算法已经非常成熟了。这一点。相信大家都见过了OCR软件的强大识别功能。此外。这里的文字并非孤立的,必然是一个名词,这又能够进一步提高识别率。因此。想破解这一关还是比較轻松的。
2. 图片非常熟悉
比方贺卡、雕像、贝壳、玻璃瓶、擀面杖、热气球等,大多数是日常生活中能见到的。
这就决定了类别不会太多。
眼下。ImageNet(图像识别眼下最大的数据库) 总的标记数为21841类。考虑到常见性。12306的类别数目应该不会高于这个数(我认为应该远低于这个数)。日后应该添加类别数目的可能性并不大,这就使得这个问题的分类规模不会特别大。可是,扩充每一类的数目是必定的。
3. 数据库取自互联网
12306的数据标记取自互联网。也就是说对于"篮球",12306可能直接在谷歌/百度里面搜索"篮球"。然后将得到的图片加到数据库。
这样做原因有两点。首先,12306须要海量标记数据,假设数据库太少。那么破解软件全然能够搜集这些数据。进行对照。这就好比我们得到了老师的题库,无论老师怎么出题,我都能够从容应对。
其次,12306自己採集图像。自己标记的成本太大,考虑到数据库还须要不断更新,日后的维护成本也太高。当前,对于图像检測领域的学术研究,其数据库的标记也有非常多直接取自互联网。使用互联网图片和标记固然方便,然而,这也会给破解带来便利,所谓"成也萧何败萧何",由于能够直接使用互联网数据来辅助破解,无疑,这会是12306最大的软肋。以下来两个栗子:
Google图像检索

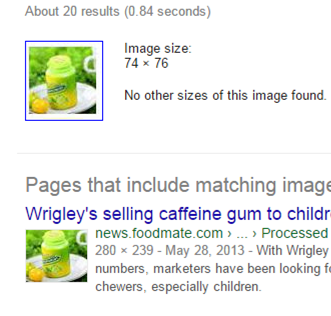
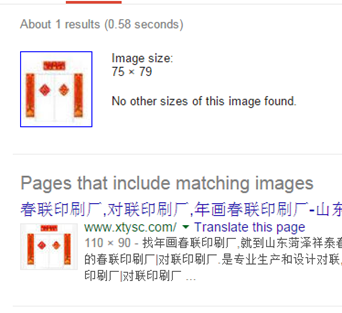
比如,抢票软件能够在谷歌中搜索图像,然后得到链接的标题,再将标题与要找的文本匹配,比方上面样例中的"春联"。这就变成了一个文本查找的小问题了,根本不须要识别。于是识别问题就转化成为图像检索和文本匹配问题。假设12306不正确图像进行处理,直接照搬原图,那么抢票软件能够轻而易举地检索到原图,文本匹配更不用说。
当然这样的做法的网络流量和时间消耗太大(接近1×8 s),这样的抢票软件预计造出来了,也是难以应用的。因此。抢票软件可能更倾向于本地化库。
百度搜索"手铐"



既然类别不是非常多,并且类别固定,那么破解软件相同能够利用标记在互联网搜索图片。然后建立自己的图像库。
这样的思路对于12306来说,个人觉得威胁非常大!仅仅要抢票软件的库够全,那么就能够用图像检索的方法检索本地库,比如上图中,图像是全然匹配。当然。这就须要抢票软件的数据库与12306的库相同丰富,并且还要与12306同步更新。个人感觉这样的思路比較累。并且比較死板,假设12306对图像进行一些处理,比方局部裁剪,都会影响到检索的精度。
其实,即使抢票软件的库没有12306的全面。甚至与12306包括的图像不一致,都没有太大关系。由于还能够用机器学习的方法化为分类识别问题,分类器具有非常强的泛化能力。比如。破解软件对每一类训练一个分类器,比方专门训练一个手铐的分类器。然后对这8张图片分类就好了,一般来说,二分类的分类效果非常精准。当然也能够直接用多分类器。比方CNN/DNN,如今深度学习的分类结果也还能够。这里给大家一个链接。只是,全然用识别的思路来做,准确性肯定达不到,由于这须要计算机具有人脑一样的视觉、概念理解能力。
总之,12306这样做也确属无奈之举,自己採集,标记图像建库,更新库的成本太高,互联网这片海洋尽管宽广,却是公海。
4. 一般仅仅要选两个
按理说。为了尽可能地添加不确定性,同一组中属于同一类的数目能够取1。2,3,….。8,只是,实际上考虑到用户感受,数目应该不会超过3个,否则用户会骂娘的……。即使是3个。非常多人也会不乐意的,而1个太少。顶多猜8次,2个就有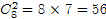 种情况。蒙中的概率就比較低了,所以我猜大多数情况下是仅仅有2个属于同一类,而极少部分情况下有仅仅有1个或者有3个,相信日后再怎么变。这个设置应该是不会变的。这就给破解带来了非常大的便利,由于大多数情况下,破解的时候根本不须要知道要找的类别是什么,都不须要识别文本,仅仅须要找到那两张图片最相似的图片就能够了。因此这就转换成一个相似性匹配的问题了(方法非常多。比方最简单的灰度直方图匹配。灰度不够再加梯度方向呀,考虑旋转性再找主方向呀….)。
种情况。蒙中的概率就比較低了,所以我猜大多数情况下是仅仅有2个属于同一类,而极少部分情况下有仅仅有1个或者有3个,相信日后再怎么变。这个设置应该是不会变的。这就给破解带来了非常大的便利,由于大多数情况下,破解的时候根本不须要知道要找的类别是什么,都不须要识别文本,仅仅须要找到那两张图片最相似的图片就能够了。因此这就转换成一个相似性匹配的问题了(方法非常多。比方最简单的灰度直方图匹配。灰度不够再加梯度方向呀,考虑旋转性再找主方向呀….)。
5. 每一组图像的生成。可能用到了相似性


比如热水瓶和轿子非常相似,手机壳和这一组有非常多矩形。显然。这会给相似性比对以及识别带来不小的干扰。
6. 每一组中可能有多类都有多张图片


比如第一张图片,除了充电器外。还有2张西服,第二张图片除了螺丝刀之外。还有3张月饼。显然。这是为了应对第4点的局限而加的干扰,显然这种干扰并不会带来多少困难,比方。第一张有2类都有2张,那么每次猜对的概率为50%。大不了有4类,每类2张,概率也高达25%。尽管用4类的不确定性更大,但这种特殊的条件设置,又会给识别带来便利,所以一般也就仅仅有1-2类吧(这部分不够严谨)。
今日。360表示他们已经成功破解,并且,抢票成功率提升了200%……。速度之快,令人咂舌,不禁令人感叹,道高一尺、魔高一丈呀。只是,12306也才刚刚使用图形验证码,这种方法还有非常多能够变通的地方(比方对图片进行适当旋转、变形等处理,而不是直接用互联网原图),总之,12306还有非常多招数能够用。抢票软件能接住第一招。并不代表兴许招数也能轻易接住。并且。我预计抢票软件这次接得有些投机取巧(我认为是用图像检索的方法),真正要解决好这个问题,必然要用机器学习(百度、谷歌本质上也是用机器学习),而这是一个还在研究并且还须要长期研究的问题,否则LSVRC (Large Scale Verification code Recognition Competition)这类挑战赛就能够休矣。
最后来个轻松的话题,无论如何。12306为推广汉字以及科普常识作出了巨大贡献,比方,我之前就不知道牌坊长啥样,这不禁让我想起来我5岁进学前班的情景,那老师认为我太小,想考考我的智商,于是拿出一本画冊,要我指出哪个是老虎、哪个是大象……,如今认为这哪里是考智商呀,分明看我是不是一个喜欢看动画片的孩子嘛!
版权声明:本文博主原创文章,博客,未经同意不得转载。